ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM ESTTechnical Comparisons
As has quickly become tradition for us, to close out our look at the Midgard architecture we want to spend a bit of time comparing it to other SoC GPU architectures. As this is not a performance or benchmark article we aren’t going to dwell on the subject too much, but we find it’s helpful to get a high level overview of theoretical performance.
To do this we’ll take a quick look at theoretical performance for FP32 FLOPS, along with pixel and texel throughput. As this is a purely theoretical comparison it doesn’t (and can’t) take into account architectural efficiency, nor can it take into account real-world clockspeeds. But none the less it gives us something of a baseline.
To that end we asked ARM what a reasonable high-end Mali-T760 configuration might look like. T760 can scale up to 16 shader cores, but as we’ve seen in these scalable designs it’s very rare for anyone to build a SoC that actually takes the number of cores up to the architecture’s limit. And since T760 was only released to customers back in October of 2013, there are only a handful of designs announced so far and none of them are particularly high-end. To that end ARM suggested that a Mali-T760 MP10 would be a reasonable approximation of a high-end shipping configuration, so that is what we’ve gone with.
| GPU Specification Comparison | ||||||
| NVIDIA K1 | Imagination PVR GX6650 | ARM Mali-T760 MP10 | AMD A4-1350 | |||
| FP32 ALUs | 192 | 192 | 100 | 128 | ||
| FP32 FLOPs | 384 | 384 | 200 (340) | 256 | ||
| Pixels/Clock (ROPs) | 4 | 12 | 10 | 4 | ||
| Texels/Clock | 8 | 12 | 10 | 8 | ||
| GFLOPS @ 300MHz | 115.2 GFLOPS | 115.2 GFLOPS | 60 (102) GFLOPS | 76.8 GFLOPS | ||
| Architecture | Kepler | Rogue (6XT) | Midgard (T700) | GCN 1.1 | ||
Briefly, we can see that as far as theoretical shading performance is concerned, our theoretical Mali-T760 would push 60 GFLOPS when counting MADs (20 FLOPS/clock/core). Or when using ARM’s preferred metric of MAD plus a dot product (34 FLOPS/clock/core) this becomes 102 GLOPS. How you count ends up being important here as it means the theoretical throughput of the T760MP10 is either close to something like AMD’s A4-1350, or close to the very high end configurations that NVIDIA and Imagination will be peddling.
On the other hand T760MP10’s pixel and texel throughput looks very good, easily exceeding both our AMD and NVIDIA configurations on both and specifically more than doubling the pixel throughput. Pixel throughput is going to be especially important going forward as these SoCs get paired with increasingly high resolution displays – the TV industry has in recent years become big SoC consumers and 4K TVs are growing in popularity – so being able to push a lot of pixels will in turn be helpful for pushing such displays. However ARM’s efficiency technology such as Transaction Elimination and AFBC will also have to play a big part here, as writing that many pixels per clock raw would consume a large amount of memory bandwidth, something SoCs rarely have to spare.
Final Words
With apologies in advance to ARM, wrapping up this article the first thing that comes to mind is something we wrote when looking at Imagination’s Rogue architecture earlier this year: “So it’s with some hope and a bit of luck that this might get the ball rolling with the other SoC GPU vendors, getting them to open up their doors a bit more so that we can see what’s inside their designs.”
It’s safe to say then that we have indeed been lucky about getting other SoC GPU vendors to open up about their architectures. ARM’s decision to come take a seat at the “open architecture” table has given us a great opportunity to see into the heart of another SoC GPU and to better understand and appreciate just what’s going on under the hood when we look at Mali powered products. Plus in opening up on their GPU architecture, we have been given the chance to see what just may be the least conventional GPU of the modern era.
