Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTLinux Kernel Compile
A more real world benchmark to test the integer processing power of our Xeon servers is a Linux kernel compile. Although few people compile their own kernel, compiling other software on servers is a common task and this will give us a good idea of how the CPUs handle a complex build.
To do this we have downloaded the 3.11 kernel from kernel.org. We then compiled the kernel with the "time make -jx" command, where x is the maximum number of threads that the platform is capable of using. To make the graph more readeable, the number of seconds in wall time was converted into the number of builds per hour.
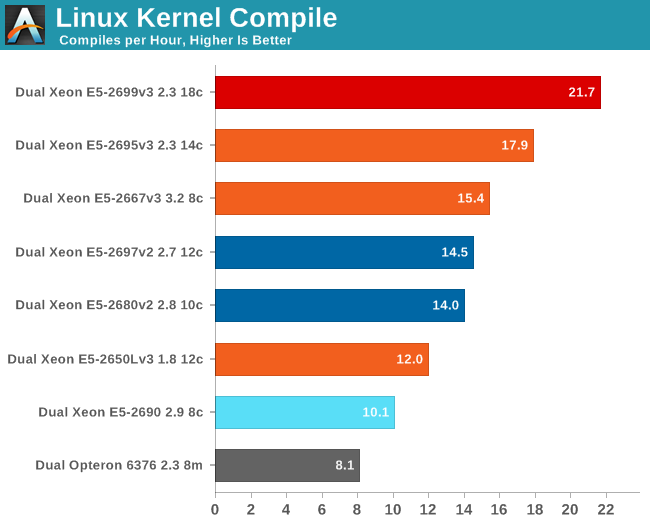
A kernel compile does not scale perfectly with more cores, but the Xeon E5-2699 still holds a healty lead over its 14-core brother. The Haswell architecture's improved integer core plays a larger role here than in compression as the E5-2697 v2 with 50% cores and a maximum clock of 3GHz (all cores Turbo Boost) cannot overtake the 3.2GHz Xeon E5-2667 v3. It is worth noting that the latter cannot Turbo Boost with all cores active.
The advantage over the Sandy Bridge EP is significant: 50% higher performance while the clock speed is only slightly higher as the Xeon E5-2690 can run briefly at 3.3GHz. The new Haswell core is good news for those who regularly deal with large software builds.








85 Comments
View All Comments
LostAlone - Saturday, September 20, 2014 - link
Given the difference in size between the two companies it's not really all that surprising though. Intel are ten times AMD's size, and I have to imagine that Intel's chip R&D department budget alone is bigger than the whole of AMD. And that is sad really, because I'm sure most of us were learning our computer science when AMD were setting the world on fire, so it's tough to see our young loves go off the rails. But Intel have the money to spend, and can pursue so many more potential avenues for improvement than AMD and that's what makes the difference.Kevin G - Monday, September 8, 2014 - link
I'm actually surprised they released the 18 core chip for the EP line. In the Ivy Bridge generation, it was the 15 core EX die that was harvested for the 12 core models. I was expecting the same thing here with the 14 core models, though more to do with power binning than raw yields.I guess with the recent TSX errata, Intel is just dumping all of the existing EX dies into the EP socket. That is a good means of clearing inventory of a notably buggy chip. When Haswell-EX formally launches, it'll be of a stepping with the TSX bug resolved.
SanX - Monday, September 8, 2014 - link
You have teased us with the claim that added FMA instructions have double floating point performance. Wow! Is this still possible to do that with FP which are already close to the limit approaching just one clock cycle? This was good review of integer related performance but please combine with Ian to continue with the FP one.JohanAnandtech - Monday, September 8, 2014 - link
Ian is working on his workstation oriented review of the latest XeonKevin G - Monday, September 8, 2014 - link
FMA is common place in many RISC architectures. The reason why we're just seeing it now on x86 is that until recently, the ISA only permitted two registers per operand.Improvements in this area maybe coming down the line even for legacy code. Intel's micro-op fusion has the potential to take an ordinary multiply and add and fuse them into one FMA operation internally. This type of optimization is something I'd like to see in a future architecture (Sky Lake?).
valarauca - Monday, September 8, 2014 - link
The Intel compiler suite I believe already convertsx *= y;
x += z;
into an FMA operation when confronted with them.
Kevin G - Monday, September 8, 2014 - link
That's with source that is going to be compiled. (And don't get me wrong, that's what a compiler should do!)Micro-op fusion works on existing binaries years old so there is no recompile necessary. However, micro-op fusion may not work in all situations depending on the actual instruction stream. (Hypothetically the fusion of a multiply and an add in an instruction stream may have to be adjacent to work but an ancient compiler could have slipped in some other instructions in between them to hide execution latencies as an optimization so it'd never work in that binary.)
DIYEyal - Monday, September 8, 2014 - link
Very interesting read.And I think I found a typo: page 5 (power optimization). It is well known that THE (not needed) Haswell HAS (is/ has been) optimized for low idle power.
vLsL2VnDmWjoTByaVLxb - Monday, September 8, 2014 - link
Colors or labeling for your HPC Power Consumption graph don't seem right.JohanAnandtech - Monday, September 8, 2014 - link
Fixed, thanks for pointing it out.