The Intel Xeon E7 v2 Review: Quad Socket, Up to 60 Cores/120 Threads
by Johan De Gelas on February 21, 2014 6:00 AM EST- Posted in
- IT Computing
- Intel
- Xeon
- Ivy Bridge EX
- server
- Brickland
OpenFoam
Several of our readers have already suggested that we look into OpenFoam. That's easier said than done, as good benchmarking means you have to master the sofware somewhat. Luckily, my lab was able to work with the professionals of Actiflow. Actiflow specialises in combining aerodynamics and product design. Calculating aerodynamics involves the use of CFD software, and Actiflow uses OpenFoam to accomplish this. To give you an idea what these skilled engineers can do, they worked with Ferrari to improve the underbody airflow of the Ferrari 599 and increase its downforce.

The Ferrari 599: an improved product thanks to Openfoam.
We were allowed to use one of their test cases as a benchmark, but we are not allowed to discuss the specific solver. All tests were done on OpenFoam 2.2.1 and openmpi-1.6.3.
Many CFD calculations do not scale well on clusters, unless you use InfiniBand. InfiniBand switches are quite expensive and even then there are limits to scaling. We do not have an InfiniBand switch in the lab, unfortunately. Although it's not as low latency as InfiniBand, we do have a good 10G Ethernet infrastructure, which performs rather well.
So we added a fifth configuration to our testing: the quad-node Intel Server System H2200JF. The only CPU that we have eight of right now is the Xeon E5-2650L 1.8GHz. Yes, it is not perfect, but this is the start of our first clustered HPC benchmark. This way we can get an of idea whether or not the Xeon E7 v2 platform can replace a complete quad-node cluster system and at the same time offer much higher RAM capacity.
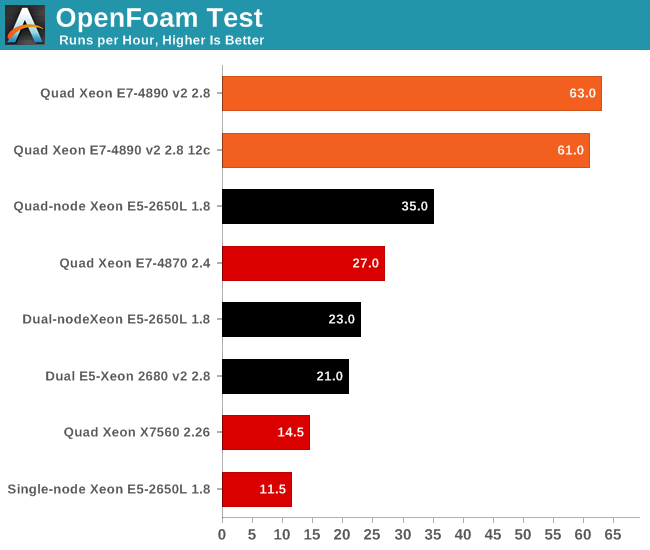
The results are pretty amazing: the quad Xeon E7-4980 v2 runs circles around our quad-node HPC cluster. Even if we were to outfit it with 50% higher clocked Xeons, the quad Xeon E7 v2 would still be the winner. Of course, there is no denying that our quad-node cluster is a lot cheaper to buy. Even with an InfiniBand switch, an HPC cluster with dual socket servers is a lot cheaper than a quad socket Intel Xeon E7 v2.
However, this bodes well for the soon to be released Xeon E5-46xx v2 parts. QPI links are even lower latency than InfiniBand. But since we do not have a lot of HPC testing experience, we'll leave it up to our readers to discuss this in more detail.
Another interesting detail is that the Xeon 2650L at 1.8GHz is about twice as fast as a Xeon L5650. We found AVX code inside OpenFoam 2.2.1, so we assume that this is one of the cases where AVX improves FP performance tremendously. Seasoned OpenFoam users, let us know whether is the accurate assessment.








125 Comments
View All Comments
Kevin G - Monday, February 24, 2014 - link
Even with Itanium's poor performnace, it doesn't stop you from citing the Big Tux experiment to slander overall Linux performance.Brutalizer - Tuesday, February 25, 2014 - link
The reason I cite Big Tux, is because that is the only benchmarks I have seen for Linux running on 64 sockets. If you have other benchmarks, please link to them so I can stop refer to Big Tux.I have never attributed Linux bad performance on Big Tux, because the Itanium has poor performance. I attribute Linux bad performance on Big Tux, because of this: Linux had ~40% cpu utilization on 64 socket Big Tux Itanium server. This means every other cpu idles under full load when using Linux. Is this bad or not? This has nothing to do with Itanium. If Linux ran 64 socket SPARC or POWER - it would still idle ~40%.
Thus, my conclusion of Linux bad performance, is because of the low cpu utilization. It has nothing to do with how fast or slow the hardware. Instead, how good does Linux utilize all resources on large servers? Answer: very bad.
Talking about slandering Linux, have you read this from a prominent Linux kernel developer?
http://vger.kernel.org/~davem/cgi-bin/blog.cgi/200...
