NVIDIA Tegra X1 Preview & Architecture Analysis
by Joshua Ho & Ryan Smith on January 5, 2015 1:00 AM EST- Posted in
- SoCs
- Arm
- Project Denver
- Mobile
- 20nm
- GPUs
- Tablets
- NVIDIA
- Cortex A57
- Tegra X1
GPU Performance Benchmarks
As part of today’s announcement of the Tegra X1, NVIDIA also gave us a short opportunity to benchmark the X1 reference platform under controlled circumstances. In this case NVIDIA had several reference platforms plugged in and running, pre-loaded with various benchmark applications. The reference platforms themselves had a simple heatspreader mounted on them, intended to replicate the ~5W heat dissipation capabilities of a tablet.
The purpose of this demonstration was two-fold. First to showcase that X1 was up and running and capable of NVIDIA’s promised features. The second reason was to showcase the strong GPU performance of the platform. Meanwhile NVIDIA also had an iPad Air 2 on hand for power testing, running Apple’s latest and greatest SoC, the A8X. NVIDIA has made it clear that they consider Apple the SoC manufacturer to beat right now, as A8X’s PowerVR GX6850 GPU is the fastest among the currently shipping SoCs.
It goes without saying that the results should be taken with an appropriate grain of salt until we can get Tegra X1 back to our labs. However we have seen all of the testing first-hand and as best as we can tell NVIDIA’s tests were sincere.
| NVIDIA Tegra X1 Controlled Benchmarks | |||||
| Benchmark | A8X (AT) | K1 (AT) | X1 (NV) | ||
| BaseMark X 1.1 Dunes (Offscreen) | 40.2fps | 36.3fps | 56.9fps | ||
| 3DMark 1.2 Unlimited (Graphics Score) | 31781 | 36688 | 58448 | ||
| GFXBench 3.0 Manhattan 1080p (Offscreen) | 32.6fps | 31.7fps | 63.6fps | ||
For benchmarking NVIDIA had BaseMark X 1.1, 3DMark Unlimited 1.2 and GFXBench 3.0 up and running. Our X1 numbers come from the benchmarks we ran as part of NVIDIA’s controlled test, meanwhile the A8X and K1 numbers come from our Mobile Bench.
NVIDIA’s stated goal with X1 is to (roughly) double K1’s GPU performance, and while these controlled benchmarks for the most part don’t make it quite that far, X1 is still a significant improvement over K1. NVIDIA does meet their goal under Manhattan, where performance is almost exactly doubled, meanwhile 3DMark and BaseMark X increased by 59% and 56% respectively.
Finally, for power testing NVIDIA had an X1 reference platform and an iPad Air 2 rigged to measure the power consumption from the devices’ respective GPU power rails. The purpose of this test was to showcase that thanks to X1’s energy optimizations that X1 is capable of delivering the same GPU performance as the A8X GPU while drawing significantly less power; in other words that X1’s GPU is more efficient than A8X’s GX6850. Now to be clear here these are just GPU power measurements and not total platform power measurements, so this won’t account for CPU differences (e.g. A57 versus Enhanced Cyclone) or the power impact of LPDDR4.

Top: Tegra X1 Reference Platform. Bottom: iPad Air 2

For power testing NVIDIA ran Manhattan 1080p (offscreen) with X1’s GPU underclocked to match the performance of the A8X at roughly 33fps. Pictured below are the average power consumption (in watts) for the X1 and A8X respectively.
