Memory Scaling on Haswell CPU, IGP and dGPU: DDR3-1333 to DDR3-3000 Tested with G.Skill
by Ian Cutress on September 26, 2013 4:00 PM ESTOne of the touted benefits of Haswell is the compute capability afforded by the IGP. For anyone using DirectCompute or C++ AMP, the compute units of the HD 4600 can be exploited as easily as any discrete GPU, although efficiency might come into question. Shown in some of the benchmarks below, it is faster for some of our computational software to run on the IGP than the CPU (particularly the highly multithreaded scenarios).
Grid Solvers - Explicit Finite Difference on IGP
As before, we test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. We iterate through a series of grid sizes, and results are shown in terms of ‘million nodes per second’ where the peak value is given in the results – higher is better.
Two Dimensional:

The results on the IGP are 50% higher than those on the CPU, and it would seem that memory can make a difference as well. As long as 1333 MHz is not chosen, there is at least a 2% gain to be had. Otherwise, the next jump up is at 2666 MHz for another 2%, which might not be cost effective.
Three Dimensional:
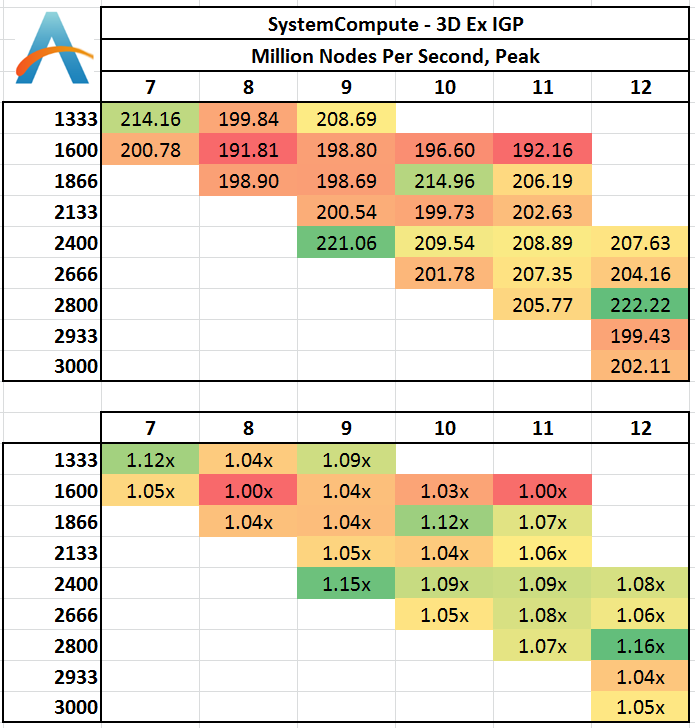
The 3D results seem to be a little haphazard, with 1333 C7 and 2400 C9 both performing well. 1600 C11 definitely is out of the running, although anything 2400 MHz or above affords almost a 10%+ benefit.
N-Body Simulation on IGP
As with the CPU compute, we run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

In terms of a workload that calculates FLOPs, the operational workload does not seem to be affected by memory.
3D Particle Movement on IGP
Similar to our CPU Compute algorithm, we calculate the random motion in 3D of free particles involving random number generation and trigonometric functions. For this application we take the fastest true-3D motion algorithm and test a variety of particle densities to find the peak movement speed. Results are given in ‘million particle movements calculated per second’, and a higher number is better.
