The Apple Watch Review
by Joshua Ho & Brandon Chester on July 20, 2015 8:00 AM EST- Posted in
- Wearables
- Apple
- Mobile
- Apple Watch
Apple S1 Analysis
One of the biggest issues with the smartwatch trend that I’ve seen is that as a result of most companies entering the market with smartphone backgrounds, we tend to see a lot of OEMs trying to shove smartphone parts into a smartwatch form factor. There have been a lot of different Android Wear watches, but for the most part everything seems to use Qualcomm’s Snapdragon 400 without the modem. Even though A7 is relatively low power for a smartphone, it’s probably closer to the edge of what is acceptable in terms of TDP for a smartwatch. Given that pretty much every Android Wear watch has around a 400 mAh battery at a 3.8 or 3.85 volt chemistry to attempt to reach 1-2 days of battery life and a relatively large PCB, the end result is that these smartwatches are really just too big for a significant segment of the market. In order to make a smartwatch that can scale down to sizes small enough to cover most of the market, it’s necessary to make an SoC specifically targeted at the smartwatch form factor.

Capped Apple S1 SoC (Image Courtesy iFixit)
The real question here is what Apple has done. As alluded to in the introduction, it turns out the answer is quite a bit. However, this SoC is basically a complete mystery. There’s really not much in the way of proper benchmarking tools or anything that can be run on the Watch to dig deeper here. Based on teardowns, this SoC is fabricated on Samsung’s 28nm LP process, although it’s not clear which flavor of LP is used. It’s pretty easy to eliminate the high power processes, so it’s really just a toss-up between HKMG and poly SiON gate structure. For those that are unfamiliar with what these terms mean, the main difference that results from this choice is a difference in power efficiency, as an HKMG process has less leakage power. Given how little cost is involved in this difference in process compared to a move to 20/14nm processes, it’s probably a safe bet that Apple is using an HKMG process here especially when we look at how the move from 28LP to 28HPm at TSMC dramatically affected battery life in the case of SoCs like Snapdragon 600 and 800.

Decapped & Labeled S1 SoC (Image Courtesy ABI Research)
We also know that binaries compiled for the watch target ARMv7k. Unfortunately, this is effectively an undocumented ISA. We know that Watch OS is built on iOS/Darwin, so this means that a memory management unit (MMU) is necessary in order to make it possible to have memory protection and key abstractions like virtual memory. This rules out MCU ISAs like ARMv7m even if it's possible to add an MMU to such an architecture, so it’s likely that we’re looking at some derivative of ARMv7-A, possibly with some unnecessary instructions stripped out to try and improve power consumption.
The GPU isn’t nearly as much of a mystery here. Given that the PowerVR drivers present in the Apple Watch, it’s fairly conclusive that the S1 uses some kind of PowerVR Series 5 GPU. However which Series 5 GPU is up to debate. There are reasons to believe it may be a PowerVR SGX543MP1, however I suspect that it is in fact PowerVR's GX5300, a specialized wearables GPU from the same family as the SGX543 and would use a very similar driver. Most likely, dedicated competitive intelligence firms (e.g. Chipworks) know the answer, though it's admittedly also the kind of information we expect they would hold on to in order to sell it to clients as part of their day-to-day business activities.
In any case, given that native applications won’t arrive until WatchOS 2 is released I don’t think we’ll be able to really do much in the way of extensive digging on what’s going on here as I suspect that graphics benchmarks will be rare even with the launch of WatchOS 2.
Meanwhile, after a lot of work and even more research, we're finally able to start shining a light on the CPU architecture in this first iteration of Apple's latest device. One of the first things we can start to look at is the memory hierarchy, which is information crucial to applications that require optimization to ensure that code has enough spatial and/or temporal locality to ensure that code is performant.
