AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM ESTHistory: Where GDDR5 Reaches Its Limits
To really understand HBM we’d have to go all the way back to the first computer memory interfaces, but in the interest of expediency and sanity, we’ll condense that lesson down to the following. The history of computer and memory interfaces is a consistent cycle of moving between wide parallel interfaces and fast serial interfaces. Serial ports and parallel ports, USB 2.0 and USB 3.1 (Type-C), SDRAM and RDRAM, there is a continual process of developing faster interfaces, then developing wider interfaces, and switching back and forth between them as conditions call for.
So far in the race for PC memory, the pendulum has swung far in the direction of serial interfaces. Though 4 generations of GDDR, memory designers have continued to ramp up clockspeeds in order to increase available memory bandwidth, culminating in GDDR5 and its blistering 7Gbps+ per pin data rate. GDDR5 in turn has been with us on the high-end for almost 7 years now, longer than any previous memory technology, and in the process has gone farther and faster than initially planned.
But in the cycle of interfaces, the pendulum has finally reached its apex for serial interfaces when it comes to GDDR5. Back in 2011 at an AMD video card launch I asked then-graphics CTO Eric Demers about what happens after GDDR5, and while he expected GDDR5 to continue on for some time, it was also clear that GDDR5 was approaching its limits. High speed buses bring with them a number of engineering challenges, and while there is still headroom left on the table to do even better, the question arises of whether it’s worth it.

AMD 2011 Technical Forum and Exhibition
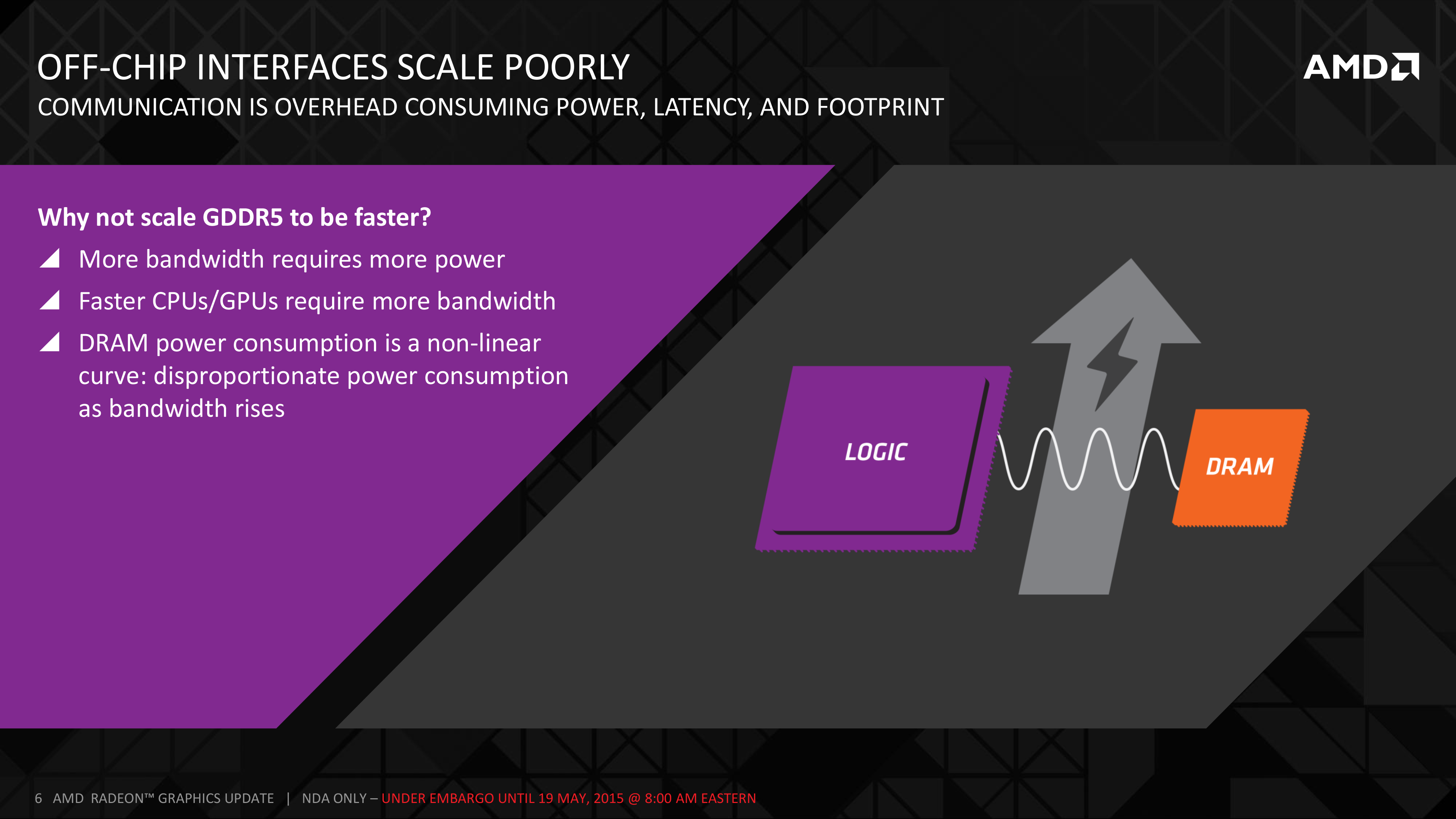
