AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM EST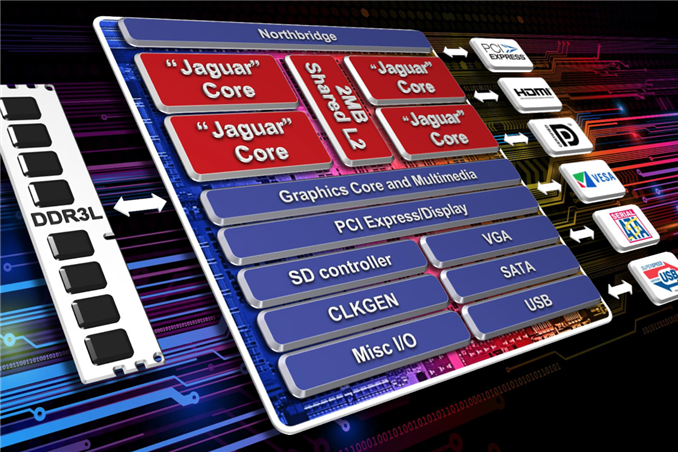
Microprocessor architectures these days are largely limited, and thus defined, by power consumption. When it comes to designing an architecture around a power envelope the rule of thumb is any given microprocessor architecture can scale to target an order of magnitude of TDPs. For example, Intel’s Core architectures (Sandy/Ivy Bridge) effectively target the 13W - 130W range. They can surely be used in parts that consume less or more power, but at those extremes it’s more efficient to build another microarchitecture to target those TDPs instead.
Both AMD and Intel feel similarly about this order of magnitude rule, and thus both have two independent microprocessor architectures that they leverage to build chips for the computing continuum. From Intel we have Atom for low power, and Core for high performance. In 2010 AMD gave us Bobcat for its low power roadmap, and Bulldozer for high performance.
Both the Bobcat and Bulldozer lines would see annual updates. In 2011 we saw Bobcat used in Ontario and Zacate SoCs, as a part of the Brazos platform. Last year AMD announced Brazos 2.0, using slightly updated versions of those very same Bobcat based SoCs. Today AMD officially launches Kabini and Temash, APUs based on the first major architectural update to Bobcat: the Jaguar core.






Jaguar: Improved 2-wide Out-of-Order
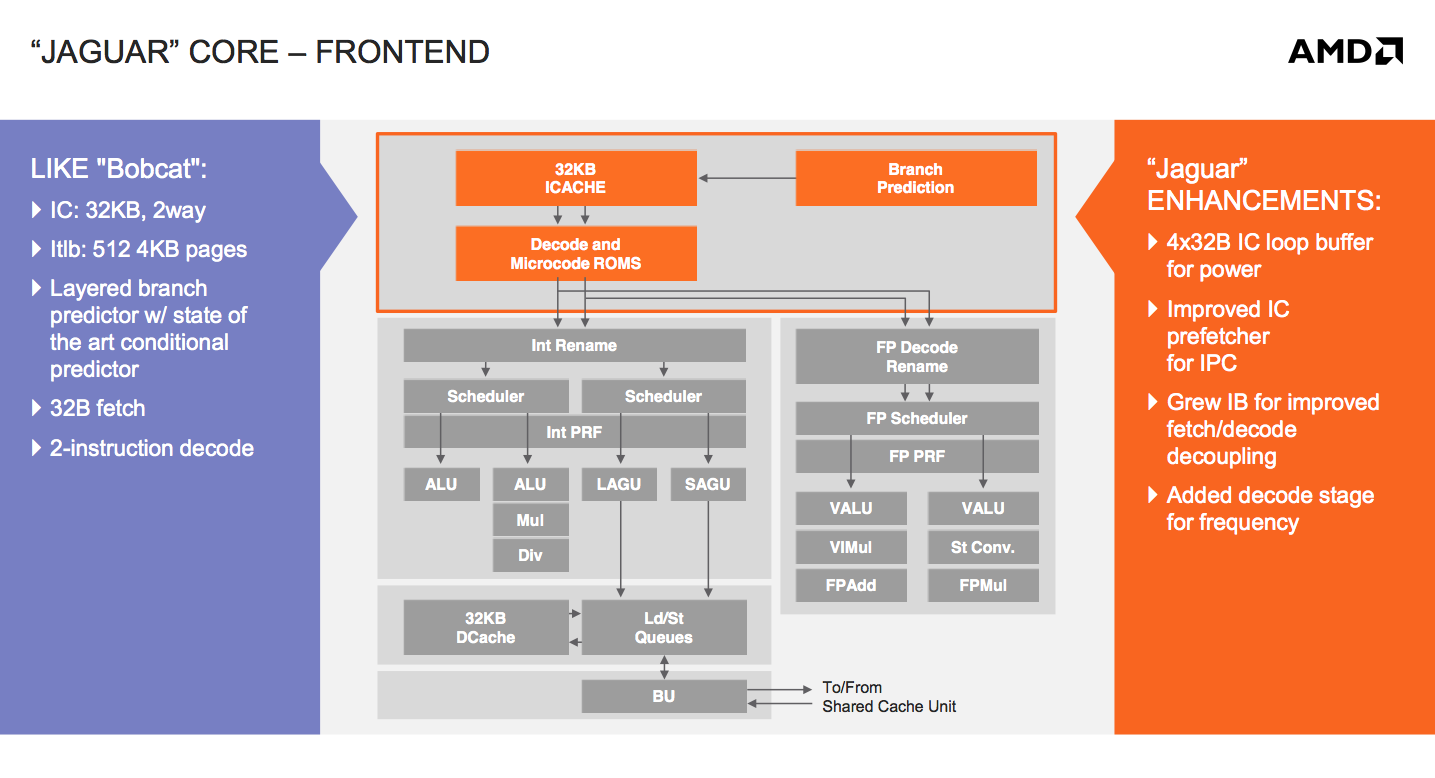
At the core-level, Jaguar still looks a lot like Bobcat. The same dual-issue, out-of-order architecture that AMD introduced in 2010 remains intact with Jaguar. The same L1 cache, front end and execution blocks are all still here. Given the ARM transition from a dual-issue, out-of-order core with Cortex A9 to a three-issue, OoO design with the Cortex A15, I expected something similar from AMD. Despite moving to a smaller manufacturing process (28nm), AMD was very focused on increasing performance within the same TDP or lower with Jaguar. The driving motivator? While Bobcat ended up in netbooks, nettops and other low cost, but thick machines, Jaguar needed to go into even thinner form factors: tablets. AMD still has no intentions of getting into the smartphone SoC space, but the Windows 8 (and Android?) tablet market is fair game. Cellular connectivity isn’t a requirement there, particularly at the lower price points, and AMD can easily be a second source alternative to Intel Atom based designs.
