Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
When it comes to our coverage of SoCs, one aspect we’ve been trying to improve on for some time now is our coverage and understanding of the GPU portion of those SoCs. In the PC space we’re fortunate that there are just three major players – Intel, NVIDIA, and AMD – and that all three of them have over the years learned how to become very open and forthcoming about their GPU architectures. As a result we’ve had a level of access that has allowed us to better understand PC GPUs in a way that in earlier times simply wasn’t possible.
In the SoC space however we haven’t been so fortunate. Our understanding of most SoC GPU architectures has not been nearly as deep due to the fact that SoC GPU designers have been less willing to come forward with public details about their architectures and how those architectures have evolved over the years. And this has been for what’s arguably a good reason – unlike the PC GPU space, where only 2 of the 3 players compete in either the iGPU or dGPU markets, in the SoC GPU space there are no fewer than 7 players, all of whom are competing in one manner or another: NVIDIA, Imagination Technologies, Intel, ARM, Qualcomm, Broadcom, and Vivante.
Some of these players use their designs internally while others license out their designs as IP for inclusion in 3rd party SoCs, but all these players are in a much more competitive market that is in a younger place in its life. All the while SoC GPU development still happens at a relatively quick pace (by GPU standards), leading to similarly quick turnarounds between GPU generations as GPU complexity has not yet stretched out development to a 3-4 year process. As a result of SoC GPUs still being a young and highly competitive market, it’s a foregone conclusion that there is still a period of consolidation ahead of us – not unlike what has happened to SoC integrators such as TI – which provides all the more reason for SoC GPU players to be conservative about providing public details about their architectures.
With that said, over the years we have made some progress in getting access to the technical details, due in large part to the existing openness policies of NVIDIA and Intel. Nevertheless, as two of the smaller players in the mobile GPU space this still leaves us with few details on the architectures behind the majority of SoC GPUs. We still want more.
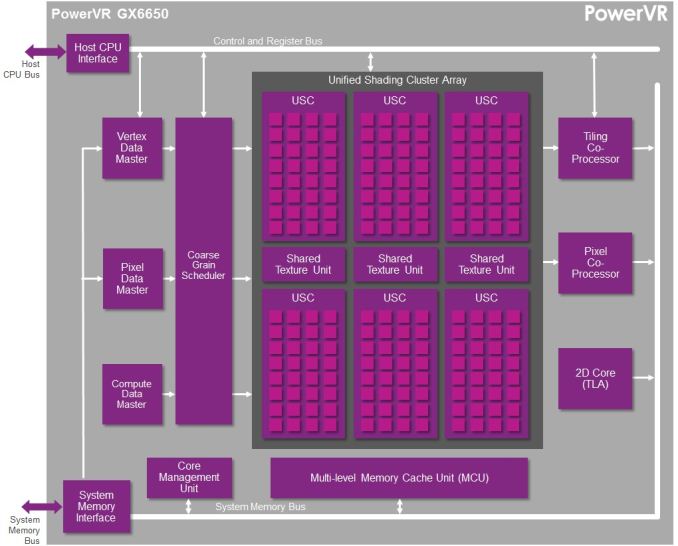
This brings us to today. In what should prove to be an extremely eventful and important day for our coverage and understanding of SoC GPUs, we’d like to welcome Imagination Technologies to the “open architecture” table. Imagination chosen to share more details about the inner workings of their Rogue Series 6 and Series 6XT architectures, thereby giving us our first in-depth look at the architecture that’s powering a number of high-end products (not the least of which is all of Apple’s current-gen products) and descended from some of the most widely used SoC GPU designs of all time.

Now Imagination is not going to be sharing everything with us today. The bulk of the details Imagination is making available relate to their Unified Shading Cluster (USC) shading block, the heart of the Series 6/6XT GPUs. They aren’t discussing other aspects of their designs such as their geometry processors, cache structure, or Tile Based Deferred Rendering system – the company’s secret sauce and most potent weapon for SoC efficiency – but hopefully one day we’ll get there. In the meantime we will have our hands full just taking our first look at the Series 6/6XT USCs.
Finally, before we begin we’d like to thank Imagination for giving us this opportunity to evaluate their architecture in such great detail. We’ve been pushing for this for quite some time, so we’re pleased that this is coming to pass.
Imagination is publishing a pair of blogs and pseudo whitepapers on their website today: Graphics cores: trying to compare apples to apples, and PowerVR GX6650: redefining performance in mobile with 192 cores. Along with this they have also been answering many of our deepest technical questions, so we should have a good handle on the Rogue USC. So with that in mind, let’s dive in.








95 Comments
View All Comments
Scali - Monday, February 24, 2014 - link
"the alternative to DirectX is OpenGL. Is it more suited for TBDR architecture than "brute force" ones?"In theory, D3D used to be more suited to TBDR than OpenGL, because it had explicit BeginScene() and EndScene() markers. But those have been dropped after D3D9.
