AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM ESTHistory: Where GDDR5 Reaches Its Limits
To really understand HBM we’d have to go all the way back to the first computer memory interfaces, but in the interest of expediency and sanity, we’ll condense that lesson down to the following. The history of computer and memory interfaces is a consistent cycle of moving between wide parallel interfaces and fast serial interfaces. Serial ports and parallel ports, USB 2.0 and USB 3.1 (Type-C), SDRAM and RDRAM, there is a continual process of developing faster interfaces, then developing wider interfaces, and switching back and forth between them as conditions call for.
So far in the race for PC memory, the pendulum has swung far in the direction of serial interfaces. Though 4 generations of GDDR, memory designers have continued to ramp up clockspeeds in order to increase available memory bandwidth, culminating in GDDR5 and its blistering 7Gbps+ per pin data rate. GDDR5 in turn has been with us on the high-end for almost 7 years now, longer than any previous memory technology, and in the process has gone farther and faster than initially planned.
But in the cycle of interfaces, the pendulum has finally reached its apex for serial interfaces when it comes to GDDR5. Back in 2011 at an AMD video card launch I asked then-graphics CTO Eric Demers about what happens after GDDR5, and while he expected GDDR5 to continue on for some time, it was also clear that GDDR5 was approaching its limits. High speed buses bring with them a number of engineering challenges, and while there is still headroom left on the table to do even better, the question arises of whether it’s worth it.

AMD 2011 Technical Forum and Exhibition
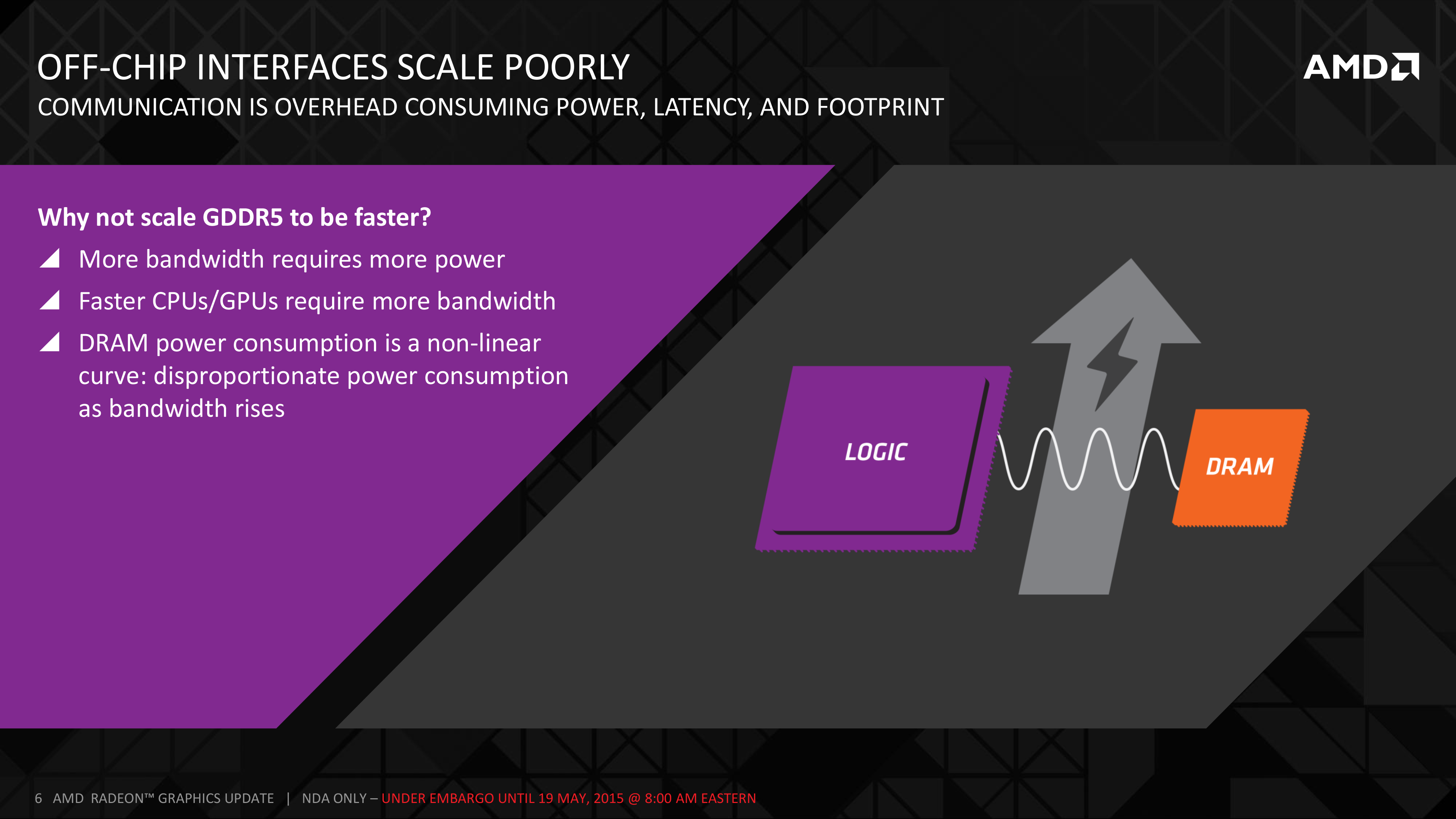
The short answer in the minds of the GPU community is no. GDDR5-like memories could be pushed farther, both with existing GDDR5 and theoretical differential I/O based memories (think USB/PCIe buses, but for memory), however doing so would come at the cost of great power consumption. In fact even existing GDDR5 implementations already draw quite a bit of power; thanks to the complicated clocking mechanisms of GDDR5, a lot of memory power is spent merely on distributing and maintaining GDDR5’s high clockspeeds. Any future GDDR5-like technology would only ratchet up the problem, along with introducing new complexities such as a need to add more logic to memory chips, a somewhat painful combination as logic and dense memory are difficult to fab together.
