Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Grid Solvers
For any theoretical evaluation of physical events, we mathematically track a volume and monitor the evolution of the properties within that volume (speed, temperature, concentration). How a property changes over time is defined by the equations of the system, often describing the rate of change of energy transfer, motion, or another property over time.
The volume itself is divided into smaller sections or ‘nodes’, which contain the values of the properties of the system at that point. The volume can be split a variety of different ways – regularly by squares (finite difference), irregularly by squares (finite difference with variable distance modifiers), irregularly by triangles (finite element) to name three, although many different methods exist. More often than not the system has a point of action where stuff is happening (heat transfer at a surface or a surface bound reaction), meaning that some areas of the system are more important than others and the grid solver should focus on those areas (benefits against regular finite difference). This usually comes at the expense of increased computational difficulty and irregular memory accesses, but affords faster simulation time having to calculate 1000 variable distance points rather than 1 million (as an example of a 106 simulation volume). Another point to note is that if the system is symmetrical about an axis (or the center), the simulation and grid chosen is often reduced by a dimension to improve simulation throughput (as O(n) < O(n2) < O(n3)).
Boundary conditions can also affect the simulation – because the volume being simulated is finite with edges, the action at those edges has to be determined. The volume may be one unit of a whole, making the boundary a repeating boundary (entering one side comes out the other), a reflecting boundary (rate of change at the boundary is zero), a sink (boundary is constantly 0), an input (boundary is constantly 1) or a reactive zone (rate of change is defined by kinetics or another property) – again, there are many more boundary conditions depending on the simulation at hand. However as the boundary conditions have to be treated differently, this can cause extended memory reads, additional calculations at various points, or fewer calculations by virtue of constant values.
A final point to make is dealing with simulations involving time. For the scenarios I simulated in research, time could either be dealt with as a pushing structure (every node in the next time step is based on the surrounding nodes ‘pushing‘ the values of the previous time step) or pulling structure (each calculation of the next time step requires pulling a matrix of values from the previous time step), also known as explicit and implicit respectively. By their nature, explicit simulations are embarrassingly parallel but have restricted conditions based on time step and node size – implicit simulations are only slightly parallel, require larger memory jumps but have several fewer restrictions that allow more to be simulated in less time. Deciding between these two methods is often one of the first decisions when it comes to the sorts of simulation I will be testing.
All of the simulations used in this article were described in our previous GA-7PESH1 review in terms of both mathematics and code. For the sake of brevity, please refer back to that article for more information.
Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks.
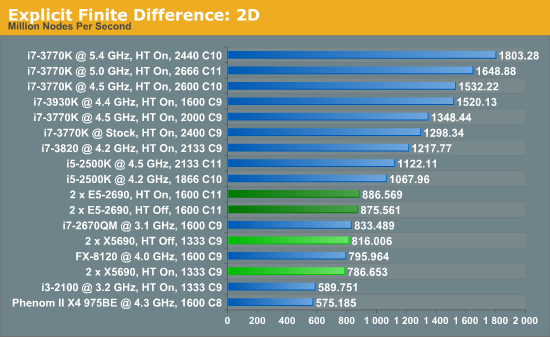
The 6-core X5690s in this situation definitely perform lower than the 8-core E5-2690s, although with the X5690s it pays to have HyperThreading turned off or face 3.5% less performance. Compared to the E5-2690s, the X5690s only perform 8% down for that 25% price difference.
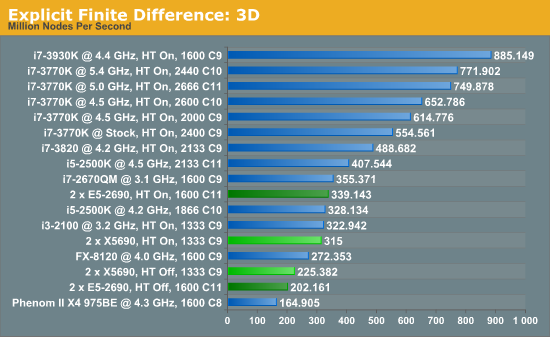
In three dimensions, the E5-2690s still have the advantage, at 7.7% with HT enabled. With HT disabled, the dual X5690 system performs 11.4% better than the Sandy Bridge-E counterparts. The nature of the 3D simulation tends towards a single CPU system performing much better, however.
Implicit Finite Difference (with the Alternating Direction Implicit method)
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks.
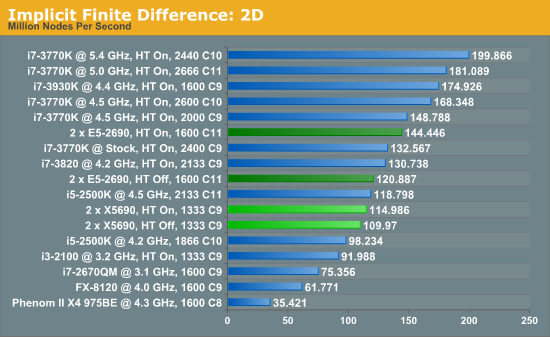
The IPC and increased memory bandwidth of the E5-2690 system comes through here, with the X5690s being 20% slower. The dual CPU nature of the system is still at odds with the coding, as a single i7-3930K at stock should perform similarly.








44 Comments
View All Comments
nadana23 - Sunday, March 10, 2013 - link
It's a pity you didn't read my reply to the previous article...http://www.anandtech.com/comments/6533/gigabyte-ga...
Your memory setup is the constraining factor here.
Add another 8pcs DIMM to your setup next time - you're bandwidth starving the E5-26xx memory controller!
IanCutress - Tuesday, March 12, 2013 - link
How so? Each channel on both processors is populated by one DIMM. Moving to two DIMMs per channel won't make a difference, they're still fed by the same channel.sking.tech - Tuesday, March 12, 2013 - link
The comments about people berating the Titan GPU - the titan is slower in overall performance than the GTX 690 yet they are at the same price point. That's kind of ridiculous. Why would someone pay more for less?ipheegrl - Thursday, May 23, 2013 - link
I would upgrade from Westmere-EP if it weren't for the fact that it was the last line of Xeons that could overclock. Granted, some people want guaranteed stability so overclocking isn't an option, but for budget users who want performance at the price of decreased stability it's a viable solution.