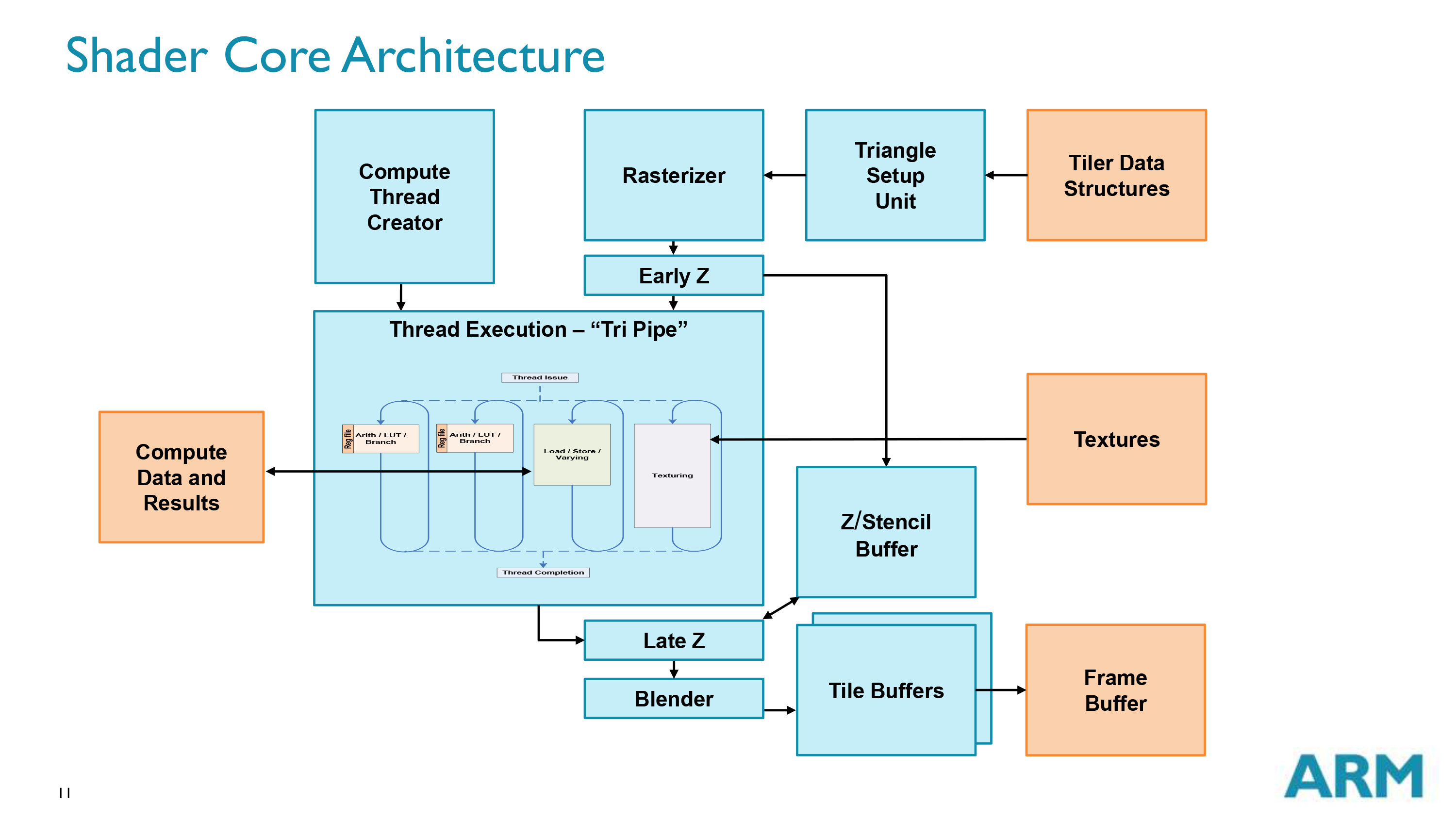
When ARM first began to brief me on the Midgard architecture, they told me that it would be something unlike anything else we’ve seen before, and while I believed them I don’t believe that description is quite strong enough to get across just how surprised I was by ARM’s autonomous, TLP insensitive shader design. It took the better part of a few days even after the briefing to really internalize just what they had done, and while it seems simple (and very cool) in retrospect, going for an unorthodox architecture certainly throws you for a loop at first after spending several years covering the world of wavefront-driven architectures.
As for Midgard and its resulting products, this stands to be an interesting and exciting time for ARM. The finalization of OpenGL ES 3.1 and the announcement of the Android Extension Pack means that some of the functionality that ARM has had to sit on thus far is finally going to be exposed and used. And meanwhile with 64bit Android coming up and ARM’s 64bit Cortex-A5x processors similarly near, ARM can begin exploiting some of that shared 64bit development that ARMv8 and Midgard went through.
