ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM ESTTricks of the Trade: Transaction Elimination and Frame Buffer Compression
While we have spent some time covering various techniques ARM uses to improve efficiency in Midgard, we wanted to spend a bit more time talking about two specific techniques in general that we find especially cool: transaction elimination and frame buffer compression.
Going back once again to what we said earlier about rendering and power efficiency, any rendering work ARM can eliminate before it’s completed not only improves performance by freeing up resources, but it also frees up power by not having to spend it on said redundant work. This is especially the case for anything that wants to hit system memory, as compared to the on-die caches and memories available to the GPU, system memory is slow and expensive to operate from a power perspective.
For their final two tricks then, having already eliminated as much rendering work as possible through other means, ARM’s last tricks involve minimizing the amount of data from rendered tiles and pixels that needs to hit system memory. The first of these tricks is Transaction Elimination (TE), which is based on the idea that if a scene (or parts of it) do not change, then it makes no sense to spend power and bandwidth rewriting those identical screen portions.
![]()
To accomplish this, ARM relies on their tiling system to break down the scene for them, and from there they can begin comparing tiles that are waiting for finalization (ROP/blending) to the tiles that are already in the frame buffer from the previous frame. Using a simple cyclic redundancy check to compare the tiles, if the tile to be rendered is found to be identical to the tile already there, the tile can be skipped and the memory bandwidth saved. Altogether of all of ARM’s various tricks, this is among the simplest conceptually.
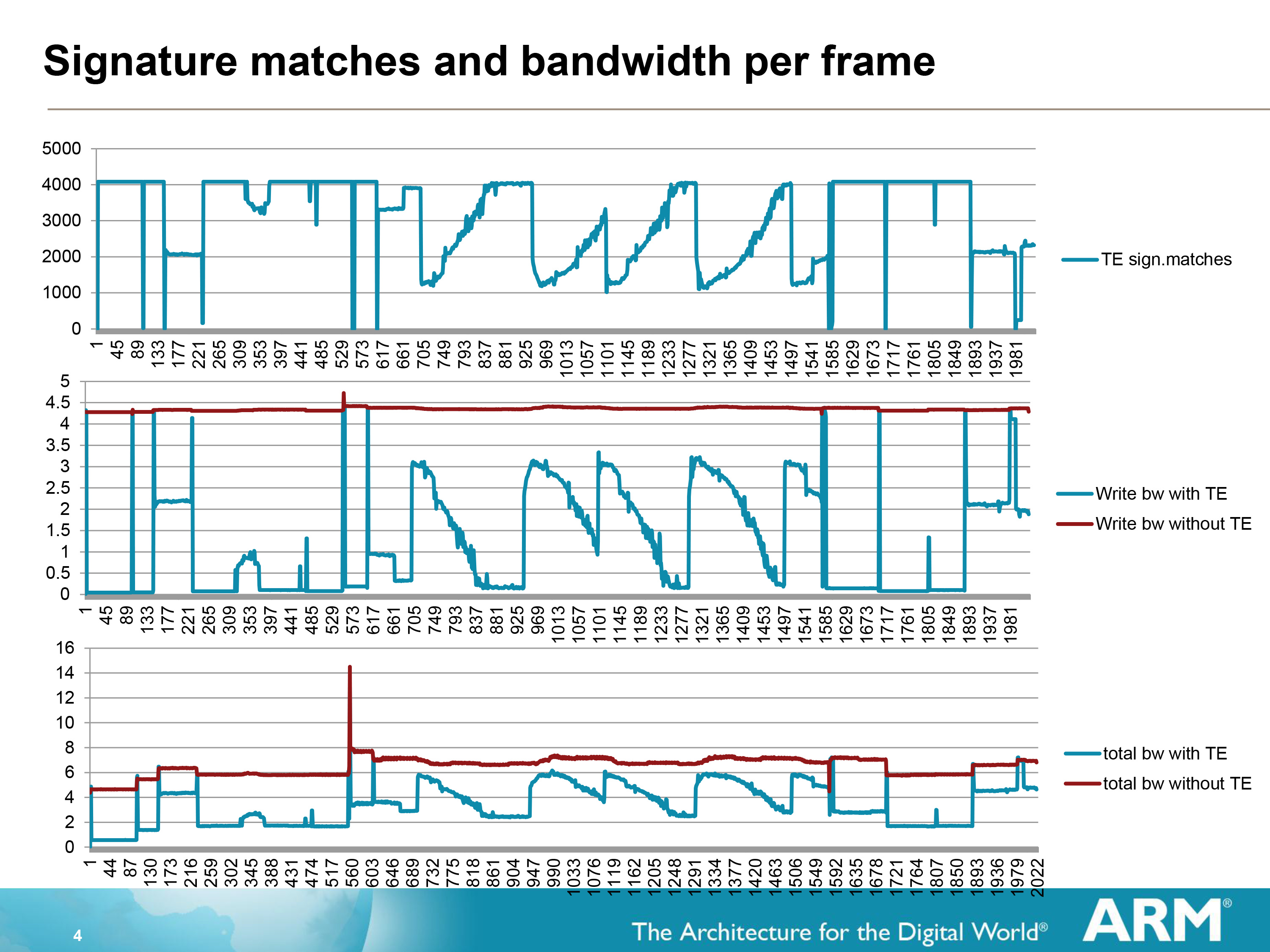
