Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
How Rogues Get Executed: Wavefronts & Superscalar ILP
Now that we’ve seen the basic makeup of a single Rogue pipeline, let’s expand our view to the wider USC.
A single Rogue USC is comprised of 16 pipelines, making the design a 16 wide array. This, along with a texture unit, comprises one “cluster” when we’re talking about a multi-cluster (multiple USC) Rogue setup. In a setup with multiple USCs, the texture unit will then be shared among a pair of USCs.
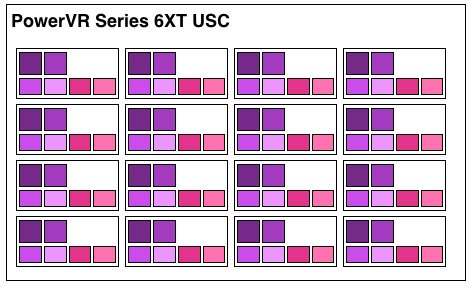
We don’t have a great deal of information on the texture units themselves, but we do know that a Rogue texture unit can fetch 4 32bit bilinear texels per clock. So for a top-end 6 USC part, we’d be looking at a texture rate of 12 texels/clock.
Now by PC standards the Rogue pipeline/USC setup is a bit unusual due to its width. Both AMD and NVIDIA’s architectures are fairly narrow at this level, possessing just a small number of ALUs per shader core/pipeline. The impact of this is that by having multiple ALUs per pipeline in Rogue’s case, there is a need to extract some degree of instruction level parallelism (ILP) out of threads to feed as many ALUs as possible. Extracting ILP in turn requires having instructions in a single thread that have no dependencies on each other that can be executed in parallel. This can be many (but not all) instructions, so it’s worth noting that the efficiency of a USC is going to depend in part on the instructions in a thread. We call this property a superscalar design.
For the sake of comparison, AMD’s Graphics Core Next is not a superscalar design at all, while NVIDIA’s Kepler is superscalar in a similar manner. NVIDIA’s CUDA cores only have 1 FP32 ALU per core, but there are additional banks of CUDA cores that can be co-issued additional instructions, conditions permitting. So Rogue has a similar reliance on ILP within a thread, needing it to achieve maximum efficiency.
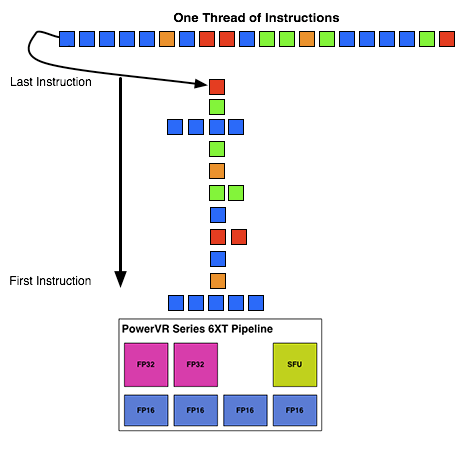
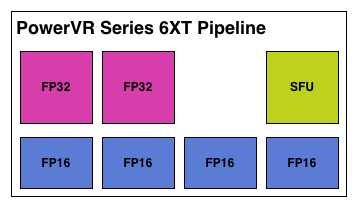
What makes Rogue all the more interesting is just how wide it is. For FP32 operations it’s only 2-wide, but if we throw in the FP16 operations we’re technically looking at a 6-wide design. The odds of having FP16 and FP32 operations ready to co-issue in such a manner is far rarer than having just a pair of FP32 instructions to co-issue, so again Rogue technically is very unlikely to achieve 100% utilization of a pipeline.
That said, the split between FP16 and FP32 units makes it clear that Imagination expects to be using one or the other most of the time rather than both, so as far as the design goes this is not unexpected. For FP32 instructions then it’s a simpler 2-wide setup, while FP16 instructions are going to be trickier as full utilization of FP16 is going to require a full 4 instruction setup (say 4 MADs following each other). The fact that Series 6XT has 4 FP16 units despite that is interesting, as it implies that it was worth the extra die space compared to the Series 6 setup of 2 FP16 units.
With that out of the way, let’s talk about how work is dispatched to the pipelines within a USC. Each pipeline works on one thread at a time, the same as any other modern GPU architecture. Consequently we’d expect the wavefront size to be 16 threads.
However there’s an interesting fact that we found out about the USCs, and that is that they don’t run at the same clockspeed throughout. The ALUs themselves run at the published clockspeed for the GPU, but the frontends that feed them – the decoders and operand collectors do not. Imagination has not specified at what rate they run at, but the only thing that makes sense is ½ the rate of the ALUs. So a 300MHz USC would have its decoder frontend running at 150MHz, etc.