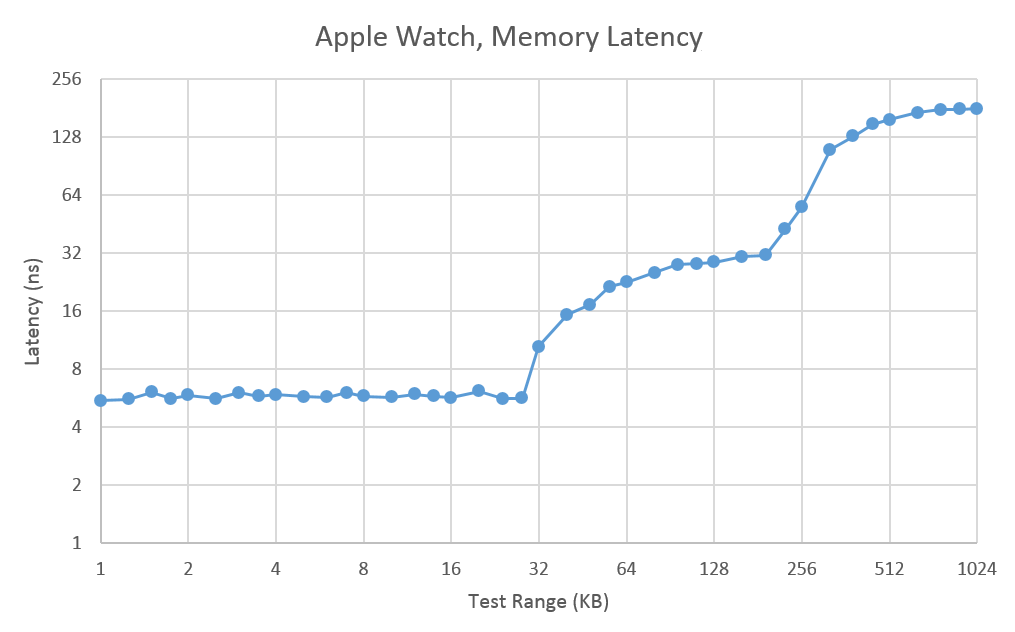
As one can see, there’s a pretty dramatic fall-off that happens between 28 and 64KB of “DRAM”, as we exit the local maximum of L1 data cache, so we can safely bet that the L1 data cache size is 32KB given current shipping products tend to fall somewhere between 32 and 64KB of L1 data cache. Given the dramatic fall-off that begins to happen around 224KB, we can also safely bet that we’re looking at a 256KB L2 combined cache which is fairly small compared to the 1-2MB shared cache that we might be used to from today’s large smartphone CPUs, but compared to something like an A5 or A7 it’s about right.
If Apple had just implemented the Cortex A7 as their CPU of choice, the obvious question at this point is whether they’ve really made anything “original” here. To try and dive deeper here, we can start looking past the memory hierarchy and looking closer at the machine itself. One of the first things that is obvious is that we’re looking at a CPU with a maximum frequency of 520 MHz, which is telling of the kind of maximum power that Apple is targeting here.
| Apple S1 CPU Latency and Throughput | ||||
| Instruction | Throughput (Cycles/Result) | Latency (Cycles/Result) | ||
| Loads (ldr reg,[reg]) | 1 | N/A | ||
| Stores (str reg,[reg]) | 1 | N/A | ||
| Move (mov reg, reg) | 1/2 | - | ||
| Integer Add (add reg, reg, imm8) | 1/2 | - | ||
| Integer Add (add reg,reg,reg) | 1 | 1 | ||
| Integer Multiply (mul reg,reg,reg) | 1 | 3 | ||
| Bitwise Shift (lsl reg,reg) | 1 | 2 | ||
| Float Add (vadd.f32 reg,reg,reg) | 1 | 4 | ||
| Double Add (vadd.f64 reg,reg,reg) | 1 | 4 | ||
| Float Multiply (vmul.f32 reg,reg,reg) | 1 | 4 | ||
| Double Multiply (vmul.f64 reg,reg,reg) | 4 | 7 | ||
| Double Divide (vdiv.f64 reg,reg,reg) | 29 | 32 | ||
Obviously, talking about the cache hierarchy isn’t enough, so let’s get into the actual architecture. On the integer side of things, integer add latency is a single cycle, but integer multiplication latency is three cycles. However, due to pipelining integer multiplication throughput can produce a result every clock cycle. Similarly, bitshifts take two cycles to complete, but the throughput can be once per clock. Attempting to interleave multiplies and adds results in only achieving half the throughput. We can guess that this is because the integer add block and the integer multiply block are the same block, but that doesn’t really make sense because of just how different addition and multiplication are at the logic level.
Integers are just half of the equation when it comes to data types. We may have Booleans, characters, strings, and varying bit sizes of integers, but when we need to represent decimal values we have to use floating point to enable a whole host of applications. In the case of low power CPUs like this one, floating point will also often be far slower than integers because the rules involved in doing floating point math is complex. At any rate, a float (32-bit) can be added with a throughput of one result per cycle, and a latency of four cycles. The same is true of adding a double or multiplying a float. However, multiplying or dividing doubles is definitely not a good idea here because peak throughput of multiplying doubles is one result per four clock cycles, with a latency of 7 clock cycles. Dividing doubles has a peak throughput of a result every 29 clock cycles, with a latency of 32 clock cycles.