The effectiveness of Transaction Elimination in turn depends on the content. A generally static workload such as a movie will have a high degree of redundancy overall (notably when the camera is not moving), while a game may have many moving elements but will still have redundant elements that can be skipped. As a result ARM can save anywhere between almost nothing and over 99% for a highly static workload, with the average more than offsetting the roughly 1.5% overhead from computing and comparing the CRCs.
Of course Transaction Elimination does have one drawback besides its low overhead, and that is CRC collisions. During a CRC collision a pair of tiles that are different will compute to the same CRC value, and as such Transaction Elimination will consider them identical and throw away the new tile. With a standard CRC value being 64bits, such a collision is rare but not impossible, and indeed will statistically occur sooner or later. In which case Transaction Elimination has no fallback method; it is judge, jury, and executioner as it were, and the new tile will be lost.
As a result Transaction Elimination is interestingly imprecise in a world of precision. When a collision occurs the displayed tile will be wrong, but only for as long as there is a collision, which in turn should only be for 1 frame, or 1/60th of a second.
Moving on, when worse comes to worse and ARM does need to write a new tile, on the Mali-T700 series GPUs they can turn to ARM Frame Buffer Compression (AFBC) to minimize the amount of memory bandwidth they spend on that operation. By using a lossless compression algorithm to write out and store a frame, memory bandwidth is saved on both the writing of the frame and in the reading of it.
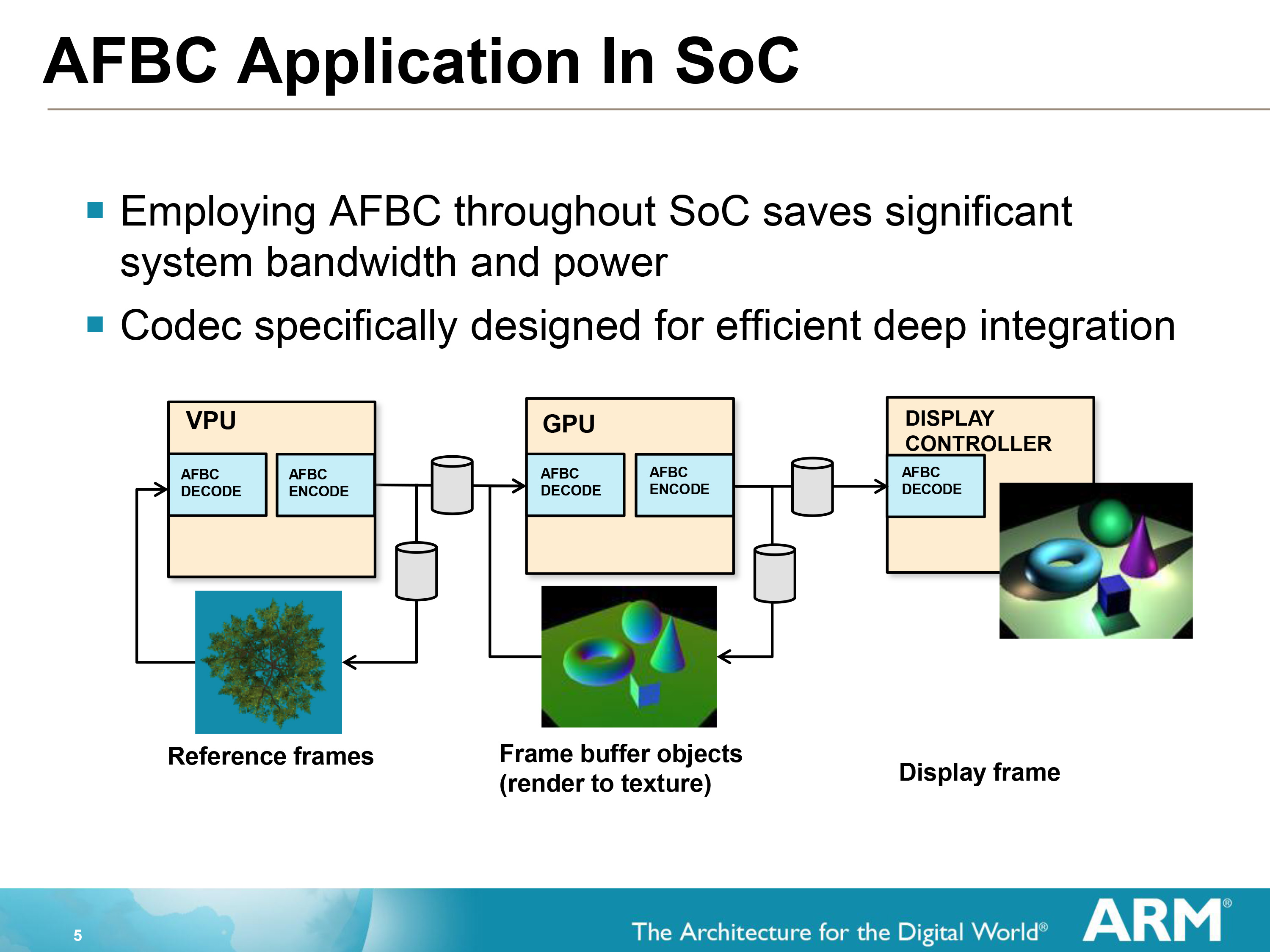
AFBC requires that both the GPU and the Display Controller support the technology, as the frame remains compressed the entire time until decompressed for display/consumption. Interestingly this means that the GPU needs to be able to compress as well as decompress, as it can reuse its own frames either in frame buffer objects (where a frame is rendered to a texture) or in Transaction Elimination. This becomes a secondary vector of saving bandwidth since it results in similar bandwidth savings for the frame even if the frame is never touched by the display controller itself. A similar principle applies to ARM’s video decoders (VPUs) which can use AFBC to compress a frame before shipping it off to the GPU.