I can't really think of anything off the top of my head that would make one API more suited than the other these days. They're both very similar: just bind your textures/buffers/shaders, update the constants, and fire off your geometry.
"How is PowerVR going to fight against an architecture as flexible as nvidia ones that can also be used for CUDA computing and thus being adopted into markets (and for other tasks) PowerVR cannot with their current architecture?"
PowerVR supports OpenCL, so they too can do the GPGPU-game. It all depends on who delivers the best package in terms of features, performance, power usage, etc.
Jhwzz - Tuesday, February 25, 2014 - link
>Again, as someone altready asked, tile based rendering was used on the desktop but was soon>abandoned as it could not give any real advantages over the raw power of other architectures
>that grew much faster that what PowerVR could optimize their algorithms, making tile based
>rendering less and less profitable. What makes that scenario different that what we are
> witnessing in this period where mobile resolutions are growing to be even bigger than desktop
> monitors and that games complexity is gonig to increase for the arrival of these really powerful
>GPUs (K1 in primis)?
It is a common misconception that PowerVR's desktop parts where not competitive or had compatibility problems. The last card they produced, the Kyro II was actual very competitive with the offerings from both NVidia and ATi. The claims of incompatibility where largely unfounded marketing FUD from competitors, with later drivers running the majority of content without problems. Further they did not leave the market because they could not compete on performance, instead their partner at the time, STM, decided to pull out of the market for unstated reasons, although this was most likely due to them not being able to invest the amount of money they needed to in order to take the high ground.
Mobile is VERY different to desktop space, NV and ATi where able to brute force their way to the top as both power consumption and memory bandwidth had extremely wide envelopes, this is not the case in mobile space. In Kyro II PowerVR had demonstrated that they were able to compete with considerable higher specification part (for clock & memory BW) from both NV and AMD, with considerably lower memory BW and power requirements. Although NV and AMD have evolved so have PowerVR, as such there is no reason to assume that they don't still have advantages.
>It seems PowerVR is behaving a bit like 3DFx did at the time, till it died. They were using their
>advanced but old technology to the exterme, so they rendered at 16bit instead of 32, used 16bit
>Zbuffer instead of 24 and many more "tricks" that were forced to try to hide what was quite
>clear: 3DFX didn't have the right architecture to compete with new companies like nvidia
> and ATI that started their story with the right step and much more powerful architectures
> (TNT2 simply destroyed Voodoo3 under all points, and beware, I was an Voodoo3 unfortunate > owner).
This simply makes no sense in the context of the market these cores are being target at. At the fundamental level the primary API currently used in mobile is OGLES2.0 which does not mandate anything higher than FP16 within fragment shaders. This means that the vast majority of current mobile content only use FP16 in fragment shaders, in these circumstances do you think it make sense to through area at higher precision paths? Of course it doesn’t! Further it’s not like the PowerVR architecture looks like slouch at FP32.
At the end of the day they truth will only be seen in benchmark in actual devices, not in marketing claims and FUD from various companies.
Jhwzz - Tuesday, February 25, 2014 - link
BTW you do realise that NV run many of these benchmark at 16 bit Z and 16 bit frame buffer don't you? They do thsi because the become even less comeptitive when forced to use 32 bits. So who is actually using old "technology" to hide real deficiencies in thir architectures?MrSpadge - Saturday, March 1, 2014 - link
If you can't see a difference due to using 16 bit somewhere along the rendering path, then it's actually the smart thing to do. It saves power, which can be better used elsewhere (higher clocks). Well, that was actually 3DFX's argument for why Glide with 16 bit + dithering was the smart choice back then. But "they've got the bigger bits" won (along with other advantages of the early nVidias).MrPoletski - Sunday, March 9, 2014 - link
I tmight be the smart thing to do, but when it's in a benchmark that's supposed to be at 32 bits then I call that cheating!allanmac - Monday, February 24, 2014 - link
If a new GPU architecture "deep dive" doesn't include the number of registers per multiprocessor then it's bordering on worthless.Both Intel, AMD and NVIDIA publish these numbers so the other mobile GPU vendors should as well.
Please dig up these numbers since then we can begin to compare these next gen mobile GPUs.
I suspect ARM, ImgTech and QCOM simply won't tell you... but you might be able to find the answer through a series of OpenCL tests.
boostern - Monday, February 24, 2014 - link
OpenCL tests on a GPU that isn't even in production? Before you say "test it on the iphone 5S", there is no OpenCL public libraries available on iOs, as far as I know.allanmac - Monday, February 24, 2014 - link
The first option is to ask the vendor.boostern - Monday, February 24, 2014 - link
Yes, maybe :DMrSpadge - Saturday, March 1, 2014 - link
While this is surely important the raw number of registers doesn't tell you that much either. In fact, it could be very misleading. How many registers you need first and foremost depends on the out of order window (in CPUs) or here the number of threads in flight. Which is something they didn't tell us either. Also different cache sizes and latencies would determine how bad it is to run out of register space.