The Intel Xeon D Review: Performance Per Watt Server SoC Champion?
by Johan De Gelas on June 23, 2015 8:35 AM EST- Posted in
- CPUs
- Intel
- Xeon-D
- Broadwell-DE
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
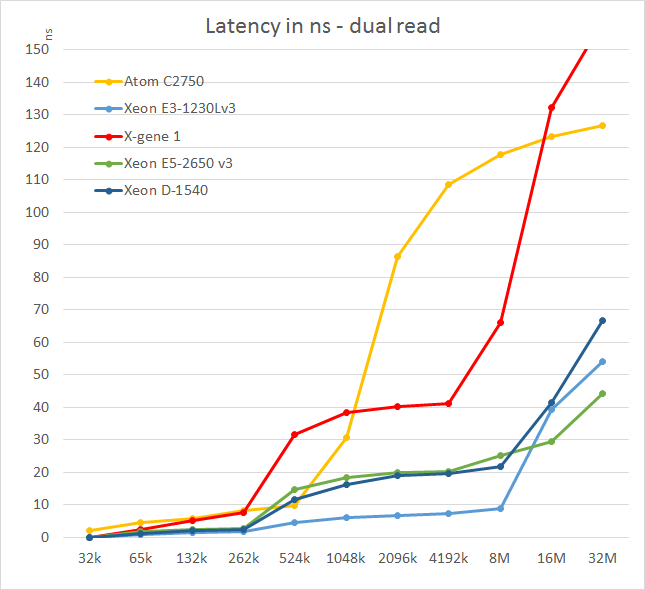
L3 caches have increased significantly the past years, but it is not all good news. The L3 cache of the Xeon E3 responds very quickly (about 10 ns or less than 30 cycles at 2.8 GHz) while the L3-cache of the new generation needs almost twice as much time to respond (about 20 ns or 50 cycles at 2.6 GHz). Larger L3 caches are not always a blessing and can result in a hit to latency - there are applications that have a relatively small part of cacheable data/instructions such as search engines and HPC application that work on huge amounts of data.
It gets worse for the "large L3 cache" models when we look at latency of accessing memory (measured at 64 MB):
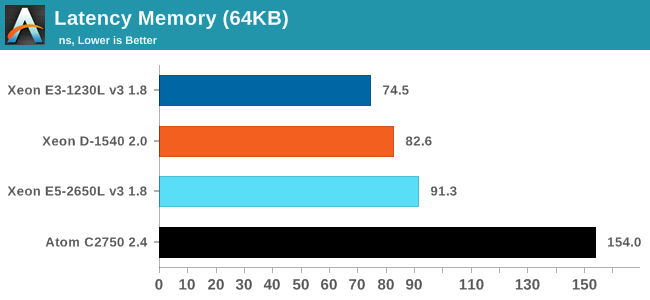
The higher L3-cache latency makes memory accesses more costly in terms of latency for the Xeon E5. Despite having access to DDR4-2133 DIMMs, the Xeon E5-2650L accesses memory slower than the Xeon E3-1230L. It is also a major weakness of the Atom C2750 which has much less sophisticated memory controller/prefetching.








90 Comments
View All Comments
JohanAnandtech - Wednesday, June 24, 2015 - link
Hi Patrick, the base clock of our chip is 2 GHz, not 1.9 GHz as the one pre-production version that we got from Intel. I have to check the turboclocks though, but I do believe we have measured 2.6 GHz. I'll doublecheck.pjkenned - Wednesday, June 24, 2015 - link
Awesome! Our ES ones were 1.9GHz.Chrisrodinis1 - Tuesday, June 23, 2015 - link
For comparison, this server uses Xeon's. It is the HP Proliant BL460c G9 blade server: https://www.youtube.com/watch?v=0s_w8JVmvf0MrDiSante - Wednesday, June 24, 2015 - link
Why use only -O2 when compiling the benchmarks? I would imagine that in order to squeeze out every last bit of performance, all production software is compiled with all optimizations turned up to 11. I noticed that their github uses -O2 as an example - is it that TinyMemBenchmark just doesn't play nice with -O3?JohanAnandtech - Wednesday, June 24, 2015 - link
The standard makefile had no optimization whatsoever. If you want to measure latency, you do not want maximum performance but rather accuracy, so I played it safe and used -O2. I am not convinced that all production software is optimized with all optimization turned on.diediealldie - Wednesday, June 24, 2015 - link
Intel seems disARMing them... X-Gene 2 doesn't look so promising, as they'll have to fight mighty Skylake-based Xeons, not Broadwell ones.Thanks for great article again.
jfallen - Wednesday, June 24, 2015 - link
Thanks Johan for the great article. I'm a tech enthusiast, and will never buy or use one of these. But it makes great reading and I appreciate the time you take to research and write the article.Regards
Jordan
JohanAnandtech - Wednesday, June 24, 2015 - link
Happy to read this! :-)TomWomack - Wednesday, June 24, 2015 - link
This looks very much consistent with my experience; the disconcertingly high idle power (I looked at the board with a thermal camera; the hot chips were the gigabit PHY, the inductors for the power supply, and the AST2400 management chip), the surprisingly good memory performance, the fairly hot SoC (running sixteen threads of number-crunching I get a power draw of 83W at the plug) and the generally pretty good computation.I'm not entirely sure it was a better buy for my use case than a significantly cheaper 6-core Haswell E - Haswell E is not that hot, electricity not that expensive, and from my supplier the X10SDV-F board and memory were £929 whilst Scan get me an i7-5820K board, CPU and memory for £702. And four-channel DDR4 probably is usefully faster than two-channel for what I do.
I quite strongly don't believe in server mystique - the outbuilding is big enough that I run out of power before I run out of space for micro-ATX cases, and I am lucky enough to be doing calculations which are self-checking to the point that ECC is a waste of money.
JohanAnandtech - Wednesday, June 24, 2015 - link
Hi Tom, I believe we saw up to 90 Watt at the wall when running OpenFOAM (10 Gbit enabled). It is however less relevant for such a chip which is not meant to be a HPC chip as we have shown in the article. HPC really screams for an E5.