AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM ESTHistory: Where GDDR5 Reaches Its Limits
To really understand HBM we’d have to go all the way back to the first computer memory interfaces, but in the interest of expediency and sanity, we’ll condense that lesson down to the following. The history of computer and memory interfaces is a consistent cycle of moving between wide parallel interfaces and fast serial interfaces. Serial ports and parallel ports, USB 2.0 and USB 3.1 (Type-C), SDRAM and RDRAM, there is a continual process of developing faster interfaces, then developing wider interfaces, and switching back and forth between them as conditions call for.
So far in the race for PC memory, the pendulum has swung far in the direction of serial interfaces. Though 4 generations of GDDR, memory designers have continued to ramp up clockspeeds in order to increase available memory bandwidth, culminating in GDDR5 and its blistering 7Gbps+ per pin data rate. GDDR5 in turn has been with us on the high-end for almost 7 years now, longer than any previous memory technology, and in the process has gone farther and faster than initially planned.
But in the cycle of interfaces, the pendulum has finally reached its apex for serial interfaces when it comes to GDDR5. Back in 2011 at an AMD video card launch I asked then-graphics CTO Eric Demers about what happens after GDDR5, and while he expected GDDR5 to continue on for some time, it was also clear that GDDR5 was approaching its limits. High speed buses bring with them a number of engineering challenges, and while there is still headroom left on the table to do even better, the question arises of whether it’s worth it.

AMD 2011 Technical Forum and Exhibition
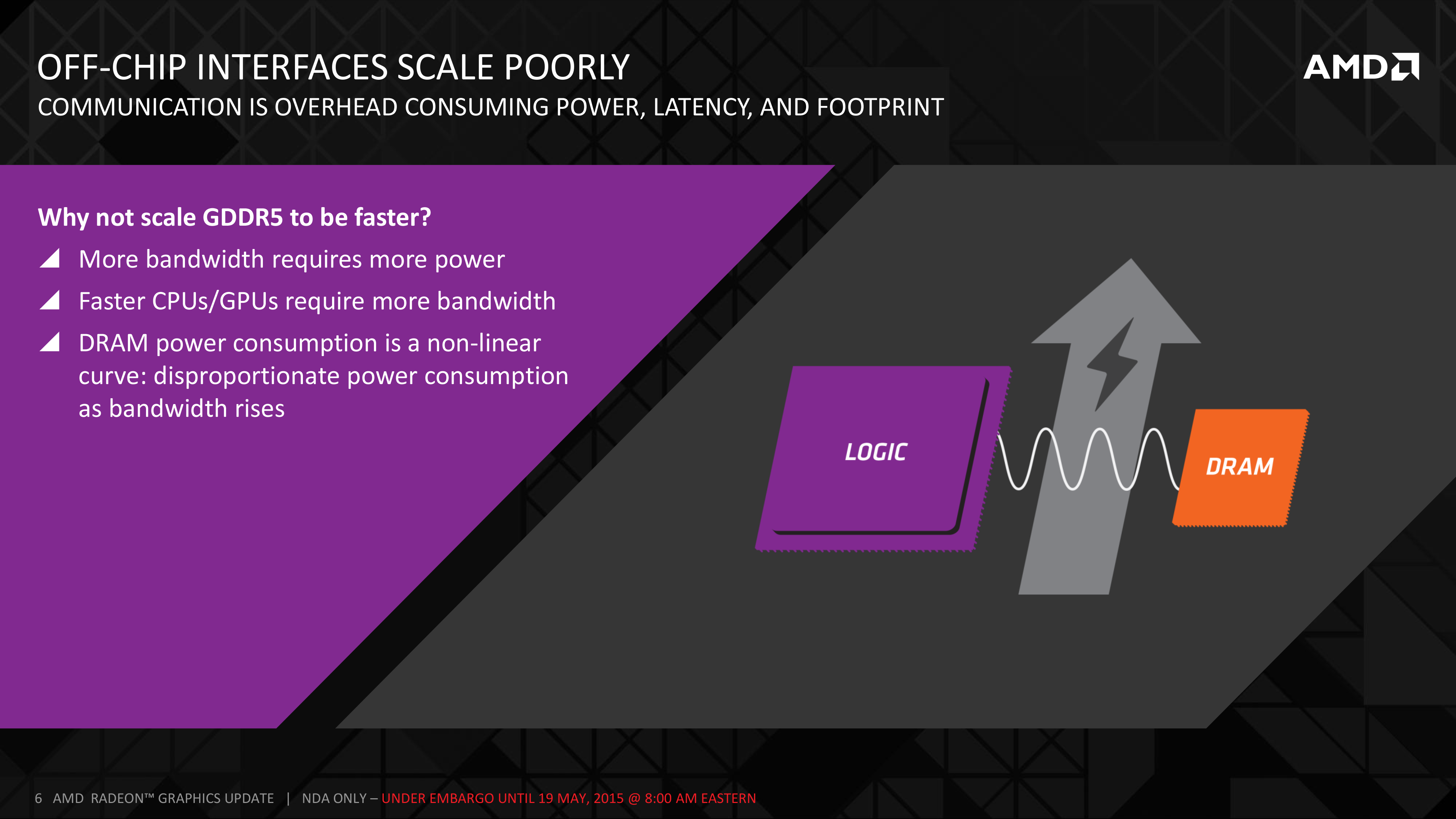
The short answer in the minds of the GPU community is no. GDDR5-like memories could be pushed farther, both with existing GDDR5 and theoretical differential I/O based memories (think USB/PCIe buses, but for memory), however doing so would come at the cost of great power consumption. In fact even existing GDDR5 implementations already draw quite a bit of power; thanks to the complicated clocking mechanisms of GDDR5, a lot of memory power is spent merely on distributing and maintaining GDDR5’s high clockspeeds. Any future GDDR5-like technology would only ratchet up the problem, along with introducing new complexities such as a need to add more logic to memory chips, a somewhat painful combination as logic and dense memory are difficult to fab together.
The current GDDR5 power consumption situation is such that by AMD’s estimate 15-20% of Radeon R9 290X’s (250W TDP) power consumption is for memory. This being even after the company went with a wider, slower 512-bit GDDR5 memory bus clocked at 5GHz as to better contain power consumption. So using a further, faster, higher power drain memory standard would only serve to exacerbate that problem.
All the while power consumption for consumer devices has been on a downward slope as consumers (and engineers) have made power consumption an increasingly important issue. The mobile space, with its fixed battery capacity, is of course the prime example, but even in the PC space power consumption for CPUs and GPUs has peaked and since come down some. The trend is towards more energy efficient devices – the idle power consumption of a 2005 high-end GPU would be intolerable in 2015 – and that throws yet another wrench into faster serial memory technologies, as power consumption would be going up exactly at the same time as overall power consumption is expected to come down, and individual devices get lower power limits to work with as a result.

