The Intel Xeon E7 v2 Review: Quad Socket, Up to 60 Cores/120 Threads
by Johan De Gelas on February 21, 2014 6:00 AM EST- Posted in
- IT Computing
- Intel
- Xeon
- Ivy Bridge EX
- server
- Brickland
SAP S&D Benchmark
The SAP SD (Sales and Distribution, 2-Tier Internet Configuration) benchmark is an interesting benchmark as it is a real-world client-server application. It is one of those rare industry benchmarks that actually means something to the real IT professionals. Even better, the SAP ERP software is a prime example of where these Xeon E7 v2 chips will be used. We looked at SAP's benchmark database for these results.
Most of the results below all run on Windows 2008/2012 and MS SQL Server (both 64-bit). Every 2-Tier Sales & Distribution benchmark was performed with SAP's latest ERP 6 Enhancement Package 4. These results are not comparable with any benchmark performed before 2009. We analyzed the SAP Benchmark in-depth in one of our earlier articles. The profile of the benchmark has remained the same:
- Very parallel resulting in excellent scaling
- Low to medium IPC, mostly due to "branchy" code
- Somewhat limited by memory bandwidth
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
Let's see how the quad Xeon compares to the previous Intel generation, the cheaper dual socket systems, and the RISC competition.
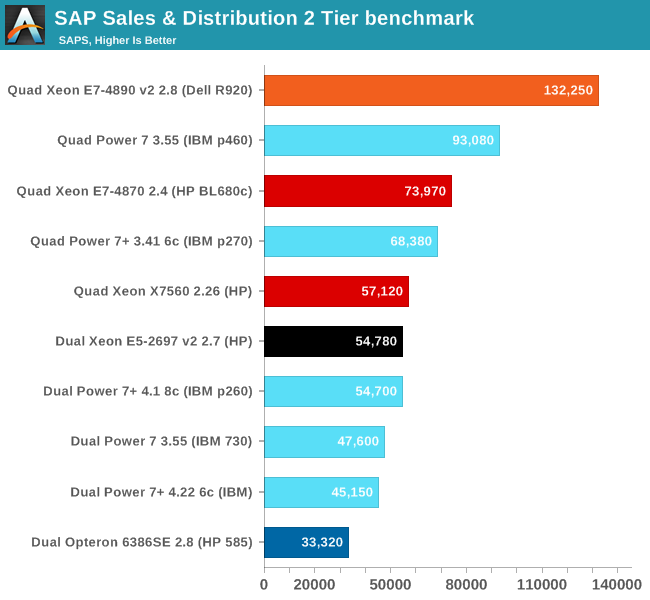
The new Xeon E7 v2 is no less than 80% faster than its predecessor. The nearest RISC competitor (IBM Power 7 3.55) is a lot more expensive and delivers only 70% of the performance. We have little doubt that the performance/watt ratio of the Xeon E7 v2 is a lot better too.
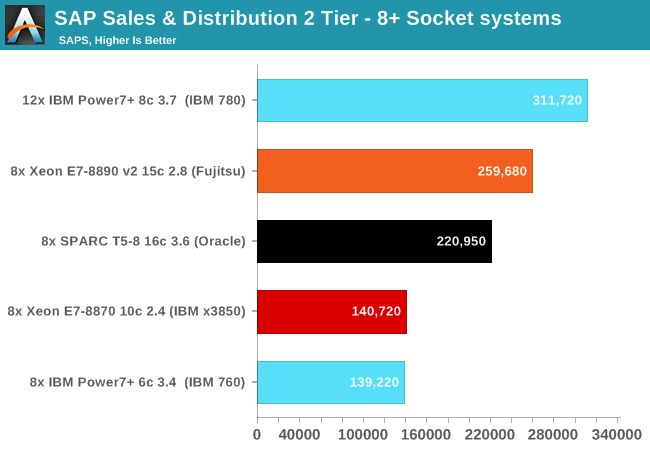
Intel delivers a serious blow to the RISC competition. For about 11 months, the Oracle SPARC T5-8 delivered the highest SAPS of all octal-socket machines. This insanely expensive machine, which keeps 1024 threads in flight (but executes 256 of them) is now beaten by the Fujitsu PRIMEQUEST 2800E. The 240 thread octal Xeon E7-8890 v2 outperforms the former champion of Oracle by about 18%. The SPARC comeback is still remarkable, although we are pretty sure that the Fujitsu server will be less expensive. Even better is you do not have to pay the Oracle support costs.








