X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTMemory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
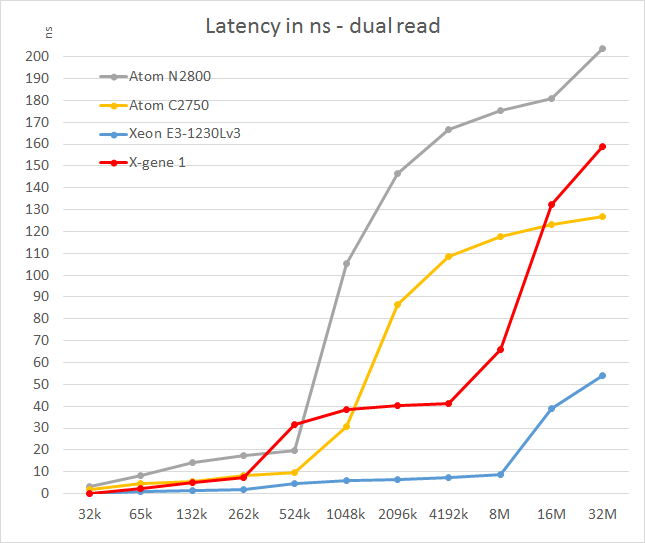
The X-Gene's L2 cache offers slightly better latency than the Atom C2750. That is not surprising as the L2 cache is four times smaller: 256KB vs 1024KB. Still, considering Intel has a lot of experience in building very fast L2 caches and the fact that AMD was never able to match Intel's capabilities, AppliedMicro deserves kudos.
However, the L3 cache seems pretty mediocre: latency tripled and then quadrupled! We are measuring 11-15 cycle latency for the L2 (single read) to 50-80 cycles (single read, up to 100 cycles in dual read) for the L3. Of course, on the C2750 it gets much worse beyond the 1MB mark as that chip has no L3 cache. Still, such a slow L3 cache will hamper performance in quite a few situations. The reason for this is probably that X-Gene links the cores and L3 cache via a coherent network switch instead of a low-latency ring (Intel).
In contrast to the above SoCs, the smart prefetchers of the Xeon E3 keep the latency in check, even at high block sizes. The X-Gene SoC however has the slowest memory controller of the modern SoCs once we go off-chip. Only the old Atom "Saltwell" is slower, where latency is an absolute disaster once the L2 cache (512KB) is not able to deliver the right cachelines.








47 Comments
View All Comments
Wilco1 - Tuesday, March 10, 2015 - link
GCC4.9 doesn't contain all the work in GCC5.0 (close to final release, but you can build trunk). As you hinted in the article, it is early days for AArch64 support, so there is a huge difference between a 4.9 and 5.0 compiler, so 5.0 is what you'd use for benchmarking.JohanAnandtech - Tuesday, March 10, 2015 - link
You must realize that the situation in the ARM ecosystem is not as mature as on x86. the X-Gene runs on a specially patched kernel that has some decent support for ACPI, PCIe etc. If you do not use this kernel, you'll get in all kinds of hardware trouble. And afaik, gcc needs a certain version of the kernel.Wilco1 - Tuesday, March 10, 2015 - link
No you can use any newer GCC and GLIBC with an older kernel - that's the whole point of compatibility.Btw your results look wrong - X-Gene 1 scores much lower than Cortex-A15 on the single threaded LZMA tests (compare with results on http://www.7-cpu.com/). I'm wondering whether this is just due to using the wrong compiler/options, or running well below 2.4GHz somehow.
JohanAnandtech - Tuesday, March 10, 2015 - link
Hmm. the A57 scores 1500 at 1.9 GHz on compression. The X-Gene scores 1580 with Gcc 4.8 and 1670 with gcc 4.9. Our scores are on the low side, but it is not like they are impossibly low.Ubuntu 14.04, 3.13 kernel and gcc 4.8.2 was and is the standard environment that people will get on the the m400. You can tweak a lot, but that is not what most professionals will do. Then we can also have to start testing with icc on Intel. I am not convinced that the overall picture will change that much with lots of tweaking
Wilco1 - Tuesday, March 10, 2015 - link
Yes, and I'd expect the 7420 will do a lot better than the 5433. But the real surprise to me is that X-Gene 1 doesn't even beat the A15 in Tegra K1 despite being wider, newer and running at a higher frequency - that's why the results look too low.I wouldn't call upgrading to the latest compiler tweaking - for AArch64 that is kind of essential given it is early days and the rate of development is extremely high. If you tested 32-bit mode then I'd agree GCC 4.8 or 4.9 are fine.
CajunArson - Tuesday, March 10, 2015 - link
This is all part of the problem: Requiring people to use cutting edge software with custom recompilation just to beat a freakin' Atom much less a real CPU?You do realize that we could play the same game with all the Intel parts. Believe me, the people who constantly whine that Haswell isn't any faster than Sandy Bridge have never properly recompiled computationally intensive code to take advantage of AVX2 and FMA.
The fact that all those Intel servers were running software that was only compiled for a generic X86-64 target without requiring any special tweaking or exotic hacking is just another major advantage for Intel, not some "cheat".
Klimax - Tuesday, March 10, 2015 - link
And if we are going for cutting edge compiler, then why not ICC with Intel's nice libraries... (pretty sure even ancient atom would suddenly look not that bad)Wilco1 - Tuesday, March 10, 2015 - link
To make a fair comparison you'd either need to use the exact same compiler and options or go all out and allow people to write hand optimized assembler for the kernels.68k - Saturday, March 14, 2015 - link
You can't seriously claim that recompiling an existing program with a different (well known and mature) compiler is equal to hand optimize things in assembler. Hint, one of the options is ridiculous expensive, one is trivial.aryonoco - Monday, March 9, 2015 - link
Thank you Johan. Very very informative article. This is one of the least reported areas of IT in general, and one that I think is poised for significant uptake in the next 5 years or so.Very much appreciate your efforts into putting this together.