On that note, it’s worth pointing out that while AFBC is an ARM technology, for interoperability purposes ARM does license it out to other display controller designers. ARM puts together their own display controllers, but because SoC integrators can use one of many display controllers it’s to ARM’s own benefit that everyone else be able to read AFBC as well as ARM can.








66 Comments
View All Comments
darkich - Friday, July 4, 2014 - link
You guys are missing the fact that Snapdragon 805 can reach a much higher memory bandwidth than Tegra K1.TheJian - Saturday, July 5, 2014 - link
But it still loses to K1 in most gpu stuff (all?). You're forgetting AMD/NV have had 20yrs of trying to figure out how to get the most they can from bandwidth for gaming. The devs have had that long working with their hardware also (game devs I mean). Everyone else has to play catch up here for years as they've never had to do anything game wise until last year or so as android etc gaming pumped up a bit.That is why you see ZERO Qcom optimized games (or did I miss one?) :) It's easier to optimize for a chip you already know inside out (amd/nv). I even went to Qcom's gaming page just to see if there were any games they had on their list that were REQUIRING snapdragon to see xx effects etc. There were none last I checked. All the games are just on googleplay with no snapdragon mention (like on NV games they say THD, and these games look quite a bit better than the regular versions) as they appear to work on ALL players chips. Google seems to be realizing K1 is where you want to be on gpu's at least for gaming centric stuff/automotive and I'd expect devs to continue to favor NV for optimizations as they don't need to learn a thing about k1 it's KEPLER which they've already spent 2yrs+ playing with (probably longer as they get dev versions long before we get a retail card so games can be made/optimized for them by the time they hit).