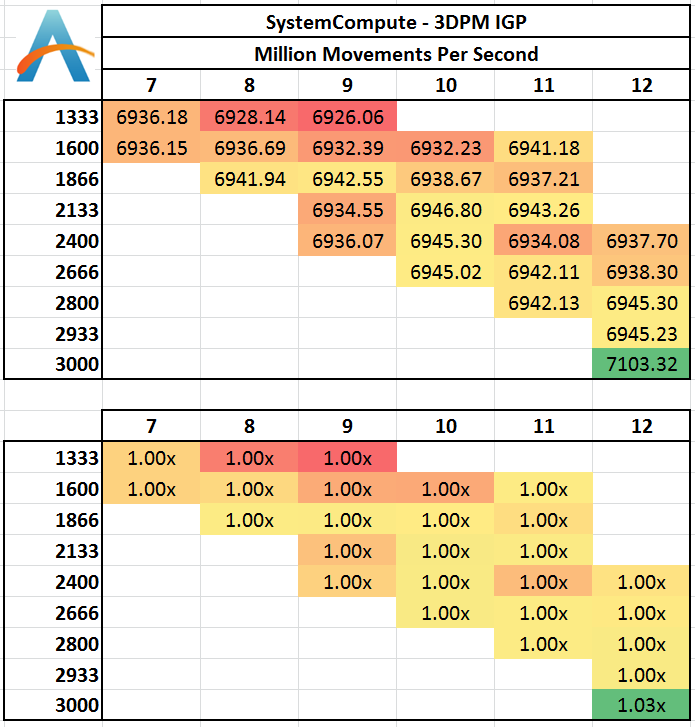
Despite this result being over 35x the equivalent calculation on a fully multithreaded 4770K CPU (200 vs. 7000), again there seems little difference between memory speeds. 3000 C12 gets a small peak over the rest, similar to the n-Body test.
Matrix Multiplication on IGP
Matrix Multiplication occurs in a number of mathematical models, and is typically designed to avoid memory accesses where possible and optimize for a number of reads and writes depending on the registers available to each thread or batch of dispatched threads. He we have a crude MatMul implementation, and iterate through a variety of matrix sizes to find the peak speed. Results are given in terms of ‘million nodes per second’ and a higher number is better.
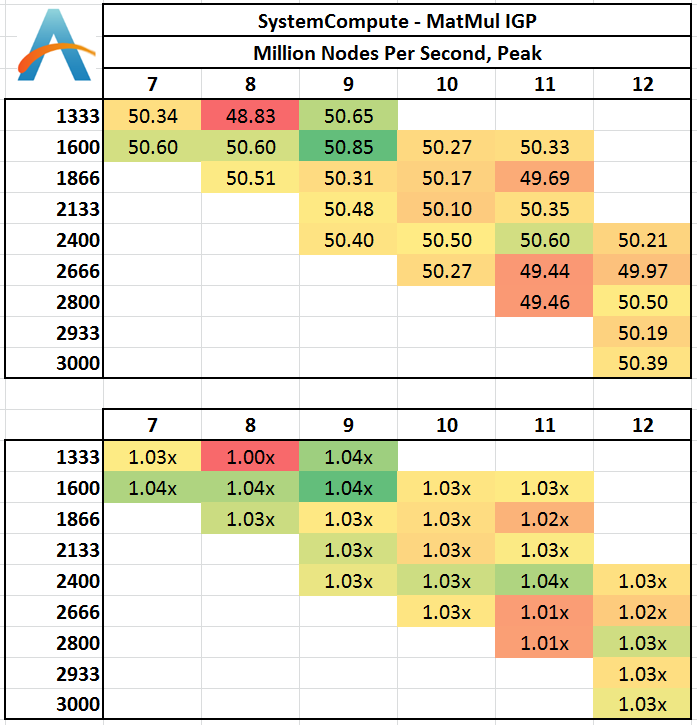
Matrix Multiplication on this scale seems to vary little between memory settings, although a shift towards the lower CL timings gives a marginally (though statistically minor) better result.
3D Particle Movement on IGP
Similar to our 3DPM Multithreaded test, except we run the fastest of our six movement algorithms with several million threads, each moving a particle in a random direction for a fixed number of steps. Final results are given in million movements per second, and a higher number is better.
While there is a slight dip using 1333 C9, in general almost all of our memory timing settings perform roughly the same. The peak shown using our memory kit at its XMP rated timings are presumably more due to the adjustments in BCLK which need to be made in order to hit this memory frequency.








