Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
How Rogues Get Executed: Wavefronts & Superscalar ILP
Now that we’ve seen the basic makeup of a single Rogue pipeline, let’s expand our view to the wider USC.
A single Rogue USC is comprised of 16 pipelines, making the design a 16 wide array. This, along with a texture unit, comprises one “cluster” when we’re talking about a multi-cluster (multiple USC) Rogue setup. In a setup with multiple USCs, the texture unit will then be shared among a pair of USCs.
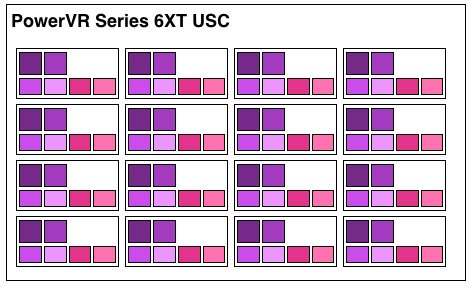
We don’t have a great deal of information on the texture units themselves, but we do know that a Rogue texture unit can fetch 4 32bit bilinear texels per clock. So for a top-end 6 USC part, we’d be looking at a texture rate of 12 texels/clock.
Now by PC standards the Rogue pipeline/USC setup is a bit unusual due to its width. Both AMD and NVIDIA’s architectures are fairly narrow at this level, possessing just a small number of ALUs per shader core/pipeline. The impact of this is that by having multiple ALUs per pipeline in Rogue’s case, there is a need to extract some degree of instruction level parallelism (ILP) out of threads to feed as many ALUs as possible. Extracting ILP in turn requires having instructions in a single thread that have no dependencies on each other that can be executed in parallel. This can be many (but not all) instructions, so it’s worth noting that the efficiency of a USC is going to depend in part on the instructions in a thread. We call this property a superscalar design.
For the sake of comparison, AMD’s Graphics Core Next is not a superscalar design at all, while NVIDIA’s Kepler is superscalar in a similar manner. NVIDIA’s CUDA cores only have 1 FP32 ALU per core, but there are additional banks of CUDA cores that can be co-issued additional instructions, conditions permitting. So Rogue has a similar reliance on ILP within a thread, needing it to achieve maximum efficiency.
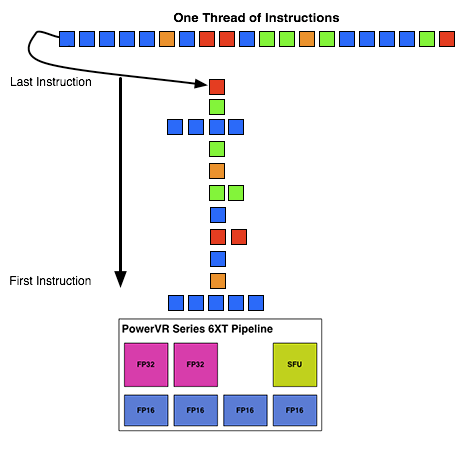
What makes Rogue all the more interesting is just how wide it is. For FP32 operations it’s only 2-wide, but if we throw in the FP16 operations we’re technically looking at a 6-wide design. The odds of having FP16 and FP32 operations ready to co-issue in such a manner is far rarer than having just a pair of FP32 instructions to co-issue, so again Rogue technically is very unlikely to achieve 100% utilization of a pipeline.
That said, the split between FP16 and FP32 units makes it clear that Imagination expects to be using one or the other most of the time rather than both, so as far as the design goes this is not unexpected. For FP32 instructions then it’s a simpler 2-wide setup, while FP16 instructions are going to be trickier as full utilization of FP16 is going to require a full 4 instruction setup (say 4 MADs following each other). The fact that Series 6XT has 4 FP16 units despite that is interesting, as it implies that it was worth the extra die space compared to the Series 6 setup of 2 FP16 units.
With that out of the way, let’s talk about how work is dispatched to the pipelines within a USC. Each pipeline works on one thread at a time, the same as any other modern GPU architecture. Consequently we’d expect the wavefront size to be 16 threads.
However there’s an interesting fact that we found out about the USCs, and that is that they don’t run at the same clockspeed throughout. The ALUs themselves run at the published clockspeed for the GPU, but the frontends that feed them – the decoders and operand collectors do not. Imagination has not specified at what rate they run at, but the only thing that makes sense is ½ the rate of the ALUs. So a 300MHz USC would have its decoder frontend running at 150MHz, etc.