At 20nm xbox360/ps3 will be left behind as new games keep getting made on mobile. If you're not on xbox1/ps4 you'll be buying some cheap 20nm console box that has cheap games ($2-20 vs. $60 for xbox1/ps4) and as good or better graphics than last gen xbox360/ps3. GDC 2013 & 2014 surveys show devs are already massively making games for mobile and as 20nm kicks in everyone has K1 power levels or more. These android consoles/tv's etc will have more tricks than those ancient consoles so you should be able to get much better gaming experience on them for $100-200. The games pricing alone is a draw for poor people. With the ports happening right an left now of quality PC/console games and super cheap pricing there is even more reason to run to mobile for poor people who never played them before (half-life2, trine2, Serious Sam3BFE, none sold more than 11mil or so). There are a billion android users and most clearly have played none of this stuff even the console ports like Final Fantasy games, GTA games etc (on or off PC also doesn't matter) haven't been played by more than 10mil or so combined each. Lost of great stuff for poor people to pick up for under $10 in ports until the REAL new games for mobile hit this xmas/next xmas. All of the stuff the dev surveys show they've been working on will hit this year or next, and they are not angry birds games.
przemo_li - Tuesday, July 8, 2014 - link
Alternative view on Google stance:Nvidia is just first vendor that allowed them to show more features than are possible on Apples A7.
(Mobile-only vendors are not interested in full OpenGL...)
TheJian - Sunday, July 6, 2014 - link
If they're worried about lawsuits (odd they'd say that without merit), they must have had their lawyers tell them they'd be sued due to stealing tech that is probably from AMD/NV. DMCA takedowns, completely closing the kimono so to speak shows they are afraid for good reason. It isn't just competitor crap as nobody else is afraid of that it seems. The same tricks are being used by almost everyone to a large degree. So it seems to me they clearly owe someone some money and don't want to pay. They will probably show their details once they remove that stuff from a future gen soc or never I guess if they just can't remove it for some reason :)mczak - Thursday, July 3, 2014 - link
You could add Intel HD graphics (baytrail) though. Also quite interesting architecture-wise imho.btw some small correction wavefront size for amd (gcn) is 64, not 16 (I think this was wrong on older anandtech articles too). The simd size is 16 indeed but the same instruction is executed for 4 clocks always (on 16 different elements of the wavefront each clock).
mczak - Thursday, July 3, 2014 - link
Here's actually an explanation how the wavefront size of 64 works for gcn:http://devgurus.amd.com/thread/168154
Achtung_BG - Thursday, July 3, 2014 - link
My first touch phone is black LG Viewty in 2008 with Mali GPU :) :) :) If you have new article for android extention pack comparison with full Open GL will be very intrasting.Jedibeeftrix - Thursday, July 3, 2014 - link
yes please.i'd like to know:
1. how long until the AEP is rolled back into what will be OpenGL ES 4.0
1.1. whether it represents a subset of an existing OpenGL full-fat version (eg 4.4)
2. how this compares to DX 11.2 feature wise
2.1. whether AEP will be expanded in OpenGL ES 4.0 to make it broadly DX 11.2 compliant
przemo_li - Tuesday, July 8, 2014 - link
1) Never. (Though, separate extensions, can get into ES. AEP is just thin bundle over many other extensions)1.1) Yes. OpenGL 4.x is still capable of running AEP code.
2) DX11.2 is single vendor en-devour currently... (And You really should compare to F(eature)L(evel)11_2).
2.1) WHY?
Why on earth You need all those things?
Industry move in different direction. (Mantle, DX12, Metal, AZDO)
Doing stuff efficiently is new mantra now.
Adding more stuff from DX FL11_2 (Yes if You talk about features You MUST use F(eature)L(evels)!!!), would only complicate things for OpenGL ES.
We need AZDO.
Kevin G - Thursday, July 3, 2014 - link
I can see Qualcomm's concerns about a shader arms race in mobile: it has already happened on the CPU side without much benefit to the consumer. However, with the explosion in screen resolution in tablets, a spec race here would have a more tangible benefit for consumers. It sitll boggles my mind that a retina iPad has 50% more pixels and a slower GPU than my desktop system with a 1080p monitor driven by a GTX 770. My sole concern would be temperatures and power consumption.Well if Qualcomm isn't going to disclose the information, how much can be implied from driver information? Qualcomm purchased the mobile Radeon drivision from AMD back in 2009 and then came up with the anagram Adreno. If they're still using a design based upon what they got form AMD, it'd be reflective in similar drivers. If they've come up with a new architecture, it too would be evident in radically different drivers. The details would be lacking of course but some generalities could be made.