125 Comments
View All Comments
Brutalizer - Sunday, February 23, 2014 - link
Have you read about the ScaleMP Linux server (it has 8192 cores or even more) in my link above? It also has a shared memory system, running a single Linux kernel image. They solve the scalability problem by using a software hypervisor that tricks Linux into believing it is running on a SMP server, and not a cluster. If you read the post in that link, a programmer writes:"...I tried running a nicely parallel shared memory workload (75% efficiency on 24 cores in a 4 socket opteron box) on a 64 core ScaleMP box with 8 2-socket boards linked by infiniband. Result: horrible. It might look like a shared memory, but access to off-board bits has huge latency...."
Thus, the huge ScaleMP Linux server is only good for workloads where each node runs independent code, with little interaction to other nodes - that is the hallmark of HPC number crunching stuff running on clusters.
@mapesdhs: "...Calling a UV a cluster is just plain wrong..."
Regarding if the SGI UV server is a cluster or not: there is a very litmus test to find out if it is really a cluster, or not. Is the SGI UV server used for HPC workloads or SMP workloads? SGI themselves says it is only for HPC workloads. As does ScaleMP.
If you want to prove I am wrong, and your claim is correct: show us links to customers running large SMP workloads on the SGI UV cluster. Hint: you will not find a counter example. Why?
1) SGI says they are not going to try SMP workloads (which is odd, as there is the really big money)
2) It uses MPI, which is a library used for HPC number crunching. I myself has programmed MPI for scientific computations, and I tell you, that you can not rewrite Oracle Database or DB2 or MySQL using MPI without great effort. MPI is for sending code to nodes for execution. A large SMP server does not need MPI libraries or something, it is just programmed as a usual server.
So, instead of you telling me I am wrong, I suggest you just show us links with SMP workloads for the SGI UV2000 server - which is the easiest thing to settle this question. I have showed links where SGI says their big Altix server is not for SMP workloads, it is only for HPC - which means: cluster. If you can show that many customers are replacing large Unix 32 socket servers with SGI UV2000 servers - then you are right, and I am wrong. And I will shut up.
Have you not thought about why the old mature Unix servers are still stuck at 32 or 64 sockets, whereas Linux servers exists in configurations 1-8 sockets or 100s of sockets - but nothing in between? Answer: the 1-8 socket Linux servers are just ordinary x86 servers, and they are great for SMP workloads such as SAP or ERP or whatever. The 100s socket Linux servers are all clusters. There are no 32 socket Linux SMP servers for sale - and has never been. Linux scales bad on SMP workloads, the maximum is 8-sockets. If you check 8-socket Linux benchmarks, the cpu utilization is quite bad. For isntance SAP benchmarks shows Linux having ~88% cpu utilization whereas Solaris has 99% cpu utilization. Solaris scales much better on as few as 8-socket x86 servers, where Linux has problems. That is the reason Solaris has higher perfomance on SAP benchmarks, although the Linux server used faster CPUs, and faster RAM dimms.
Why does the 32 socket Unix servers cost much more than the largest SGI server configuration? Answer: because SGI is a cluster, consisting of X cheap nodes.
Here is a good example of Linux kernel devs ignorant of scale-out and scale-up:
http://vger.kernel.org/~davem/cgi-bin/blog.cgi/200...
"... And here's the punch line, Solaris has never even run on a 1024 cpu system let alone one as big this new SGI system, and Linux has handled it just fine for years. Yet, ZFS creator Jeff Bonwick feels compelled to imply that Linux doesn't scale and Solaris does. To claim that Solaris is more ready to scale on large multi-core systems is pure FUD, and I'm saddened to see someone as technically gifted as Jeff stoop to this level....Now, this all would be amusing if this were the early 90's and us Linux folk were "just a bunch of silly hobbyists." Yet these Solaris guys behave as if we're still in that era."
He clearly has no clue of SGI being a cluster running HPC workloads, whereas Solaris runs SMP workloads on 32/64 socket servers. In fact, decades ago, there was a 144 socket Solaris server. In 2015, Oracle will release a 16.384 thread server with 64TB RAM. The point is: SPARC is doubling performance every generation, whereas Intel is not. SPARC T4 were the worlds fastest cpu in Enterprise database workloads two years ago, and last years SPARC T5 servers are four times as fast as T4. This year, SPARC T6 will arrive, which will be twice as fast again.
There is no chance in hell Intel will match Unix servers on large workloads. 8-socket Intel x86 servers can never compete with 32 or 64 socket Unix servers.
NikosD - Monday, February 24, 2014 - link
@Brutalizer (and Johan)Very interesting comments, but I would like to ask you, what about Itanium (9500 series) ?
I think that Intel keeps 8+ sockets for Itanium series which are capable of up to 32-socket systems.
I can't really answer if there wasn't Itanium, if Intel could build a 32-socket x86-64 system.
BTW, I can't find Enterprise benchmarks for top 9500 Itanium series, like 9560.
Which is the performance of a 32-socket Itanium 9560 system (for example Superdome 2 or other) compared to Oracle SPARC M5/M6-32 or an IBM equivalent ?
