Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTSingle-Threaded Integer Performance
I admit, the following two benchmarks are almost irrelevant for anyone buying a Xeon E5 based machine. But still, we have to quench our curiosity: how much have the new cores been improved? There is a lot that can be said about the sophisticated "uncore" improvements (cache coherency policies, low latency rings, and so on) that allow this multi-core monster to scale, but at the end of the day, good performance starts with a good core. And since we have listed the many subtle core improvements, we could not resist the opportunity to see how each core compares.
The results aren't totally meaningless either, as the profile of a compression algorithm is somewhat similar to many server workloads: it can be hard to extract instruction level parallelism (ILP) and it's sensitive to memory parallelism and latency. The instruction mix is a bit different, but it's still somewhat similar to many server workloads. And as one more reason to test performance in this manner, the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.1.
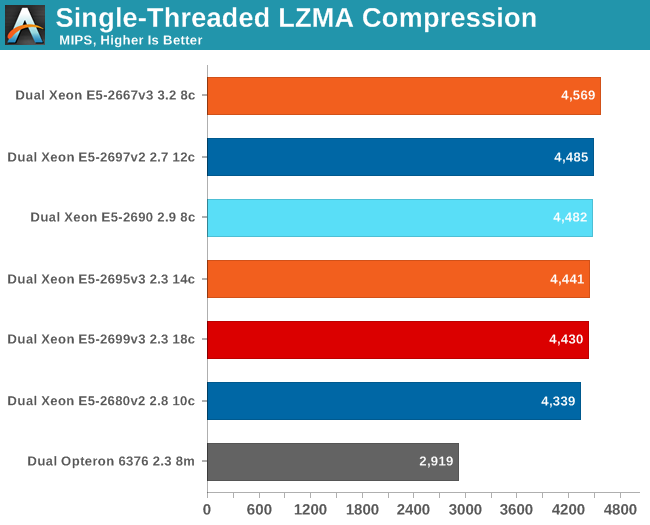
It looks more boring than it is. First of all, judging by the reactions on forums, many people expected that an 18-core E5-2699 v3 at 2.3GHz would be slower than a 3.2GHz Xeon E5-2667 v3. However you actually can have it all. The Xeon E5-2699 v3 and 2695 v3 boost their clock speed to no less than 3.6GHz when only one or two cores are active. The Xeon E5-2667 v3's maximum Turbo Boost is also the same 3.6GHz, so when only a few threads are active, the Xeon E5-2667 v3 has no clock advantage over the "mega/expensive SKUs" other than the fact that the clock speed will not drop lower than 3.2GHz if all cores are running at full bore.
Despite the fact that the Xeon E5-2690 core has lower IPC, it is able to keep up as it can boost the standard clock speed from 2.9 to 3.8GHz. As it is very hard to extract more IPC out of this kind of code, the extra 200MHz is enough to keep up.
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is very branch intensive and depends on the latencies of the multiply and shift instructions.
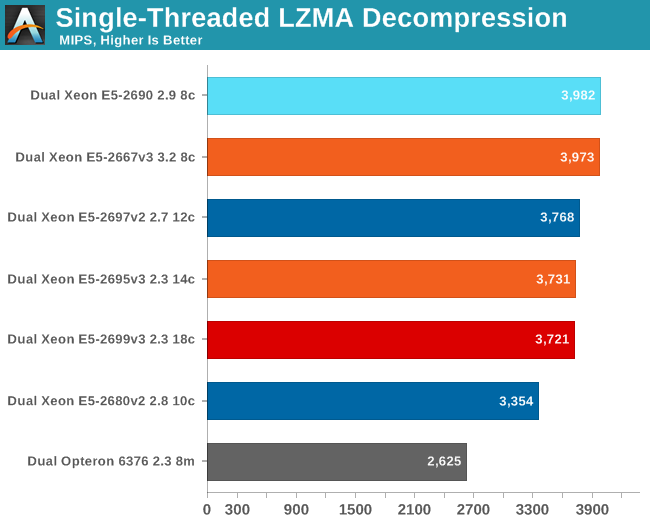
The older Xeon E5 takes the lead as decompression runs at very low IPC and is mostly depended on clock speed and low latency accesses. The new Xeon E5 v3 has slightly higher latency in both L3 cache and memory, so it falls behind.
