AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM ESTHistory: Where GDDR5 Reaches Its Limits
To really understand HBM we’d have to go all the way back to the first computer memory interfaces, but in the interest of expediency and sanity, we’ll condense that lesson down to the following. The history of computer and memory interfaces is a consistent cycle of moving between wide parallel interfaces and fast serial interfaces. Serial ports and parallel ports, USB 2.0 and USB 3.1 (Type-C), SDRAM and RDRAM, there is a continual process of developing faster interfaces, then developing wider interfaces, and switching back and forth between them as conditions call for.
So far in the race for PC memory, the pendulum has swung far in the direction of serial interfaces. Though 4 generations of GDDR, memory designers have continued to ramp up clockspeeds in order to increase available memory bandwidth, culminating in GDDR5 and its blistering 7Gbps+ per pin data rate. GDDR5 in turn has been with us on the high-end for almost 7 years now, longer than any previous memory technology, and in the process has gone farther and faster than initially planned.
But in the cycle of interfaces, the pendulum has finally reached its apex for serial interfaces when it comes to GDDR5. Back in 2011 at an AMD video card launch I asked then-graphics CTO Eric Demers about what happens after GDDR5, and while he expected GDDR5 to continue on for some time, it was also clear that GDDR5 was approaching its limits. High speed buses bring with them a number of engineering challenges, and while there is still headroom left on the table to do even better, the question arises of whether it’s worth it.

AMD 2011 Technical Forum and Exhibition
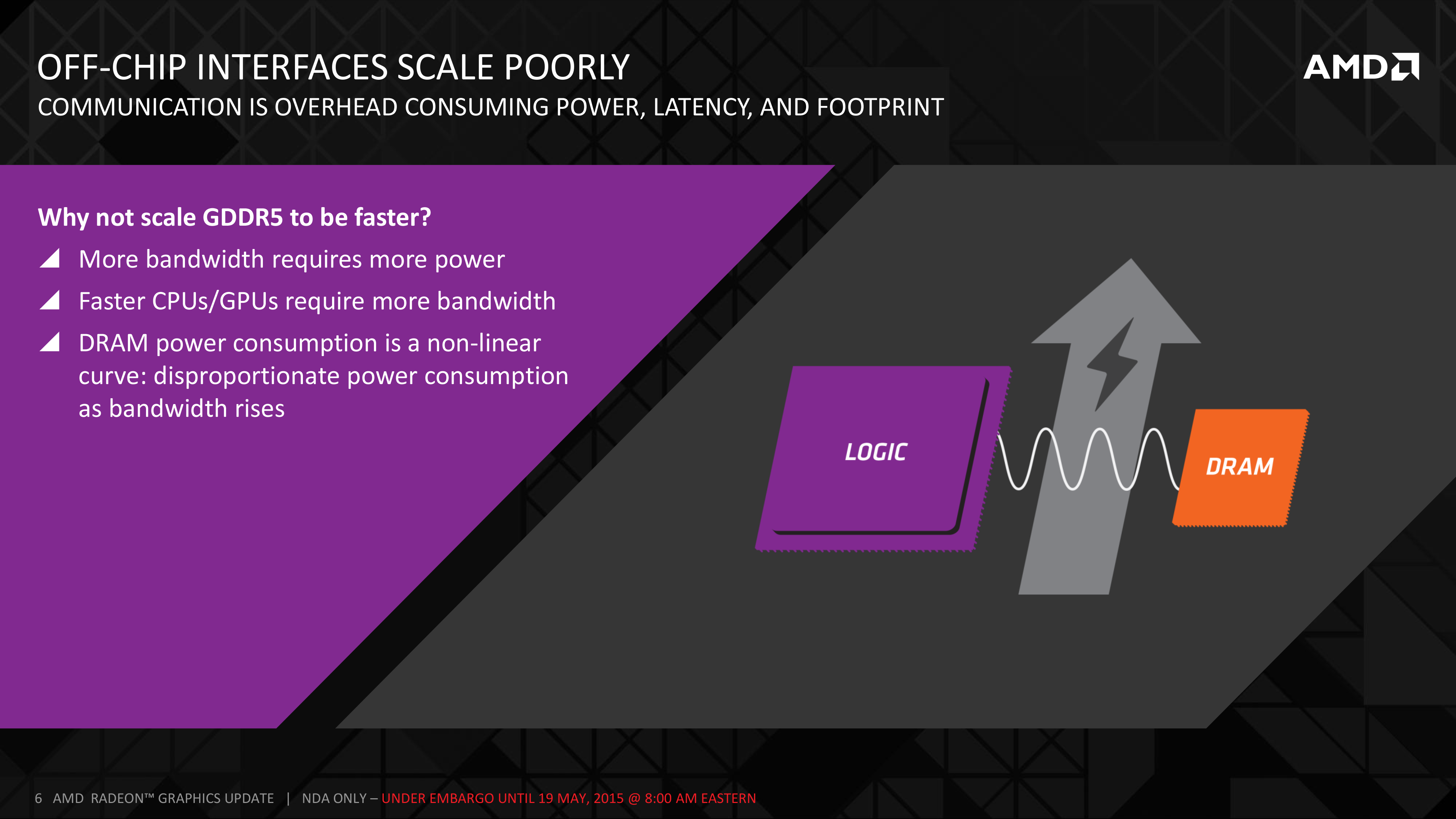
The short answer in the minds of the GPU community is no. GDDR5-like memories could be pushed farther, both with existing GDDR5 and theoretical differential I/O based memories (think USB/PCIe buses, but for memory), however doing so would come at the cost of great power consumption. In fact even existing GDDR5 implementations already draw quite a bit of power; thanks to the complicated clocking mechanisms of GDDR5, a lot of memory power is spent merely on distributing and maintaining GDDR5’s high clockspeeds. Any future GDDR5-like technology would only ratchet up the problem, along with introducing new complexities such as a need to add more logic to memory chips, a somewhat painful combination as logic and dense memory are difficult to fab together.