89 Comments
View All Comments
Rob94hawk - Friday, September 27, 2013 - link
Avoid DDR3 1600 and spend more for that 1 extra fps? No thanks. I'll stick with my DDR3 1600 @ 9-9-9-24 and I'll keep my Haswell overclocked at 4.7 Ghz which is giving me more fps.Wwhat - Friday, September 27, 2013 - link
I have RAM that has an XMP profile, but I did NOT enable it in the BIOS, reason being that it will run faster but it jumps to 2T, and ups to 1.65v from the default 1.5v, apart from the other latencies going up of course.Now 2T is known to not be a great plan if you can avoid it.
So instead I simply tweak the settings to my own needs, because unlike this article's suggestion you can, and overclockers will, do it manually instead of only having the options SPD or XMP..
The difference is that you need to do some testing to see what is stable, which can be quite different from the advised values in the settings chip.
So it's silly to ridicule people for not being some uninformed type with no idea except allowing the SPD/XMP to tell them what to do.
Hrel - Friday, September 27, 2013 - link
Not done yet, but so far it seems 1866 CL 9 is the sweet spot for bang/buck.I'd also like to add that I absolutely LOVE that you guys do this kind of in depth analyses. Remember when, one of you, did the PSU review? Actually going over how much the motherboard pulled at idle and load, same for memory on a per DIMM basis. CPU, everything, hdd, add in cards. I still have the specs saved for reference. That info is getting pretty old though, things have changed quite a bit since back then; when the northbridge was still on the motherboard :P
Hint Hint ;)
repoman27 - Friday, September 27, 2013 - link
Ian, any chance you could post the sub-timings you ended up using for each of the tested speeds?If you're looking at mostly sequential workloads, then CL is indicative of overall latency, but once the workloads become more random / less sequential, tRCD and tRP start to play a much larger role. If what you list as 2933 CL12 is using 12-14-14, then page-empty or page-miss accesses are going to look a lot more like CL13 or CL14 in terms of actual ns spent servicing the requests.
Also, was CMD consistent throughout the tests, or are some timings using 1T and others 2T?
There's a lot of good data in this article, but I constantly struggle with seeing the correlation between real world performance, memory bandwidth, and memory latency. I get the feeling that most scenarios are not bound by bandwidth alone, and that reducing the latency and improving the consistency of random accesses pays bigger dividends once you're above a certain bandwidth threshold. I also made the following chart, somewhat along the lines of those in the article, in order to better visualize what the various CAS latencies look like at different frequencies: http://i.imgur.com/lPveITx.png Of course real world tests don't follow the simple curves of my chart because the latency penalties of various types of accesses are not dictated solely by CL, and enthusiast memory kits are rarely set to timings such as n-n-n-3*n-1T where the latency would scale more consistently.
Wwhat - Sunday, September 29, 2013 - link
Good comment I must say, and interesting chart.Peroxyde - Friday, September 27, 2013 - link
"#2 Number of sticks of memory"Can you please clarify? What should be that number? The highest possible? For example, to get 16GB, what is the best sticks combination to recommend? Thanks for any help.
erple2 - Sunday, September 29, 2013 - link
I think that if you have a dual channel memory controller and have a single dimm, then you should fill up the controller with a second memory chip first.malphadour - Sunday, September 29, 2013 - link
Peroxyde, Haswell uses a dual channel controller, so in theory (and in some benchmarks I have seen) 2 sticks of 8gb ram would give the same performance as 4 sticks of 4gb ram. So go with the 2 sticks as this allows you to fit more ram in the future should you want to without having to throw away old sticks. You could also get 1 16gb stick of ram, and benchmarks I have seen suggest that there is only about a 5% decrease in performance, though for the tiny saving in cost you might as well go dual channel.lemonadesoda - Saturday, September 28, 2013 - link
I'm reading the benchmarks. And what I see is that in 99% of tests the gains are technical and only measurable to the third significant digit. That means they make no practical noticeable difference. The money is better spent on a difference part of the system.faster - Saturday, September 28, 2013 - link
This is a great article. This is valuable, useful, and practical information for the system builders on this site. Thank you!