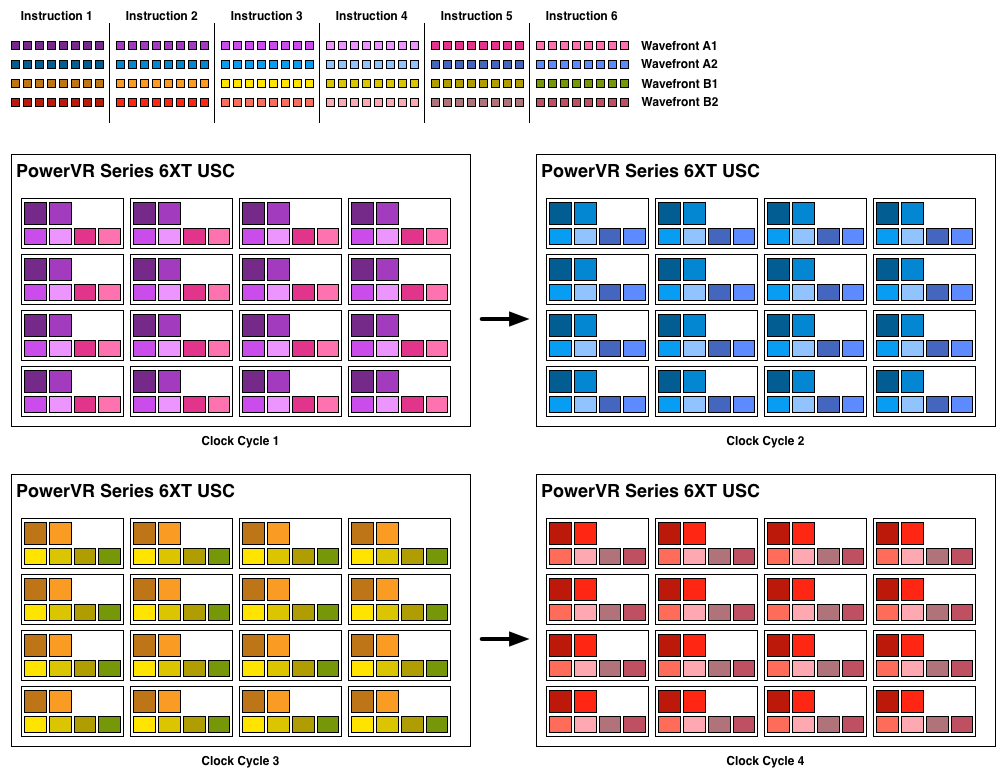
An example of a wavefront executing. Instructions per thread not to scale
Consequently we believe that the size of a wavefront is not 16 threads, but rather 32 threads, executed over 2 cycles of the ALUs. This is not the first time we’ve seen this design – NVIDIA did something similar for their retired Fermi architecture – but this isn’t something we were expecting to see again. But with the idiosyncrasies of the SoC space, this is apparently something that still makes sense. Imagination did tell us that there are tangible power savings from doing this, and since SoC GPUs are power limited in most cases anyhow, this is essentially the higher performance option. Go faster by going slower.
Finally, this brings us to the highest level, the USC array. Each USC in an array receives its own thread to work on, so the number of threads actively being executed will be identical to the number of USCs in a design. For a high-end 6 module design, we’d be looking at 6 threads, whereas for a smaller 2 module design it would be just 2 threads.








95 Comments
View All Comments
errorr - Sunday, March 2, 2014 - link
Re tile based rendering the Mali guys on their blog outlined their thought process on why they chose tile based rendering.Ultimately it is all about power. TBR allows them to avoid memory reads and writes by keeping the color and z-buffer on chip. They also keep the multisample buffer on chip Which allows them to do 16x msaa at very low power cost.
The biggest power hog though is textures which still reside in memory. This means that complex or large textures will basically overwhelm Amy power savings. Basically TBR becomes less efficient when pushed to the max of its capabilities like in many benchmarks.
http://community.arm.com/groups/arm-mali-graphics/...
errorr - Sunday, March 2, 2014 - link
Oh, I also wanted to note that the ARM Mali blog announced that they were going to talk about their shader architecture in an upcoming blog post. The last part in a series about the latest Mali and openGL ES compliance. The previous part talked about tile based rendering and how to get power savings from it.The interesting things I've learned.from the blog include some great stuff not even discussed by imagination.
Mali has a way of comparing the current state of the frame buffer with incoming tiles, if they are identical then the new tile is discarded instead of taking power to write to the frame buffer.
Also, texture compression can save a lot of memory.
The biggest eye opener though was that the way Android handles draw calls means that both CPU and GPU are starved for work and dvfs isn't responsive enough or granular enough to allow for power gating. It seems the problem has to do with screen orientation and android preventing ideal asynchronous Possessing of work.
RAYBOYD44 - Monday, March 3, 2014 - link
uptil I looked at the receipt which had said $9859 , I did not believe that...my... sister had been actualie receiving money in there spare time at their computer. . there aunts neighbour had bean doing this for only about fifteen months and just now took care of the morgage on there appartment and purchased a great Porsche 911 .MrPoletski - Monday, March 10, 2014 - link
DAFUQ?hi.wonjoon - Sunday, May 4, 2014 - link
does this post say that rogue architecture doing some stuff like HyperThreading in Intel? I just wondering I understood in right way.