"...And here's the punch line, Solaris has never even run on a 1024 cpu system let alone one as big this new SGI system, and Linux has handled it just fine for years. Yet Mr. Bonwick feels compelled to imply that Linux doesn't scale and Solaris does. To claim that Solaris is more ready to scale on large multi-core systems is pure FUD, and I'm saddened to see someone as technically gifted as Jeff stoop to this level..."
Who is slandering who? Is it FUD to say that Linux has scalability problems over 8 sockets? Is it FUD to say that there has never been a 32 socket Linux server for sale? Or is it just that he is not aware of different types of scalability: clusters or SMP servers? Is it just pure ignorance, when he believes a 4096 core Linux cluster can replace a 32 socket SMP server? What do you think? Is it FUD when the ZFS creator claims that Linux does not scale on 32 socket servers, or is it in fact a true claim? Who is FUDing who?
Kevin G - Tuesday, February 25, 2014 - link
Linux scales just as well as Unix on large socket counts. Case in point are IBM's own benchmarks on their p795 systems with 32 sockets, 256 cores and 1024 threads: AIX only beats Linux by a mere 2.7% Source: http://www-03.ibm.com/systems/power/hardware/795/p...I should also point out that your link is 7 years old. Things have changed in the Linux kernel.
hoboville - Monday, February 24, 2014 - link
Well you're right, but it's not as bad for x86 as you make it sound. Systems like TITAN were examples of scale-out compute, if ever there was one. I'll grant it's not the same in terms of what they calculate (Titan is simulation focused and GPU focused) and less on pure RAS and rapid DB access like ERP (not transactional / real time). But that's essentially irrelevant. The point is how they scale in terms of number of nodes and the cost of nodes.Intel's newest chip is cool, but not practical in terms of price competition (why Titan used more Opteron nodes instead of Xeon, for example). What you're focused on is price competition at the ultimate upper end of the spectrum, where SPARC and Power live. And that, in turn, the price of the highest end single system. Intel may be trying to break into that space, but no, it doesn't make sense because x86 wasn't designed for it as an architecture. Their single systems won't compete, yet.
But that's not to say this new Xeon irrelevant. It isn't. It will, however, have problems because of the price-per-performance isn't competitive. In a scale-out design you want more, cheaper nodes and beat the competition by volume. These nodes are just too expensive when you want performance per dollar.
What most mid-to-large companies need is a scalable setup that grows with their business. A lot of IT is bean counting and cost cutting. If you want to start SMP, you start small and tack on additional systems, because your budget people won't let you get a SPARC system or Unix setup. Oracle just doesn't offer systems or prices that are reasonable, and because of this, many businesses that SMP won't give them a second glance. This is where x86 and Xeon fit into the picture, scale out, starting small and building up. But these new systems are asking too much and people aren't going to be interested.
Kevin G - Monday, February 24, 2014 - link
Intel has effectively killed off the Itanium. The original 22 nm Kitson has been scrapped and the successor to Poulson is going to be on 32 nm as well. After that, nothing appears on Intel's roadmap for the chip.HP, the largest Itanium customer, has already announced that their NonStop mainframe line is moving to x86:
Kevin G - Monday, February 24, 2014 - link
Forgot the link: http://h17007.www1.hp.com/us/en/enterprise/servers...Kevin G - Monday, February 24, 2014 - link
"So, instead of you telling me I am wrong, I suggest you just show us links with SMP workloads for the SGI UV2000 server... then you are right, and I am wrong. And I will shut up."United States Post Office running Oracle Data Warehouse software on a SGI UV1000 (the older sibling of the UV2000, still shared memory and cache coherent):
https://www.fbo.gov/index?s=opportunity&mode=f...
SGI and MarkLogic for Big Data:
http://www.v3.co.uk/v3-uk/news/2216603/sgi-and-mar...
I've also found passing references other government (No Such Agency?) installations of a UV2000 installation running Hadoop.
Brutalizer - Tuesday, February 25, 2014 - link
But please, Kevin G, dont you know that Hadoop is a clustered solution? Why do you think people are running clustered database solutiosn as Hadoop on a SGI UV2000 server? Is it because SGI says it is for clustered benchmarks only?And yes, there are clustered databases.
Kevin G - Tuesday, February 25, 2014 - link
Did you not see the link where the USPS is running Oracle workloads on a UV1000? I'll post it again so that you may see: https://www.fbo.gov/index?s=opportunity&mode=f...Kevin G - Tuesday, February 25, 2014 - link
There a couple of reasons why someone would have to run Hadoop on a UV2000: the UV2000 has a large global address space which data could directly reside (ie. no disks access necessary!). If the raw data can reside in 64 TB, performance should be very good. Secondly, Hadoop is free under the Apache license. Traditional database software like Oracle charge a premium the more sockets there are installed on a system. I'd imagine that 256 socket UV2000 system would incur an Oracle licensing fee in the tens of millions of US dollars. So between the choice of free or tens of millions of dollars, most organizations would at least try to work with the free solution.