The current GDDR5 power consumption situation is such that by AMD’s estimate 15-20% of Radeon R9 290X’s (250W TDP) power consumption is for memory. This being even after the company went with a wider, slower 512-bit GDDR5 memory bus clocked at 5GHz as to better contain power consumption. So using a further, faster, higher power drain memory standard would only serve to exacerbate that problem.
All the while power consumption for consumer devices has been on a downward slope as consumers (and engineers) have made power consumption an increasingly important issue. The mobile space, with its fixed battery capacity, is of course the prime example, but even in the PC space power consumption for CPUs and GPUs has peaked and since come down some. The trend is towards more energy efficient devices – the idle power consumption of a 2005 high-end GPU would be intolerable in 2015 – and that throws yet another wrench into faster serial memory technologies, as power consumption would be going up exactly at the same time as overall power consumption is expected to come down, and individual devices get lower power limits to work with as a result.

Finally, coupled with all of the above has been issues with scalability. We’ll get into this more when discussing the benefits of HBM, but in a nutshell GDDR5 also ends up taking a lot of space, especially when we’re talking about 384-bit and 512-bit configurations for current high-end video cards. At a time when everything is getting smaller, there is also a need to further miniaturize memory, something that GDDR5 and potential derivatives wouldn’t be well suited to resolve.
The end result is that in the GPU memory space, the pendulum has started to swing back towards parallel memory interfaces. GDDR5 has been taken to the point where going any further would be increasingly inefficient, leading to researchers and engineers looking for a wider next-generation memory interface. This is what has led them to HBM.








163 Comments
View All Comments
LukaP - Wednesday, May 20, 2015 - link
Its only developed by them. Its a technology that is on the market now (or will be in 6 months after it stops being AMD exclusive). Its the same with GDDR3/5. ATI did lots of the work with developing it, but NV still had the option of using it.chizow - Wednesday, May 20, 2015 - link
http://en.wikipedia.org/wiki/JEDECLike any standards board or working group, you have a few heavy-lifters and everyone else leeches/contributes as they see fit, but all members have access to the technology in the hopes it drives adoption for the entire industry. Obviously the ones who do the most heavy-lifting are going to be the most eager to implement it. See: FreeSync and now HBM.