The short answer in the minds of the GPU community is no. GDDR5-like memories could be pushed farther, both with existing GDDR5 and theoretical differential I/O based memories (think USB/PCIe buses, but for memory), however doing so would come at the cost of great power consumption. In fact even existing GDDR5 implementations already draw quite a bit of power; thanks to the complicated clocking mechanisms of GDDR5, a lot of memory power is spent merely on distributing and maintaining GDDR5’s high clockspeeds. Any future GDDR5-like technology would only ratchet up the problem, along with introducing new complexities such as a need to add more logic to memory chips, a somewhat painful combination as logic and dense memory are difficult to fab together.
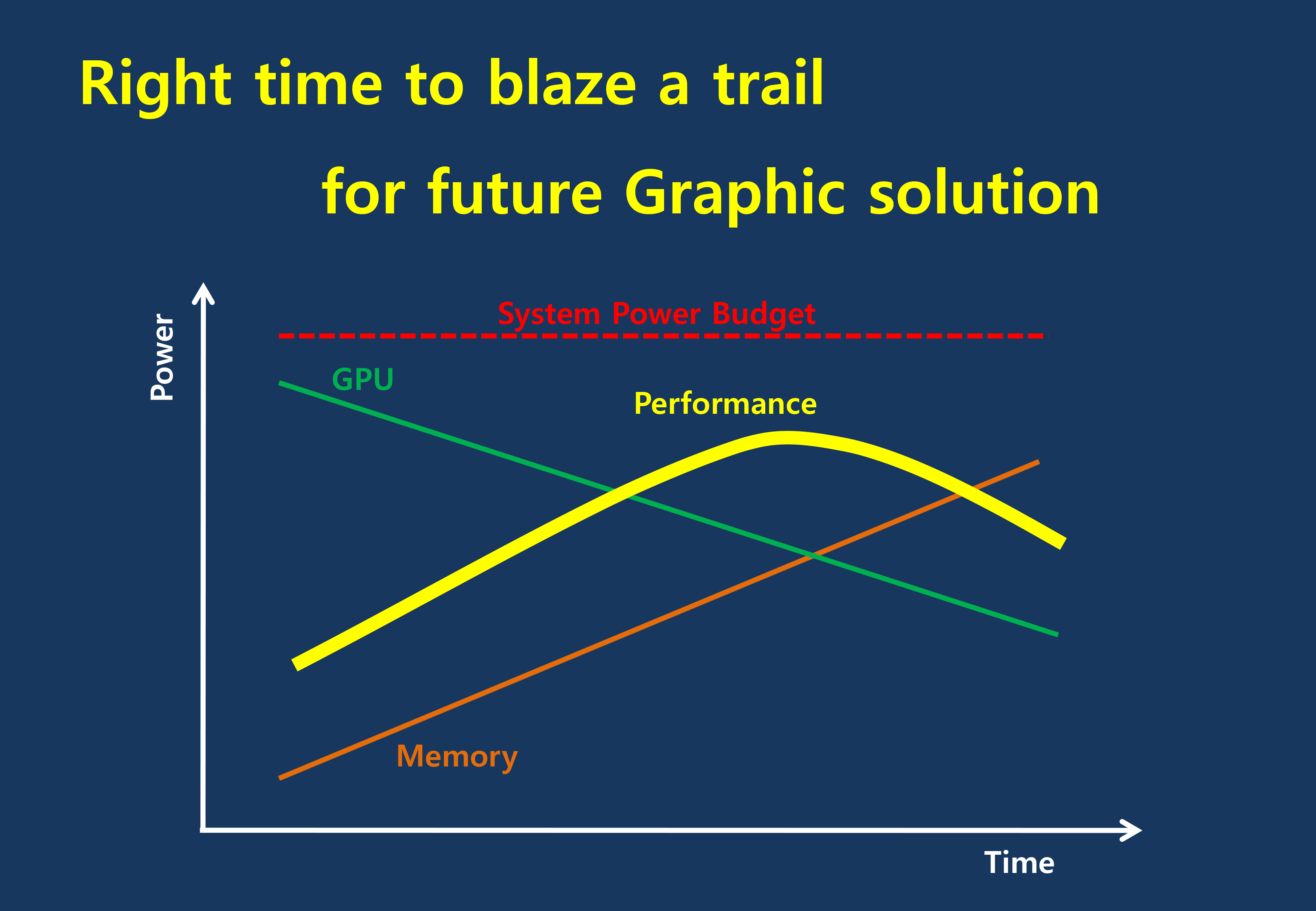
The current GDDR5 power consumption situation is such that by AMD’s estimate 15-20% of Radeon R9 290X’s (250W TDP) power consumption is for memory. This being even after the company went with a wider, slower 512-bit GDDR5 memory bus clocked at 5GHz as to better contain power consumption. So using a further, faster, higher power drain memory standard would only serve to exacerbate that problem.
All the while power consumption for consumer devices has been on a downward slope as consumers (and engineers) have made power consumption an increasingly important issue. The mobile space, with its fixed battery capacity, is of course the prime example, but even in the PC space power consumption for CPUs and GPUs has peaked and since come down some. The trend is towards more energy efficient devices – the idle power consumption of a 2005 high-end GPU would be intolerable in 2015 – and that throws yet another wrench into faster serial memory technologies, as power consumption would be going up exactly at the same time as overall power consumption is expected to come down, and individual devices get lower power limits to work with as a result.