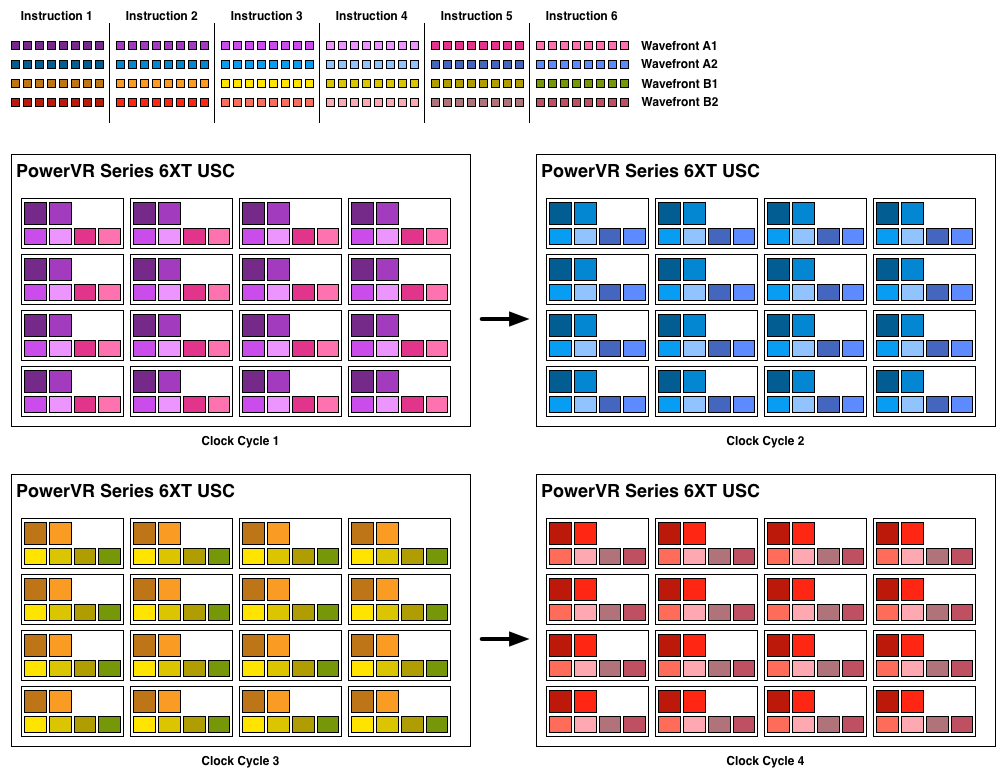
An example of a wavefront executing. Instructions per thread not to scale
Consequently we believe that the size of a wavefront is not 16 threads, but rather 32 threads, executed over 2 cycles of the ALUs. This is not the first time we’ve seen this design – NVIDIA did something similar for their retired Fermi architecture – but this isn’t something we were expecting to see again. But with the idiosyncrasies of the SoC space, this is apparently something that still makes sense. Imagination did tell us that there are tangible power savings from doing this, and since SoC GPUs are power limited in most cases anyhow, this is essentially the higher performance option. Go faster by going slower.
Finally, this brings us to the highest level, the USC array. Each USC in an array receives its own thread to work on, so the number of threads actively being executed will be identical to the number of USCs in a design. For a high-end 6 module design, we’d be looking at 6 threads, whereas for a smaller 2 module design it would be just 2 threads.








95 Comments
View All Comments
Ryan Smith - Monday, February 24, 2014 - link
Aww geeze. I can't believe we put a whole extra row in there...Thank you for pointing that out. It has been corrected (along with everything else you mentioned).
boostern - Monday, February 24, 2014 - link
One question for Ryan: you said that having 12 ROPs is alittle bit strange given the bandwidth constraints in the mobile world. In an earlier article (2011 http://www.anandtech.com/show/4686/samsung-galaxy-... ) anand draw a picture explaing the savings in term of bandwidth of a TBDR architecture: http://images.anandtech.com/reviews/smartphones/sa...Do you think that taking into account this bandwidth savings, those 12 ROPs would make more sense?
Thank you in advance and sorry for my english.
ryszu - Monday, February 24, 2014 - link
The fillrate we have is largely agnostic of the TBDR and its bandwidth savings. It's there for high resolution UIs more than anything else.boostern - Monday, February 24, 2014 - link
Thank you Rys.Are you the Rys of Beyond 3D that works for IMGTec?
ryszu - Monday, February 24, 2014 - link
Guilty as charged!boostern - Monday, February 24, 2014 - link
What an honour :)MrPoletski - Sunday, March 9, 2014 - link
By the way, how does the PowerVR architecture do at cryptocoin mining?MrSpadge - Saturday, March 1, 2014 - link
If the front end runs at half the ALU clock I wonder if the ROPS might also run at half clock? In this case it would make sense to put more of them in.Krysto - Monday, February 24, 2014 - link
From everything I've seen so far, PowerVR5 Series was more ahead of the competition than PowerVR6 Series is right now. In fact Nvidia has already surpassed them, especially when you consider the full OpenGL 4.4 API support, and Adreno and Mali have become very competitive, too, and Mali T760 should also have around 380 Gflops of performance, along with hardware assisted global illumination.I think the days of PowerVR/Apple devices having higher GPU performance than competition are behind us, and it's for the best.
ryszu - Monday, February 24, 2014 - link
Why is it for the best?