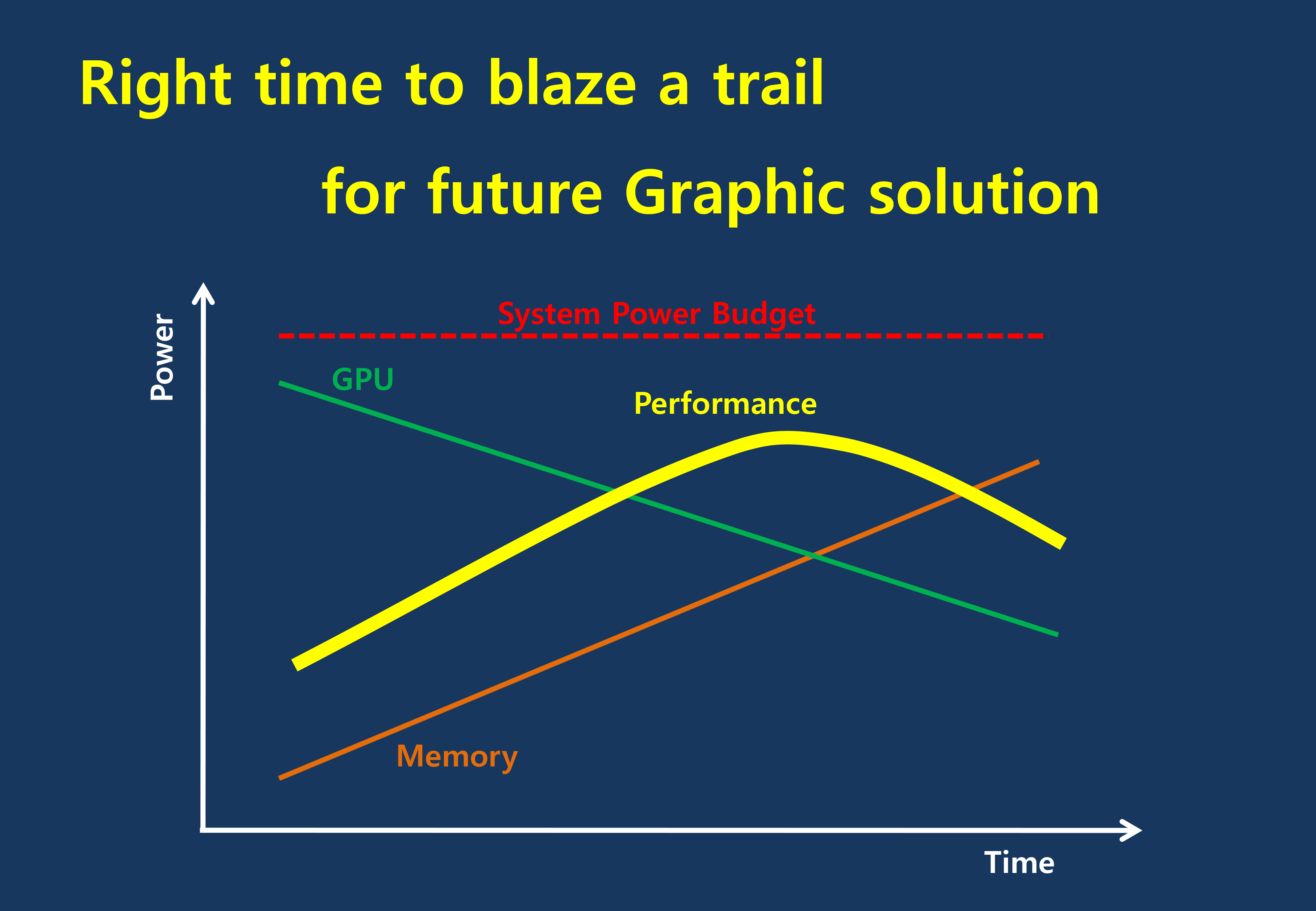
The current GDDR5 power consumption situation is such that by AMD’s estimate 15-20% of Radeon R9 290X’s (250W TDP) power consumption is for memory. This being even after the company went with a wider, slower 512-bit GDDR5 memory bus clocked at 5GHz as to better contain power consumption. So using a further, faster, higher power drain memory standard would only serve to exacerbate that problem.