Finally, coupled with all of the above has been issues with scalability. We’ll get into this more when discussing the benefits of HBM, but in a nutshell GDDR5 also ends up taking a lot of space, especially when we’re talking about 384-bit and 512-bit configurations for current high-end video cards. At a time when everything is getting smaller, there is also a need to further miniaturize memory, something that GDDR5 and potential derivatives wouldn’t be well suited to resolve.
The end result is that in the GPU memory space, the pendulum has started to swing back towards parallel memory interfaces. GDDR5 has been taken to the point where going any further would be increasingly inefficient, leading to researchers and engineers looking for a wider next-generation memory interface. This is what has led them to HBM.








163 Comments
View All Comments
HighTech4US - Tuesday, May 19, 2015 - link
So Fiji is really limited to 4 GB VRAM.chizow - Tuesday, May 19, 2015 - link
Wow, yep, although Ryan leaves the door open in the article, it is clear HBM1 is limited to 1GB per stack with 4 stacks on the sample PCBs. How AMD negotiates this will be interesting.Honestly it is looking more and more like Fiji is indeed Tonga XT x2 with HBM. Remember all those rumors last year when Tonga launched that it would be the launch vehicle for HBM? I guess it does support HBM, it just wasn't ready yet. Would also make sense as we have yet to see a fully-enabled Tonga ASIC; even though the Apple M295X has the full complement of 2048 SP, it doesn't have all memory controllers.