Also would be interesting a direct comparison of an 8-socket Itanium 9560 system with an 8-socket Xeon E7 v2 system, to see the internal competition of the two platforms.
Brutalizer - Monday, February 24, 2014 - link
Itanium has very bad performance, as it is not actively developed anymore. Even back then, Itanium had bad performance. Itanium had better RAS than performance. HP provided the RAS capabitlites from their HP-UX servers (PA-RISC cpus). And now Intel has learned some RAS from HP, and Intel is trying to tuck on RAS onto x86 instead, and killing off Itanium. Intel learned RAS. But the x86 RAS is not good enough yet. They can not replay faulty instructions, can not compare output of several cpus and shut faulty cpus down, etc.But Itanium exists in the 64 socket HP Integrity (or is it Superdome) servers, running HP-UX. This is the Big Tux server, I wrote about.
Intel wants desperately go to the high end 16/32 socket servers, where the big money is. But x86 lacks scalability, and has been stuck at 8-sockets forever. Also, the operating system needs to be mature and optimized for 16 or 32 sockets - Linux is not. Because there are no such large Linux servers, it can not be optimized for 16 or 32 socket SMP servers. Only recently, people have been trying to compile Linux to the old mature Unix servers, with bad results. It takes decades to scale well. Scalability is very difficult. Otherwise Intel would be selling 16 or 32 socket x86 servers raking in the BIG money.
But, this x86 E7 cpu is nice, definitely. But to say it will compete in the high end is ridiculous. You need 32 or 64 sockets for that, and at least 32TB RAM. And you need extreme RAS.
Kebab
NikosD - Monday, February 24, 2014 - link
You seem to describe a complete dead end for Intel.Because if x86 is inherently limited to 8-socket scalability and has no luck with extreme RAS, then Intel's decision was right to invest to another ISA for high end servers, like EPIC.
But if Itanium is a low performance CPU, even with high RAS, then Intel is doomed.
I can't see how could penetrate into the top high end systems where the big money is.
Kevin G - Monday, February 24, 2014 - link
Intel has announced that several major RAS features from Itanium will make its way to x86 systems. The main thing is integrated lock step and processor hot swap. These two features can be found on specific x86 servers that provide the additional logic for these.Similarly, x86 can scale beyond 8 sockets with additional glue logic. This is the same for Itanium and SPARC.
Brutalizer - Tuesday, February 25, 2014 - link
"...Similarly, x86 can scale beyond 8 sockets with additional glue logic. This is the same for Itanium and SPARC...."Yes, there is in fact a 16-socket x86 server released last year by Bullion. It has quite bad performacne, and the cpu utilization is not that good I guess because of the bad perofrmance. If Intel is going to scale beyond 8-sockets, they need to do it well, or nobody is going to use them for SMP work, when they can buy a 8 or 16 socket SPARC or POWER server, with headroom for growth to 32 or 64 sockets.
Kevin G - Tuesday, February 25, 2014 - link
Except you are intentionally ignoring the glue logic that SGI has developed for the UV2000.With Intel phasing out Itanium, their x86 Xeon line is picking up where Itanium left off. It does help that both the recent Itaniums and Xeons are using QPI interconnects as the glue logic developed for one can be used for the other architecture. (I haven't seen this confirmed but I'm pretty sure that the glue logic for the SGI UV1000 was originally intended to be used with Itaniums.)
Brutalizer - Tuesday, February 25, 2014 - link
x86 is not inherently limited to 8-socket scalability. Intel needs to develop techniques to scale beyond 8 sockets - which is very difficult to do. Even if Intel scales above 8-sockets, Intel needs to scale well and utilize all resources - which is difficult. So, with time, we might see 16-socket x86 servers. And in another decade maybe 24 socket x86 servers. But the mature Unix OSes has taken decades to go into 32 socket arena, and they started big, always had big servers as the target. Intel starts from desktop, and trying to venture into larger servers. Intel may succeed given time. But not today.xakor - Tuesday, February 25, 2014 - link
Are you sure 16+ sockets is the only route to SMP workloads? It seems to me Intel is choosing the direction of not increasing socket count but rather core count, what does that sound like in term of feasibility? What can be said about 72 core 3TFlop Xeon Phi behind a large ERP?stepz - Wednesday, February 26, 2014 - link
Xeon Phi is utterly crap at database/ERP workloads. Extracting memory level parallelism is required to get good per-thread performance in database workloads, and you need a pretty good OoO core to extract it. Xeon Phi is designed for regularly structured computation kernels and will be multiple times slower than a big core. You cannot compensate that with more cores either because the workloads do still have scalability limits where you hit into nasty contention issues. To get even to the level of scalability they currently have has taken blood, sweat and tears on all levels of the stack, from the kernel, through the database engine to the application code using the database.