What makes this benchmark interesting is that it proves that Turbo Boost works very well, even on an 18-core chip with a massive die. This is a big bonus, as especially in situations where you are setting up/preparing a system to be productive, it is very likely that you will be waiting for some single-threaded application to end. It also means that if one heavy request hits the server while it is running at very low load, the response time of the request will be low, keeping the impatient users happy.








85 Comments
View All Comments
martinpw - Monday, September 8, 2014 - link
There is a nice tool called i7z (can google it). You need to run it as root to get the live CPU clock display.kepstin - Monday, September 8, 2014 - link
Most Linux distributions provide a tool called "turbostat" which prints statistical summaries of real clock speeds and c state usage on Intel cpus.kepstin - Monday, September 8, 2014 - link
Note that if turbostat is missing or too old (doesn't support your cpu), you can build it yourself pretty quick - grab the latest linux kernel source, cd to tools/power/x86/turbostat, and type 'make'. It'll build the tool in the current directory.julianb - Monday, September 8, 2014 - link
Finally the e5-xxx v3s have arrived. I too can't wait for the Cinebench and 3DS Max benchmark results.Any idea if now that they are out the e5-xxxx v2s will drop down in price?
Or Intel doesn't do that...
MrSpadge - Tuesday, September 9, 2014 - link
Correct, Intel does not really lower prices of older CPUs. They just gradually phase out.tromp - Monday, September 8, 2014 - link
As an additional test of the latency of the DRAM subsystem, could you please run the "make speedup" scaling benchmark of my Cuckoo Cycle proof-of-work system at https://github.com/tromp/cuckoo ?That will show if 72 threads (2 cpus with 18 hyperthreaded cores) suffice to saturate the DRAM subsystem with random accesses.
-John
Hulk - Monday, September 8, 2014 - link
I know this is not the workload these parts are designed for, but just for kicks I'd love to see some media encoding/video editing apps tested. Just to see what this thing can do with a well coded mainstream application. Or to see where the apps fades out core-wise.Assimilator87 - Monday, September 8, 2014 - link
Someone benchmark F@H bigadv on these, stat!iwod - Tuesday, September 9, 2014 - link
I am looking forward to 16 Core Native Die, 14nm Broadwell Next year, and DDR4 is matured with much better pricing.Brutalizer - Tuesday, September 9, 2014 - link
Yawn, the new upcoming SPARC M7 cpu has 32 cores. SPARC has had 16 cores for ages. Since some generations back, the SPARC cores are able to dedicate all resources to one thread if need be. This way the SPARC core can have one very strong thread, or massive throughput (many threads). The SPARC M7 cpu is 10 billion transistors:http://www.enterprisetech.com/2014/08/13/oracle-cr...
and it will be 3-4x faster than the current SPARC M6 (12 cores, 96 threads) which holds several world records today. The largest SPARC M7 server will have 32-sockets, 1024 cores, 64TB RAM and 8.192 threads. One SPARC M7 cpu will be as fast as an entire Sunfire 25K. :)
The largest Xeon E5 server will top out at 4-sockets probably. I think the Xeon E7 cpus top out at 8-socket servers. So, if you need massive RAM (more than 10TB) and massive performance, you need to venture into Unix server territory, such as SPARC or POWER. Only they have 32-socket servers capable of reaching the highest performance.
Of course, the SGI Altix/UV2000 servers have 10.000s of cores and 100TBs of RAM, but they are clusters, like a tiny supercomputer. Only doing HPC number crunching workloads. You will never find these large Linux clusters run SAP Enterprise workloads, there are no such SAP benchmarks, because clusters suck at non HPC workloads.
-Clusters are typically serving one user who picks which workload to run for the next days. All SGI benchmarks are HPC, not a single Enterprise benchmark exist for instance SAP or other Enterprise systems. They serve one user.
-Large SMP servers with as many as 32 sockets (or even 64-sockets!!!) are typically serving thousands of users, running Enterprise business workloads, such as SAP. They serve thousands of users.