Laststop311 - Wednesday, May 20, 2015 - link
I do not agree with this article saying gpu's are memory bandwidth bottlenecked. If you don't believe me test it yourself. Keep gpu core clock at stock and maximize your memory oc and see the very little if any gains. Now put the memory at stock and maximize your gpu core oc and see the noticeable, decent gains.HBM is still a very necessary step in the right direction. Being able to dedicate an extra 25-30 watts to the gpu core power budget is always a good thing. As 4k becomes the new standard and games upgrade their assets to take advantage of 4k we should start to see gddr5's bandwidth eclipsed, especially with multi monitor 4k setups. It's better to be ahead of the curve than playing catchup but the benefits you get from using HBM right now today are actually pretty minor.
In some ways it hurts amd as it forces us to pay more money for a feature we won't get much use out of. Would you rather pay 850 for a HBM 390x or 700 for a gddr5 390x with basically identical performance since memory bandwidth is still good enough for the next few years with gddr5.
chizow - Wednesday, May 20, 2015 - link
I agree, bandwidth is not going to be the game-changer that many seem to think, at least not for gaming/graphics. For compute, bandwidth to the GPU is much more important as applications are constantly reading/writing new data. For graphics, the main thing you are looking at is reducing valleys and any associated stutters or drops in framerate as new textures are accessed by the GPU.akamateau - Monday, June 8, 2015 - link
High Bandwidth is absolutely essential for the increased demand that DX12 is going to provide. With DX11 GPU's did not work very hard. Massive drawcalls are going to require massive rendering. That is where HBM is the only solution.With DX11 the API overhead for a dGPU was around 2MILLION draw calls. With DX12 that changes radically to 15-20MILLION draw calls. All those extra polygons need rendering! how do you propose to do it with miniscule DDR4-5 pipes?
nofumble62 - Wednesday, May 20, 2015 - link
Won't be cheap. How many of you has pocket deep enough for this card?junky77 - Wednesday, May 20, 2015 - link
Just a note - the HBM solution seems to be more effective for high memory bandwidth loads. For low loads, the slower memory with higher parallelity might not be effective against the faster GDDR5asmian - Wednesday, May 20, 2015 - link
I understand that the article is primarily focussed on AMD as the innovator and GPU as the platform because of that. But once this is an open tech, and given the aggressive power budgeting now standard practice in motherboard/CPU/system design, won't there come a point at which the halving of power required means this *must* challenge standard CPU memory as well?I just feel I'm missing here a roadmap (or even a single sidenote, really) about how this will play into the non-GPU memory market. If bandwidth and power are both so much better than standard memory, and assuming there isn't some other exotic game-changing technology in the wings (RRAM?) what is the timescale for switchover generally? Or is HBM's focus on bandwidth rather than pure speed the limiting factor for use with CPUs? But then, Intel forced us on to DDR4 which hasn't much improved speeds while increasing cost dramatically because of the lower operating voltage and therefore power efficiency... so there's definitely form in that transitioning to lower power memory solutions. Or is GDDR that much more power-hungry than standard DDR that the power saving won't materialise with CPU memory?
Ryan Smith - Friday, May 22, 2015 - link
The non-GPU memory market is best described as TBD.For APUs it makes a ton of sense, again due to the GPU component. But for pure CPUs? The cost/benefit ratio isn't nearly as high. CPUs aren't nearly as bandwidth starved, thanks in part to some very well engineered caches.
PPalmgren - Wednesday, May 20, 2015 - link
There's something that concerns me with this: Heat!They push the benefits of a more compact card, but that also moves all the heat from the RAM right up next to the main core. The stacking factor of the RAM also scrunches their heat together, making it harder to dissipate.
The significant power reduction results in a significant heat reduction, but it still concerns me. Current coolers are designed to cover the RAM for a reason, and the GPUs currently get hot as hell. Will they be able to cool this combined setup reasonably?