X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTMemory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
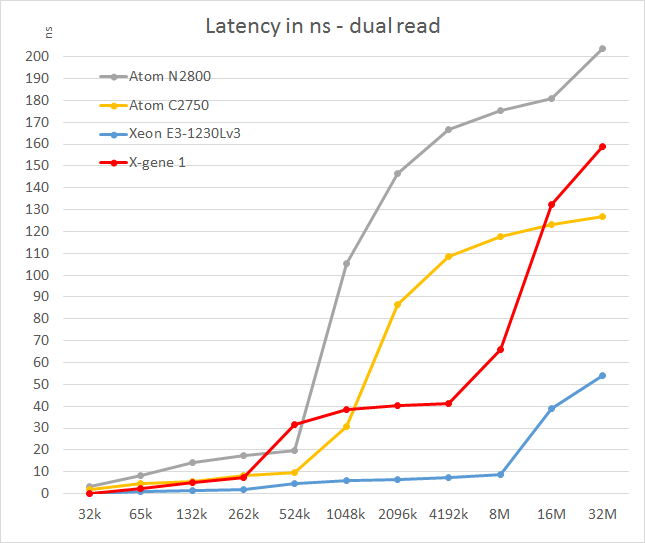
The X-Gene's L2 cache offers slightly better latency than the Atom C2750. That is not surprising as the L2 cache is four times smaller: 256KB vs 1024KB. Still, considering Intel has a lot of experience in building very fast L2 caches and the fact that AMD was never able to match Intel's capabilities, AppliedMicro deserves kudos.
However, the L3 cache seems pretty mediocre: latency tripled and then quadrupled! We are measuring 11-15 cycle latency for the L2 (single read) to 50-80 cycles (single read, up to 100 cycles in dual read) for the L3. Of course, on the C2750 it gets much worse beyond the 1MB mark as that chip has no L3 cache. Still, such a slow L3 cache will hamper performance in quite a few situations. The reason for this is probably that X-Gene links the cores and L3 cache via a coherent network switch instead of a low-latency ring (Intel).
In contrast to the above SoCs, the smart prefetchers of the Xeon E3 keep the latency in check, even at high block sizes. The X-Gene SoC however has the slowest memory controller of the modern SoCs once we go off-chip. Only the old Atom "Saltwell" is slower, where latency is an absolute disaster once the L2 cache (512KB) is not able to deliver the right cachelines.








47 Comments
View All Comments
IBleedOrange - Monday, March 9, 2015 - link
EETimes is wrong.Google "Intel Denverton"
beginner99 - Monday, March 9, 2015 - link
Maybe it would be good to mention the X-Gene is made on a 40nm process at the start of the article. I read the article and think for myself that the X-Gene is crap and in the end you get the explanation. It's on 40 nm vs Atoms on Intel 22 nm. It's a huge difference and currently the article is a bit misleading eg. shining a bad light on X-Gene and ARM. (And I say this even though I always was a proponent of Intel Big cores in almost all server applications).Stephen Barrett - Monday, March 9, 2015 - link
If APM had a newer part to test then we would have tested it. XG2 is simply not out yet. So the fact that APM has their flagship SoC on an older process is not misleading... Its the facts. The currently available Intel parts have a process advantage.warreo - Monday, March 9, 2015 - link
Mentioning it at the start would be good from a technical disclosure standpoint, but I'm not sure for the purposes of this article it truly matters. The article is comparing what is currently available now from APM and Intel. Reality is Intel will likely have a significant process advantage for the foreseeable future, and if you wanted to see a like for like comparison on a process basis, then you'll probably need to wait 2-3 years for X-Gene to get on 22nm, meanwhile Intel will have moved on to 10nm.CajunArson - Monday, March 9, 2015 - link
The 40nm process is only really relevant when it comes to the power-consumption comparisons.A 28nm.. or 20nm or 16nm... part with the same cores at the same clockspeeds will register the exact same level of performance. The only difference will be that the smaller lithographic processes should provide that level of performance in a smaller power envelope.
JohanAnandtech - Monday, March 9, 2015 - link
well, with so much time invested in an article, I always hope people will read the pages between page 1 and 18 too :-p. It is mentioned in the overview of the SoCs on page 5 and quite a few times at other pages too.colinstu - Monday, March 9, 2015 - link
what server is on the bottom of the first page?JohanAnandtech - Monday, March 9, 2015 - link
A very old MSI server :-). Just to show people what webfarms used before the micro server era.Samus - Monday, March 9, 2015 - link
I use the Xeon E3-1230v3 in desktop applications all the time. It's basically an i7 for the price of an i5.And a lot of IT dept dump them on eBay cheap when they upgrade their servers. They can be had well under $200 lightly used. The 80w TDP could theoretically have some drawbacks for boost time, but the real-world performance according to passmark elongated tests doesn't seem to show any difference between it's boost potential and that of an 88w i7-k
Great CPU's.
Alone-in-the-net - Monday, March 9, 2015 - link
In both your compilers, you need to specify the -march=native so the the compiler can optimize for the architecture you are running on, -o3 is not enough. This enables the compiler to use cpu specific commands.