Kevin G - Tuesday, May 19, 2015 - link
The 1024 bit wide bus of an HBM stack is composed of eight 128 bit wide channels. Perhaps only half of the channels need to be populated allowing for twice the number of stacks to reach 8 GB without changing the Fiji chip itself?akamateau - Thursday, May 28, 2015 - link
Electrical path latency is cut to ZERO. EP Latency is how many clocks are used moving the data over the length of the electrical path. That latecy is about a one clock.testbug00 - Tuesday, May 19, 2015 - link
M295X isn't only in Apple... I think Alienware has one to! XDYeah. Interesting, even Charlie points that out a lot. He also claims that developers laugh at needing over 4GB, which, may be true in some games... GTA V and also quite a few (very poor) games show otherwise.
Of course, how much you need to have ~60+ FPS, I don't know. I believe at 1440/1600p, GTA V at max doesn't get over 4GB. Dunno how lowering settings changes the VRAM there. So, to hit 60FPS at a higher res might require turning down the settings of CURRENT GAMES (not future games, those are the problem!) probably would fit *MOST* of them inside 4GB. I still highly doubt that GTA V and some others would fit, however. *grumble grumble*
Hope AMD is pulling wool over everyone's eyes, however, their presentation does indeed seem to limit it to 4GB.
xthetenth - Tuesday, May 19, 2015 - link
GTA V taking over 4 GB if available and GTA V needing over 4 GB are two very different things. If it needed that memory then 980 SLI and 290X CF/the 295X would choke and die. They don't.hansmuff - Tuesday, May 19, 2015 - link
The don't choke and die, but they also can't deliver 4K at max detail and that is *in part* because of 4GB memory. http://www.hardocp.com/article/2015/05/04/grand_th...The 3.5GB 970 chokes early on 4K and needs feature reduction, the 980 allows more features, the Titan yet more features, in large part due to memory config.
Yeah it will be interesting how compression or new AA approaches lower memory usage but I will not buy a 4GB high end card now or in the future and depend on even more driver trickery to lower memory usage for demanding titles.
hansmuff - Tuesday, May 19, 2015 - link
To substantiate my comment about driver trickery, this is a quote from TechReport's HBM article:"When I asked Macri about this issue, he expressed confidence in AMD's ability to work around this capacity constraint. In fact, he said that current GPUs aren't terribly efficient with their memory capacity simply because GDDR5's architecture required ever-larger memory capacities in order to extract more bandwidth. As a result, AMD "never bothered to put a single engineer on using frame buffer memory better," because memory capacities kept growing. Essentially, that capacity was free, while engineers were not. Macri classified the utilization of memory capacity in current Radeon operation as "exceedingly poor" and said the "amount of data that gets touched sitting in there is embarrassing."
Strong words, indeed.
With HBM, he said, "we threw a couple of engineers at that problem," which will be addressed solely via the operating system and Radeon driver software. "We're not asking anybody to change their games.""
------------------------------
I don't trust them to deliver that on time and consistently.
chizow - Tuesday, May 19, 2015 - link
lol yeah, hopefully they didn't just throw the same couple of engineers who threw together the original FreeSync demos together on that laptop, or the ones who are tasked with fixing the FreeSync ghosting/overdrive issues, or the FreeSync CrossFire issues, or the Project Cars/TW3 driver updates. You get the point hehe, those couple engineers are probably pretty busy, I am sure they are thrilled to have one more promise added to their plates. :)dew111 - Tuesday, May 19, 2015 - link
Making something that is inefficient more efficient isn't "trickery," it's good engineering. And when the product comes out, we will be able to test it, so your trust is not required.