All the while power consumption for consumer devices has been on a downward slope as consumers (and engineers) have made power consumption an increasingly important issue. The mobile space, with its fixed battery capacity, is of course the prime example, but even in the PC space power consumption for CPUs and GPUs has peaked and since come down some. The trend is towards more energy efficient devices – the idle power consumption of a 2005 high-end GPU would be intolerable in 2015 – and that throws yet another wrench into faster serial memory technologies, as power consumption would be going up exactly at the same time as overall power consumption is expected to come down, and individual devices get lower power limits to work with as a result.

Finally, coupled with all of the above has been issues with scalability. We’ll get into this more when discussing the benefits of HBM, but in a nutshell GDDR5 also ends up taking a lot of space, especially when we’re talking about 384-bit and 512-bit configurations for current high-end video cards. At a time when everything is getting smaller, there is also a need to further miniaturize memory, something that GDDR5 and potential derivatives wouldn’t be well suited to resolve.
The end result is that in the GPU memory space, the pendulum has started to swing back towards parallel memory interfaces. GDDR5 has been taken to the point where going any further would be increasingly inefficient, leading to researchers and engineers looking for a wider next-generation memory interface. This is what has led them to HBM.








163 Comments
View All Comments
testbug00 - Tuesday, May 19, 2015 - link
Name long term good relationships that Nvidia has had with other companies in the industry. Besides their board partners. You could argue TSMC either way. Otherwise, I'm getting nothing. They recently have a relationship with IBM that could become long term. It is entirely possible I'm just missing the companies they partner with that are happy with their partnership in the semi-conductor industry.Compared to IBM, TSMC, SK Hynix, and more.
ImSpartacus - Tuesday, May 19, 2015 - link
Can we have an interview with Joe Macri? He seems like a smart fella if he was the primary reference for this article.wnordyke - Tuesday, May 19, 2015 - link
This analysis does not discuss the benefits of the base die? The base die contains the memory controller and a data serializer. The architecture of moving the memory controller to the base die simplifies the design and removes many bottlenecks. The Base die is large enough to support a large number of circuits. (#1 memory controller, #2 Cache, #3 data processing)The 4096 wires is a large number and 4096 I/O buffers is a large number. The area of 4096 I/O buffers on the GPU die is expensive, and this expense is easily avoided by placing the memory controller on the base die. The 70% memory Bus efficiency is idle bandwidth, and this idle data does not need to be sent back to the GPU. The 4096 Interposer signals reduces to (4096 * 0.7 = 2867) saving 1,229 wires + I/O buffers.
A simple 2 to 1 serializer would reduces down to (2867 * 0.50 = 1432). The Interposer wires are short enough to avoid the termination resistors for a 2GHz signal. Removing the termination resistors is top of the list to saving power, the second on the list to save power is to minimize the Row Activate.
takeship - Tuesday, May 19, 2015 - link
So am I correct in assume then that the 295x2 equivalent performance numbers for Fiji leaked months ago are for the dual gpu variant? It concerns me that at no point in this write up did AMD even speculate what the performance inc with HBM might be.dew111 - Tuesday, May 19, 2015 - link
Why is everyone concerned about the 4GB limit in VRAM? A few enthusiasts might be disappointed, but for anyone who isn't using multiple 4k monitors, 4GB is just fine. It might also be limiting in some HPC workloads, but why would any of us consumers care about that?chizow - Wednesday, May 20, 2015 - link
I guess the concern is that people were expecting AMD's next flagship to pick up where they left off on the high-end, and given how much AMD has touted 4K, that would be a key consideration. Also, there are the rumors this HBM part is $850 to create a new AMD super high-end, so yeah, if you're going to say 4K is off the table and try to sell this as a super premium 4K part, you're going to have a hard sell as that's just a really incongruent message.In any case, AMD says they can just driver-magic this away, which is a recurring theme for AMD, so we will see. HBM's main benefits are VRAM to GPU transfers, but anything that doesn't fit in the local VRAM are still going to need to come from System RAM or worst, local storage. Textures for games are getting bigger than ever...so yeah not a great situation to be stuck at 4GB for anything over 1080p imo.
zodiacfml - Tuesday, May 19, 2015 - link
Definitely for their APUs and mobile. Making this first on GPUs helps recover the R&d without the volume scale.SolMiester - Tuesday, May 19, 2015 - link
Do the R9 290\x really perform that much better with OC memory on the cards? I didnt think AMD was ever really constrained by bandwidth, as they usually always had more on their generation of cards.Consequently, I dont see 390\x being that much competition to Titan X
Intel999 - Tuesday, May 19, 2015 - link
Thanks SolMiester,You have done an excellent job of displaying your level of intelligence. I don't think the New York Giants will provide much competition to the rest of the NFL this year. I won't support my prediction with any facts or theories just wanted to demonstrate that I am not a fan of the Giants.
BillyHerrington - Tuesday, May 19, 2015 - link
Since HBM are owned by AMD & Hynix, does other company (nvidia, etc) have to pay AMD in order to use HBM tech ?