At the same time however ARM also will face the same struggle for market share that the other SoC GPU vendors also face. As we’ve discussed in the past, the SoC GPU market is full of competitors, some who make their own SoCs and hence won’t be ARM GPU customers, and others who are in the licensing business just as much as ARM. With the latest generation Mali-T700 series parts ARM already has some T760 wins with MediaTek, who will be using T760 with their mid-range Cortex-A53 SoCs. But at the same time I’d love to see what flagship-caliber device would look like with a T760, so hopefully we’ll get that chance over the next year.
This incidentally is all the more reason to be open right now, as it’s that much easier to convince your immediate customers and even build a brand among end users when they can freely learn more about your products and how they operate. To that end the “open architecture” table remains open, and as we shift to the next generation of SoCs and next wave of SoC GPUs, with any luck this won’t be the last time we get to learn more about the GPUs that are increasingly in our everyday devices.








66 Comments
View All Comments
toyotabedzrock - Friday, July 4, 2014 - link
Didn't imagine also buy from ATI? Maybe that is why they are concerned with patents?Kevin G - Saturday, July 5, 2014 - link
There likely is a cross licensing agreement in place. Literally to build any modern GPU a company has to cross license patents. It works out to be zero sum in that money isn't exchanged but one company can use the other's patents (and future patents) royalty free.This also puts a rather high barrier to entry in the market.
nolaviz - Thursday, July 3, 2014 - link
Ah, the history... I led the integration of MALI55 into Zoran's APPROACH-5C. Sweet memories :)skiboysteve - Thursday, July 3, 2014 - link
Very interesting. Complete 100% opposite of the AMD architecture.Also, the fact that they can power down shader cores and even individual ALUs makes this pure ILP and zero TLP architecture really shine. Because the compiler only needs to optimize work on an ALU level.... Not on a shader or wavefront level. So then based upon demand they just feed more or less of these ALU-optomized-packets of work into the GPU and power down the rest of the ALUs. It makes complete sense. Make each ALU independent, compile work on a per ALU basis, then scale your ALU utilization at run time... And also scale your chip portfolio on ALU count. Perfect scalability in price, performance and power combined with straightforward driver work.
Awesome!
rootheday - Thursday, July 3, 2014 - link
Transaction Elimination might work for "render to texture", where the texture is then used later in the scene, but it doesn't make sense to me for the final render target that is shown on the screen.. Typically your final render target is part of a swap chain with 2 or 3 different buffers. So the CRC computed for a tile in Frame N would need to match the CRC for frame N-2 (or maybe N-3), not N-1.EdvardS - Thursday, July 3, 2014 - link
So each buffer has its own CRC buddy attached to it - problem solved :-) Longer buffer chains just reduces you temporal coherency a bit.hexgrid - Thursday, July 3, 2014 - link
Relying on a 32bit hash for transaction elimination is a very bad idea. Assuming a normal distribution of hash results, the Birthday Paradox means you've got a better than 50% chance of collision if you have more than ~5000 items being hashed. The compartmentalized comparisons (it looks like they only compare against the same tile) means the collision rate will be lower, but there will be collisions, and in some cases they will look terrible.If there's a glitch, there's an excellent chance it will persist for a while. For example, let's say I'm bringing up a "pause" menu. If the title overlay of the pause menu happens to hash to the same value as the background that it replaced, that one tile of the pause menu title won't appear. Next frame, it still won't appear, because again the hash value hasn't changed. Until something happens to actually change the title or make it disappear, the glitch will persist.
The "fix" will be to do GUI overlays in translucency and keep the background animating somehow to prevent cache misses from sticking around, but it's an ugly hardware hack that will force software workarounds.
EdvardS - Thursday, July 3, 2014 - link
What if the CRC is 64 bit for each small tile? Quite overkill and very hard to break.mkozakewich - Sunday, July 6, 2014 - link
If the pause screen fades in, wouldn't that change the image data enough that it would generate entirely different CRCs for each frame until the animation ended?At any rate, my rule of thumb would be that if it doesn't happen more often than a keyframe is dropped in a video, it'll be fine.
Krysto - Thursday, July 3, 2014 - link
I'd like you guys to do more 30x GFX loops, that how whether these GPU's only prop up high numbers at first, but then quickly get throttled. From what I noticed Imagination is the only one that doesn't throttle in that test. But I'm curious to see if K1 and T760 do.