The average number of instructions executed per clock (IPC) is still below 1 for most client workloads. There’s a certain amount of burst traffic to be expected but given the types of dependencies you see in most use cases, AMD felt the gain from making the machine wider wasn’t worth the power tradeoff. There’s also the danger of making the cat-cores too powerful. While just making them 3-issue to begin with wouldn’t dramatically close the gap between the cat-cores and the Bulldozer family, there’s still a desire for there to be clear separation between the two microarchitectures.
The move to a three-issue design would certainly increase performance, but AMD’s tablet ambitions and power sensitivity meant it would save that transition for another day. I should point out that ARM is increasingly looking like the odd-man-out here, with both Jaguar and Intel’s Silvermont retaining the dual-issue design of their predecessors. Part of this has to do with the fact that while AMD and Intel are very focused on driving power down, ARM has aspirations of moving up in the performance/power chain.
The width of the front end is only one lever AMD could have used to increase performance. While it was a pretty big lever that AMD chose not to pull, there are other smaller levers that were exercised in Jaguar.
There’s now a 4 x 32-byte loop buffer for the instruction cache. Whenever a loop is detected, instead of fetching instructions executed in the loop from the L1 I-cache over and over again, they’re serviced from this small loop buffer. If this sounds like a trace cache or decoded micro-op cache, don’t get too excited, Jaguar’s loop buffer is neither of these things. There are no pipeline savings or powered down fetch/decode units. The only benefit to the new loop buffer is the instruction cache doesn’t have to be fired up during every iteration of a buffered loop. In other words, this is a very specific play to reduce power consumption - not to improve performance.
All microprocessors see tons of simulation work before they’re ever brought to market. Even once a design is done, additional profiling is used to identify bottlenecks, which are then prioritized for addressing in future designs. All bottleneck removal has to be vetted against power, cost and schedule constraints. Given an infinite budget across all vectors you could eliminate all bottlenecks, but you’d likely take an infinite amount of time to complete the design. Taking all of those realities into account usually means making tradeoffs, even when improving a design.