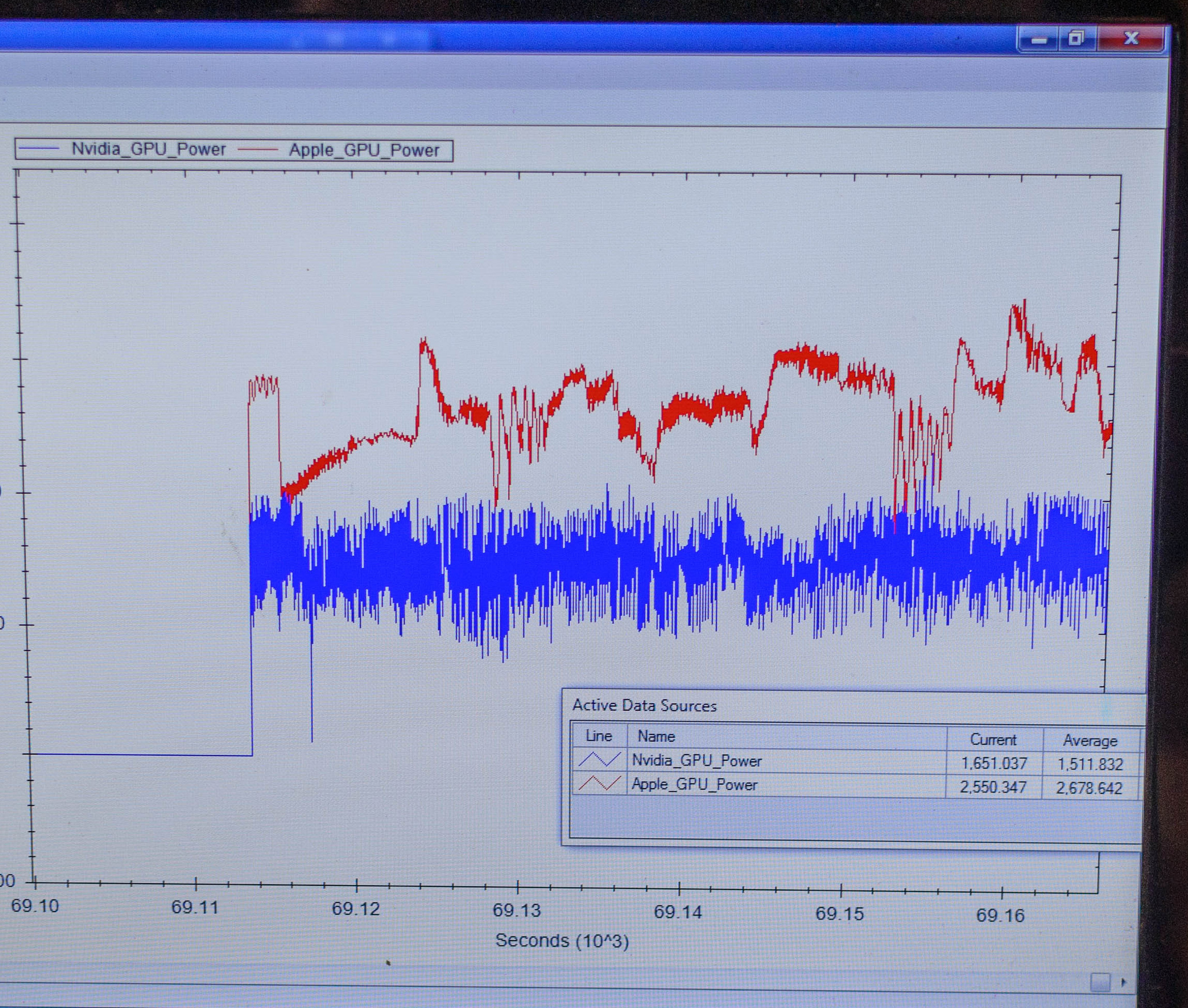

NVIDIA’s tools show the X1’s GPU averages 1.51W over the run of Manhattan. Meanwhile the A8X’s GPU averages 2.67W, over a watt more for otherwise equal performance. This test is especially notable since both SoCs are manufactured on the same TSMC 20nm SoC process, which means that any performance differences between the two devices are solely a function of energy efficiency.
There are a number of other variables we’ll ultimately need to take into account here, including clockspeeds, relative die area of the GPU, and total platform power consumption. But assuming NVIDIA’s numbers hold up in final devices, X1’s GPU is looking very good out of the gate – at least when tuned for power over performance.








194 Comments
View All Comments
tipoo - Monday, January 5, 2015 - link
Oh I read that wrong, you meant the games, not the play store. Still, games almost never crash on this either.PC Perv - Monday, January 5, 2015 - link
Why do you guys write what essentially is a PR statements by NV as if they were independently validated facts by yourselves? I suppose you guys did not have time to test any of these claims.So you end up writing contradictory paragraphs one after another. In the first, you say NVIDIA "embarked on a mobile first design for the first time." That statement in and of itself is not something one can prove or disprove, but in the very next paragraph you write,
"By going mobile-first NVIDIA has been able to reap a few benefits.. their desktop GPUs has resulted chart-topping efficiency, and these benefits are meant to cascade down to Tegra as well." (??)
I suggest you read that paragraph again. Maybe you missed something, or worse the whole paragraph comes off unintelligible.
