AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM ESTHistory: Where GDDR5 Reaches Its Limits
To really understand HBM we’d have to go all the way back to the first computer memory interfaces, but in the interest of expediency and sanity, we’ll condense that lesson down to the following. The history of computer and memory interfaces is a consistent cycle of moving between wide parallel interfaces and fast serial interfaces. Serial ports and parallel ports, USB 2.0 and USB 3.1 (Type-C), SDRAM and RDRAM, there is a continual process of developing faster interfaces, then developing wider interfaces, and switching back and forth between them as conditions call for.
So far in the race for PC memory, the pendulum has swung far in the direction of serial interfaces. Though 4 generations of GDDR, memory designers have continued to ramp up clockspeeds in order to increase available memory bandwidth, culminating in GDDR5 and its blistering 7Gbps+ per pin data rate. GDDR5 in turn has been with us on the high-end for almost 7 years now, longer than any previous memory technology, and in the process has gone farther and faster than initially planned.
But in the cycle of interfaces, the pendulum has finally reached its apex for serial interfaces when it comes to GDDR5. Back in 2011 at an AMD video card launch I asked then-graphics CTO Eric Demers about what happens after GDDR5, and while he expected GDDR5 to continue on for some time, it was also clear that GDDR5 was approaching its limits. High speed buses bring with them a number of engineering challenges, and while there is still headroom left on the table to do even better, the question arises of whether it’s worth it.

AMD 2011 Technical Forum and Exhibition
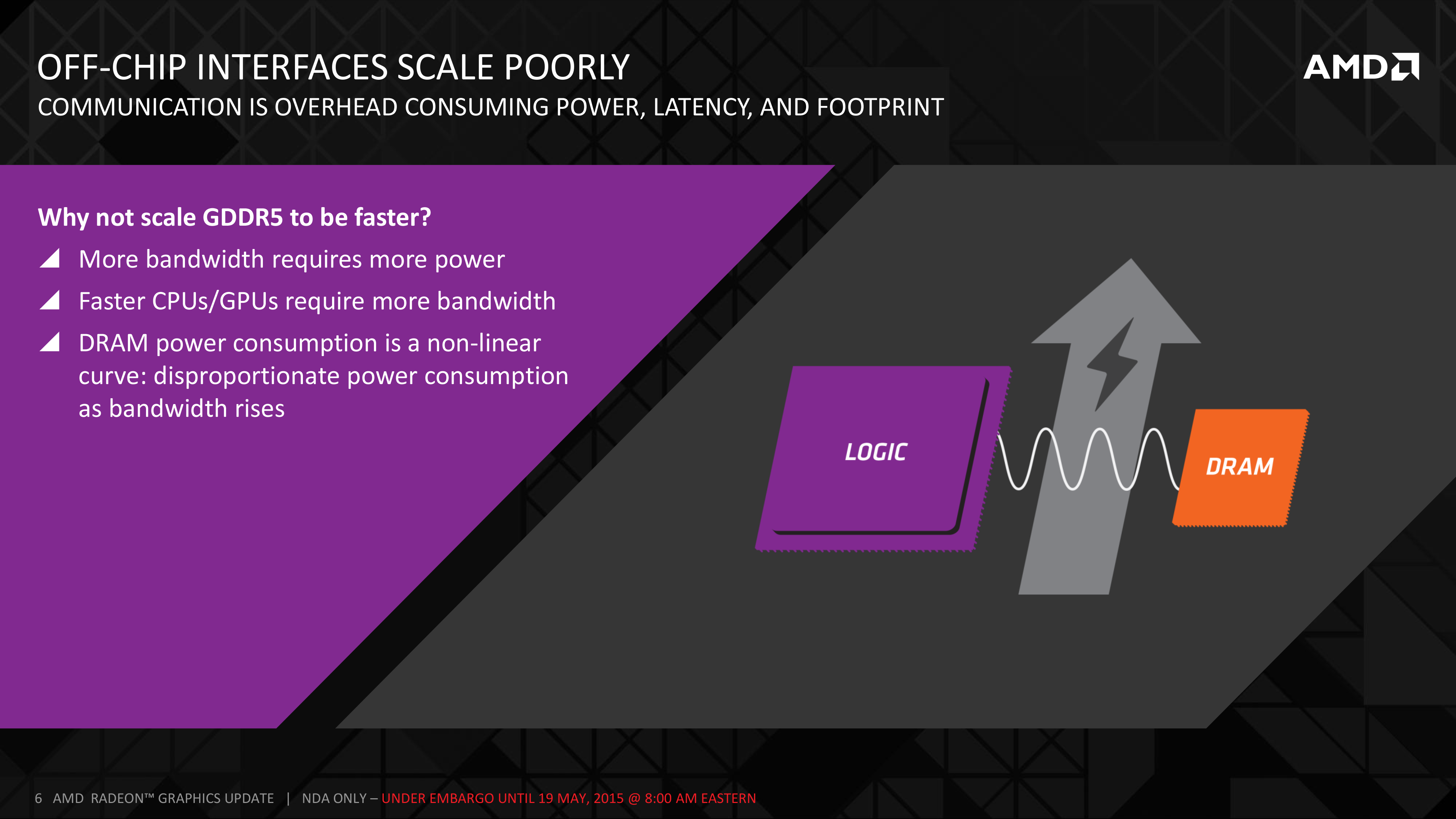
The short answer in the minds of the GPU community is no. GDDR5-like memories could be pushed farther, both with existing GDDR5 and theoretical differential I/O based memories (think USB/PCIe buses, but for memory), however doing so would come at the cost of great power consumption. In fact even existing GDDR5 implementations already draw quite a bit of power; thanks to the complicated clocking mechanisms of GDDR5, a lot of memory power is spent merely on distributing and maintaining GDDR5’s high clockspeeds. Any future GDDR5-like technology would only ratchet up the problem, along with introducing new complexities such as a need to add more logic to memory chips, a somewhat painful combination as logic and dense memory are difficult to fab together.
The current GDDR5 power consumption situation is such that by AMD’s estimate 15-20% of Radeon R9 290X’s (250W TDP) power consumption is for memory. This being even after the company went with a wider, slower 512-bit GDDR5 memory bus clocked at 5GHz as to better contain power consumption. So using a further, faster, higher power drain memory standard would only serve to exacerbate that problem.