We saw the first example of a clear tradeoff when AMD stuck with a 2-issue front end for Jaguar. Not including a decoded micro-op cache and opting for a simpler loop buffer instead is an example of another. AMD likely noticed a lot of power being wasted during loops, and the addition of a loop buffer was probably the best balance of complexity, power savings and cost.
AMD also improved the instruction cache prefetcher, not because of an over abundance of bandwidth but by revisiting the Bobcat design and spending some more time on the implementation in Jaguar. The IC prefetcher improvements are simply AMD doing things better in Jaguar, not being under the same pressure to introduce a brand new architecture as was the case with Bobcat.
The instruction buffer between the instruction cache and decoders grew in size with Jaguar, a sort of half step towards the more heavily decoupled fetch/decode stages in Bulldozer.
Jaguar adds support for new instructions (SSE4.1/4.2, AES, CLMUL, MOVBE, AVX, F16C, BMI1) as well as 40-bit physical addressing.
The final change to the front of Jaguar was the addition of another decode stage, purely for frequency gains. It turns out that in Bobcat the decoder was one of the critical paths limiting maximum frequency. Adding another decode stage simply gave AMD enough wiggle room to hit their frequency targets for Jaguar at 28nm.








78 Comments
View All Comments
GuMeshow - Friday, May 24, 2013 - link
The Embedded G-Series SOCs seem to be exactly Kabini + ECC memory enabled (ex: GX-420CA and A5-5200). This will probably be the cheapest way to get ECC enabled and better performance then Atom, next step up would be Intel S1200KPR + Celeron G1610?.I've been thinking of putting together a Router/Firewall/Proxy/NAS combo ...
R3MF - Thursday, May 23, 2013 - link
HSA?Spoelie - Thursday, May 23, 2013 - link
Is it just me or does the shared L2 cache merely enable the same scaling to 4 cores as bobcat had to 2 cores? There is no "massive benefit" as alluded to in the numbers or discussion.Bobcat has for one thread 0.32 and for two threads 0.61, or a scaling of 95%. (0.64 perfect scaling)
Jaguar has for one thread 0.39 and for four threads 1.50, or a scaling of 96% (1.56 perfect scaling)
The 1% difference could easily be a result of score rounding. I see that a four core bobcat would probably scale worse than jaguar, but the percentages chosen in the table are a bit misleading.
Spoelie - Thursday, May 23, 2013 - link
Of course, drawing such conclusions from a single benchmark is dangerous. If other benchmarks exhibit more code/data sharing and thread dependencies than Cinebench, their numbers might show a more appreciable scaling benefit from the shared L2 cache.tipoo - Thursday, May 23, 2013 - link
I wonder how this compares to the PowerPC 750, which the Wii U is based off of. The PS4 and One being Jaguar based, that would be interesting.aliasfox - Thursday, May 23, 2013 - link
Wii U uses a PPC 750? Correct me if I'm wrong, but the PPC 750 family is the same chip that Apple marketed as the G3 up until about 10 years ago? And IIRC, Dolphin in the GameCube was also based on this architecture?Back in the day, the G3 at least had formidable integer performance -clock for clock, it was able to outdo the Pentium II on certain (integer heavy) benchmarks by 2x. Its downfall was an outdated chipset (no proper support for DDR) and the inability to scale to higher clockspeeds - integer performance may have been fast, but floating point performance wasn't quite as impressively fast - good if the Pentium II you're competing against is nearly the same clock, bad when the PIII and Core Solos are 2x your clockspeed.
Considering the history of the PPC 750, I'd love to know how a modern version of it would compare.
tipoo - Thursday, May 23, 2013 - link
Yes, the Gamecube, Wii, and Wii U all use PowerPC 750 based processors. The Wii U is the only known multicore implementation of it, but the core itself appears unchanged from the Wii, according to the hacker that told us the clock speed and other details.tipoo - Thursday, May 23, 2013 - link
And you're right, it was good at integer, but the FPU was absolutely terrible...Which makes it an odd choice for games, since games rely much more on floating point math than integer. I think it was only kept for backwards compatibility, while even three Jaguar cores would have been better performing and still small.The Nintendo faithful are saying it won't matter since FP work will get pushed to the GPU, but the GPU is already straining to get even a little ahead of the PS360, plus not all algorithms work well on GPUs.
tipoo - Thursday, May 23, 2013 - link
Also barely any SIMD, just paired singles. Even the ancient Xenon had good SIMD.tipoo - Thursday, May 23, 2013 - link
Unchanged on the actual core parts I mean, obviously the eDRAM is different from old 750s.