ABR - Monday, January 5, 2015 - link
Well the situation itself is confusing since NVIDIA might have designed Maxwell "mobile-first" but actually released it "desktop-first". Then came notebook chips and now we are finally seeing Tegra. So release-wise the power efficiency "cascades down", even though they presumably designed starting from the standpoint of doing well under smaller power envelopes.PC Perv - Monday, January 5, 2015 - link
But that is a tautology that is totally vacuous of meaning. One can say the opposite thing in the exact same way: "We went with desktop first, but released to mobile first, so that power efficiency we've learned "cascaded up" to the desktops.So the impression one gets from reading that explanation is that it does not matter whether it was mobile first or desktop first. It is a wordplay that is void of meaningful information. (but designed to sound like something, I guess)
Yojimbo - Monday, January 5, 2015 - link
Isn't that standard reviewing practice? "Company X says they did Y in their design, and it shows in Z." The reviewer doesn't have to plant a mole in the organization and verify if NVIDIA really did Y like they said. This is a review, not an interrogation. If the results don't show in Z, then the reviewer will question the effectiveness of Y or maybe whether Y was really done as claimed. Yes, the logical flow of the statement you quoted is a bit weak, but I think it just has to do with perhaps poor writing and not from being some sort of shill, like you imply. The fact is that result Z, power-efficiency, is there in this case and it has been demonstrated on previously-released desktop products.As far as your statement that one could say the opposite thing and have the same meaning, I don't see it. Because going "mobile-first" means to focus on power-efficiency in the design of the architecture. It has nothing to do with the order of release of products. That is what the author means by "mobile-first," in any case. To say that NVIDIA was going "desktop-first" would presumably mean that raw performance, and not power-efficiency, was the primary design focus, and so the proper corresponding statement would be: "We went desktop-first, but released to mobile first, and the performance is meant to "cascade up" (is that a phrase? probably should be scale up, unless you live on a planet where the waterfalls fall upwards) to the desktops." There are two important notes here. Firstly, one could not assume that desktop-first design should result in increased mobile performance just because mobile-first design results in increased desktop efficiency. Secondly and more importantly, you replaced "is meant to" with "so". "So" implies a causation, which directly introduces the logical problem you are complaining about. The article says "is meant to," which implies that NVIDIA had aforethought in the design of the chip, with this release in mind, even though the desktop parts launched first. That pretty much describes the situation as NVIDIA tells it (And I don't see why you are so seemingly eager to disbelieve it. The claimed result, power-efficiency, is there, as I previously said.), and though maybe written confusingly, doesn't seem to have major logical flaws: "1. NVIDIA designed mobile-first, i.e., for power-efficiency. 2. We've seen evidence of this power-efficiency on previously-released desktop products. 3. NVIDIA always meant for this power-efficiency to similarly manifest itself in mobile products." The "cascade down" bit is just a color term.
Yojimbo - Monday, January 5, 2015 - link
I just want to note that I don't think the logical flow of the originally-written statement is as weak as I conceded to in my first paragraph. In your paraphrase-quote you left out the main clause and instead included a subordinate clause and treated it as the main clause. The author is drawing a parallel and citing evidence at the same time as making a logical statement and does so in a way that is a little confusing, but I don't think it really has weak logical flow.chizow - Monday, January 5, 2015 - link
Anyone who is familiar with the convergence of Tegra and GeForce/Tesla roadmaps and design strategy understands what the author(s) meant to convey there.Originally, Nvidia's design was to build the biggest, fastest GPU they could with massive monolithic GPGPUs built primarily for intensive graphics and compute applications. This resulted in an untenable trend with increasingly bigger and hotter GPUs.
After the undeniably big, hot Fermi arch, Nvidia placed an emphasis on efficiency with Kepler, but on the mobile side of things, they were still focusing on merging and implementing their desktop GPU arch with their mobile, which they did beginning with Tegra K1. The major breakthrough for Nvidia here was bringing mobile GPU arch in-line with their established desktop line.
That has changed with Maxwell, where Nvidia has stated, they took a mobile-first design strategy for all of their GPU designs and modularized it to scale to higher performance levels, rather than vice-versa, and the results have been obvious on the desktop space. Since Maxwell is launching later in the mobile space, the authors are saying everyone expects the same benefits in terms of power saving from mobile Maxwell over mobile Kepler that we saw with desktop Maxwell parts over desktop Kepler parts (roughly 2x perf/w).
There's really no tautology if you took the time to understand the development and philosophy behind the convergence of the two roadmaps.
Mondozai - Monday, January 5, 2015 - link
No, it's not untelligible for reasons that other people have already explained. If you understand the difference between what it is developed for and what is released first you understand the difference. And apparently you don't.OBLAMA2009 - Monday, January 5, 2015 - link
man nvidia is such a jokeMasterTactician - Monday, January 5, 2015 - link
512 GFLOPS... 8800GTX in a phone, anyone? Impressive.