If you happen to have a webpage open with the latency and throughput timings for Cortex A7, you’d probably guess that this is a Cortex A7, and you’d probably be right as well. Attempting to do a load and a store together has a timing that indicates these are XOR operations which cannot be executed in a parallel manner. The same is true of multiplication and addition even though the two operations shouldn’t have any shared logic. Conveniently, the Cortex A7 has a two-wide pipeline that has similar limitations. Cortex A5 is purely single-issue, so despite some similarity it can't explain why addition with an immediate/constant value and a register can happen twice per clock.
Given the overwhelming amount of evidence at the timing level of all these instructions, it’s almost guaranteed that we’re looking at a single core Cortex A7 or a derivative of it at 520 MHz. Even if this is just a Cortex A7, targeting a far lower maximum clock speed means that logic design can prioritize power efficiency over performance. Standard cells can favor techniques and styles that would otherwise unacceptably compromise performance in a 2+ GHz chip could be easily used in a 520 MHz chip such as device stacking, sleepy stack layout, higher Vt selection with negative active body biasing, and other techniques that would allow for either lower voltage at the same frequency, or reduced capacitance in dynamic power and reduced static leakage. Given that Cortex A7 has generally been a winning design for perf/W metrics, I suspect that key points of differentiation will come from implementation rather than architecture for the near future. Although I was hoping to see Apple Watch on a more leading-edge process like 14LPP/16FF+, I suspect this will be deferred until Apple Watch 2 or 3.








270 Comments
View All Comments
Shadowmaster625 - Monday, July 20, 2015 - link
OMG it taps your wrist when you get a notification. I will never ever have to miss an important txt ever again. I am going to rush out right now and plunk down $600 for this, and another $800 for an iphone so I can use it.Just kidding. Who are you frickin kidding? $1400 for a wrist tap. lol. How about this? If I'm expecting an important call or message, I will look at my phone more often. And NOT spend $1400 doing it.
Stuka87 - Monday, July 20, 2015 - link
If you don't want to live in the 21st century, but all means, don't. Smart phones are used by the majority of the population on earth, but nobody is forcing you to use one. Feel free to spend your money elsewhere.But it should be noted, VERY few smart phone owners pay the retail price.
BMNify - Monday, July 20, 2015 - link
What?? Almost all smartphone owners pay Full retail price for unlocked phones throughout the World, not everyone is a Slave to the carriers like in the USA.Guspaz - Monday, July 20, 2015 - link
US, Canada, UK, France, Australia, Singapore, all have major carriers doing phone subsidies. Not every country does, but many (most?) do.Ronald Hummelink - Monday, July 20, 2015 - link
In most markets these days these 'subsidies' are finance constructs. You repay the loan through the higher subscription fee. Evidence of that is many of these markets offer 'sim only' contracts significantly cheaper than bundled deals.Kristian Vättö - Monday, July 20, 2015 - link
Exactly. The 16GB iPhone 6 is $649 in the US without a contract.Guspaz - Tuesday, July 21, 2015 - link
What's the difference? They try to gussy them up and give them fancy names like "tabs", but they're just contracts by another name. THe only difference is they don't have a fixed length.The government (CRTC) didn't buy it either, and in the wireless code that sets the maximum amount of time before the balance owing (after which the ETF/ECF must reach zero) after 24 months, they simply defined these "tabs" as "contracts of indeterminate length", and applied the same 24-month restriction to them.
hughlle - Monday, July 20, 2015 - link
But are they subsidising the phone, or the service? I bought my HTC on contract, and however you look at it, I've now paid out more than the retail cost of the phone. In my mind it is the service that they are subsidising, not the phone.extide - Monday, July 20, 2015 - link
That doesnt even make sense, how could the carrier subsidize the service? They are subsidizing the phone by charging you extra for wireless service. The thing is that they never drop the price of your contract, so even after you have repaid the cost of the phone, you are still paying that higher price.Imagine if you bought the phone at TMobile who DOES have a lower service price when you do not get a subsidized phone. Say you also get a small loan to pay for the phone (T-Mo does this) -- once that 'loan' is paid off -- your monthly bill effectively goes down as you are just paying for the service.
Manch - Monday, July 20, 2015 - link
I keep my phone in my front pocket. If I get a text or what not the vibration tickles me downstairs a bit to let me know....