All the while power consumption for consumer devices has been on a downward slope as consumers (and engineers) have made power consumption an increasingly important issue. The mobile space, with its fixed battery capacity, is of course the prime example, but even in the PC space power consumption for CPUs and GPUs has peaked and since come down some. The trend is towards more energy efficient devices – the idle power consumption of a 2005 high-end GPU would be intolerable in 2015 – and that throws yet another wrench into faster serial memory technologies, as power consumption would be going up exactly at the same time as overall power consumption is expected to come down, and individual devices get lower power limits to work with as a result.

Finally, coupled with all of the above has been issues with scalability. We’ll get into this more when discussing the benefits of HBM, but in a nutshell GDDR5 also ends up taking a lot of space, especially when we’re talking about 384-bit and 512-bit configurations for current high-end video cards. At a time when everything is getting smaller, there is also a need to further miniaturize memory, something that GDDR5 and potential derivatives wouldn’t be well suited to resolve.
The end result is that in the GPU memory space, the pendulum has started to swing back towards parallel memory interfaces. GDDR5 has been taken to the point where going any further would be increasingly inefficient, leading to researchers and engineers looking for a wider next-generation memory interface. This is what has led them to HBM.








163 Comments
View All Comments
phoenix_rizzen - Wednesday, May 20, 2015 - link
I see you missed the part of the article that discusses how the entire package, RAM and GPU cores, will be covered by a heat spreader (most likely along with some heat transferring goo underneath to make everything level) that will make it easier to dissipate heat from all the chips together.Similar to how Intel CPU packages (where there's multiple chips) used heat spreaders in the past.
vortmax2 - Wednesday, May 20, 2015 - link
Is this something that AMD will be able to license? Wondering if this could be a potential significant revenue stream for AMD.Michael Bay - Wednesday, May 20, 2015 - link
So what`s the best course of action?Wait for the second generation of technology?
wnordyke - Wednesday, May 20, 2015 - link
You will wait 1 year for the second generation. The second generation chips will be a big improvement over the current chips. (Pascal = 8 X Maxwell). (R400 = 4 X R390)Michael Bay - Wednesday, May 20, 2015 - link
4 times Maxwell seems nice.I`m in no hurry to upgrade.
akamateau - Thursday, May 28, 2015 - link
No not at all.HBM doesn't need the depth of memory that DDR4 or DDR5 does. DX12 performance is going to go through the roof.