Finally, coupled with all of the above has been issues with scalability. We’ll get into this more when discussing the benefits of HBM, but in a nutshell GDDR5 also ends up taking a lot of space, especially when we’re talking about 384-bit and 512-bit configurations for current high-end video cards. At a time when everything is getting smaller, there is also a need to further miniaturize memory, something that GDDR5 and potential derivatives wouldn’t be well suited to resolve.
The end result is that in the GPU memory space, the pendulum has started to swing back towards parallel memory interfaces. GDDR5 has been taken to the point where going any further would be increasingly inefficient, leading to researchers and engineers looking for a wider next-generation memory interface. This is what has led them to HBM.








163 Comments
View All Comments
testbug00 - Tuesday, May 19, 2015 - link
Nvidia didn't really have a choice, GDDR5 was *barely* ready for the 4870 iirc. Nvidia would have had to hold back finished cards for months to be able to get GDDR5 on them. Actually, they would have had to take a bet on if GDDR5 would be ready for production at that point.It isn't as simple as flipping a switch and having the GDDR5 controller work for GDDR3. It would require additional parts, leading to less dies per wafer and lower yield.
Nvidia did what was required to ensure their part would be able to get to market ASAP with enough memory bandwidth to drive it's shaders.
silverblue - Wednesday, May 20, 2015 - link
Very true.testbug00 - Tuesday, May 19, 2015 - link
Each chip if GDDR5 has a voltage, correct? So, each additional chip consumes more power?Maybe I'm missing something.
Ryan Smith - Tuesday, May 19, 2015 - link
An exceptional amount of energy is spent on the bus and host controller, which is why GDDR power consumption is such a growing issue. At any rate, yes, more chips will result in increased power, but we don't have a more accurate estimation at this time. The primary point is that the theoretical HBM configuration will draw half the power (or less) of the GDDR5 configurations.Shadowmaster625 - Tuesday, May 19, 2015 - link
Take 2048 shaders, 16GB of HBM, 4 CPU cores and a PCH, slap it onto a pcb, and ship it.silverblue - Tuesday, May 19, 2015 - link
Don't forget the SSD. ;)Ashinjuka - Tuesday, May 19, 2015 - link
Ladies and gentlemen, I give you... The MacBook Hair.Crunchy005 - Tuesday, May 19, 2015 - link
Put it all under a IHS and a giant heat sync on top with one fan.mr_tawan - Wednesday, May 20, 2015 - link
I was about to say the samething :)DanNeely - Tuesday, May 19, 2015 - link
Honestly I'm most interested in seeing what this is going to do for card sizes. As the decreased footprints for a GPU+HBM stack in AMD's planning numbers or nVidia's Pascal prototype show there's a potential for significantly smaller cards in the future.Water cooling enthusiasts look like big potential winners; a universal block would cover the ram too instead of just the GPU, and full coverage blocks could be significantly cheaper to manufacture.
I'm not so sure about the situation for air cooled cards though. Blower designs shouldn't be affected much; but no one really likes those. Open air designs look like they're more at risk though. If you shorten the card significantly you end up with only room for two fans on the heatsink instead of three; meaning you'd either have to accept reduced cooling or higher and louder fan speeds. That or have the cooler significantly overhang the PCB I suppose. Actually that has me wondering how or if being able to blow air directly through the heatsink instead of in the top and out the sides would impact cooling,