HBM was designed to solve the GPU bottleneck. The electrical path latecy improvement is at least one clock not to mention the width of the pipes. The latency improvement will likely be 50% better. In and out. HBM will outperform ANYTHING that nVidia has out using DX12.
Use DX11 and you cripple your GPU anyway. You can only get 10% of the DX12 performance out of your system.
So get Windows 10 enable DX12 and buy this Card; by Christmas ALL games will be out DX12 capable as Microsoft is supporting DX12 with XBOX.
Mat3 - Thursday, May 21, 2015 - link
What if you put the memory controllers and the ROPs on the memory stack's base layer? You'd save more area for the GPU and have less data traffic going from the memory to the GPU.akamateau - Thursday, May 28, 2015 - link
That is what the interposer is for.akamateau - Monday, June 8, 2015 - link
AMD is already doing that. Here is their Patent.Interposer having embedded memory controller circuitry
US 20140089609 A1
" For high-performance computing systems, it is desirable for the processor and memory modules to be located within close proximity for faster communication (high bandwidth). Packaging chips in closer proximity not only improves performance, but can also reduce the energy expended when communicating between the processor and memory. It would be desirable to utilize the large amount of "empty" silicon that is available in an interposer. "
And a little light reading:
“NoC Architectures for Silicon Interposer Systems Why pay for more wires when you can get them (from your interposer) for free?” Natalie Enright Jerger, Ajaykumar Kannan, Zimo Li Edward S. Rogers Department of Electrical and Computer Engineering University of Toronto Gabriel H. Loh AMD Research Advanced Micro Devices, Inc”
http://www.eecg.toronto.edu/~enright/micro14-inter...
TheJian - Friday, May 22, 2015 - link
It's only an advantage if you're product actually WINS the gaming benchmarks. Until then, there is NO advantage. And I'm not talking winning benchmarks that are purely used to show bandwidth (like 4k when running single digits fps etc), when games are still well below 30fps min anyway. That is USELESS. IF the game isn't playable at whatever settings your benchmarking that is NOT a victory. It's like saying something akin to this "well if we magically had a gpu today that COULD run 30fps at this massively stupid resolution for today's cards, company X would win"...LOL. You need to win at resolutions 95% of us are using and in games we are playing (based on sales hopefully in most cases).Nvidia's response to anything good that comes of rev1 HBM will be, we have more memory (perception after years of built up more mem=better), and adding up to 512bit bus (from current 384 on their cards) if memory bandwidth is any kind of issue for next gen top cards. Yields are great on GDDR5, speeds can go up as shrinks occur and as noted Nvidia is on 384bit leaving a lot of room for even more memory bandwidth if desired. AMD should have went one more rev (at least) on GDDR5 to be cost competitive as more memory bandwidth (when GCN 1.2+ brings more bandwidth anyway) won't gain enough to make a difference vs. price increase it will cause. They already have zero pricing power on apu, cpu and gpu. This will make it worse for a brand new gpu.
What they needed to do was chop off compute crap that most don't use (saving die size or committing that size to more stuff we DO use in games), and improve drivers. Their last drivers were december 2014 (for apu or gpu, I know, I'm running them!). Latest beta on their site is 4/12. Are they so broke they can’t even afford a new WHQL driver every 6 months?
No day 1 drivers for witcher3. Instead we get complaints that gameworks hair cheats AMD and complaints CDPR rejected tressfx two months ago. Ummm, should have asked for that the day you saw witcher3 wolves with gameworks hair 2yrs ago, not 8 weeks before game launch. Nvidia spent 2yrs working with them on getting the hair right (and it only works great on the latest cards, screws kepler too until possible driver fixes even for those), while AMD made the call to CDPR 2 months ago...LOL. How did they think that call would go this late into development which is basically just spit and polish in the last months? Hairworks in this game is clearly optimized for maxwell at the moment but should improve over time for others. Turn down the aliasing on the hair if you really want a temp fix (edit the config file). I think the game was kind of unfinished at release TBH. There are lots of issues looking around (not just hairworks). Either way, AMD clearly needs to do the WORK necessary to keep up, instead of complaining about the other guy.