Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
Integer Processing
To measure the integer processing potential of the various CPUs, we'll turn to several different workloads. First up, we have 7z LZMA compression and decompression, again looking at performance with one to four threads. On the next page, we'll look at gcc compiler performance.
Compression
Compression is a low IPC workload that's sensitive to memory parallelism and latency. The instruction mix is a bit different, but this kind of workload is still somewhat similar to many server workloads.
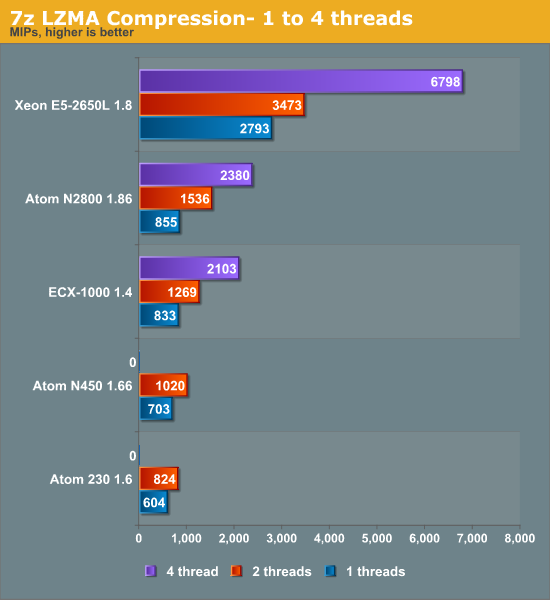
Clock for clock, the out-of-order Cortex-A9 inside the Calxeda EXC-1000 beats the in-order Atom core. A single Cortex-A9 has no trouble beating the older Atoms while likewise coming close to the much higher clocked N2800. The N2800 and ECX-1000 perform similarly.
Decompression
Decompression is pretty branch intensive and depends on the latencies of multiply and shift instructions.
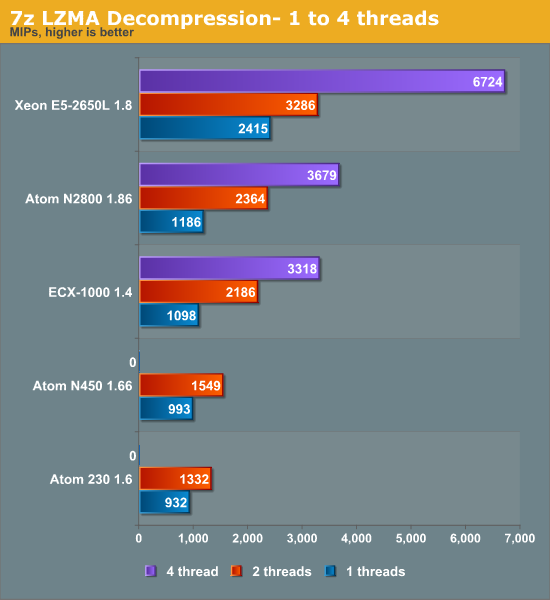
Branch mispredictions are common and the Atom tackles branch mispredictions well with its Simulteanous MultiThreaded (SMT) core. The boost from Hyper-Threading is very large here: a second ARM Cortex-A9 core gives a 52% boost and Hyper-Threading gives a 56% boost. This is very much the exception as far as Hyper-Threading performance is concerned.
Looking at both decompression and compression, it looks like a quad ARM Cortex-A9 is about as fast as one Xeon core (without Hyper-Threading) at the same clock. We need about six Cortex-A9 cores to match the Xeon core with Hyper-Threading enabled. The quad-core ECX-1000 1.4GHz is also close to the dual-core, four-threaded Atom at 1.86GHz. This bodes well for Calxeda as the 6.1W S1240 only runs at 1.6GHz.








99 Comments
View All Comments
tech4real - Thursday, March 14, 2013 - link
Calxeda quotes 6W for the whole SOC. We don't know how much is used for all these uncore stuff. It's possible A9 core only burns around 800mW. Still quite a gap to 1.25W.Wilco1 - Thursday, March 14, 2013 - link
Assuming the 800mW figure is accurate and the uncore power stays the same, then a node would go from 6W to 7.8W - ie. 30% more power for 100% more performance. Or they could voltage scale down to 1.5GHz and get 65% more performance for 5% more power. While a 28nm A15 uses more power in both scenarios, it is also much faster, so perf/Watt is significantly better.tech4real - Thursday, March 14, 2013 - link
1. I guess we have to wait to see if it's really 2X perf from a9 to a15 in real tests. I personally wouldn't bet on that just yet.2. mostly likely the uncore power will increase too. i don't think the larger memory bandwidth will come free.
Wilco1 - Thursday, March 14, 2013 - link
1. We already know A15 is 50-60% faster than A9 per clock (and often more, particularly floating point), so that gives ~2x gain from 1.4GHz to 1.8GHz.2. The uncore power will be scaling down with process while the higher bandwidth demand from A15 will increase DRAM power. Without detailed figures it's reasonable to assume these balance each other out.
tech4real - Thursday, March 14, 2013 - link
then let's wait to see anand benchmarks the future a15 system.also since the real microserver battle is between the future a15 system and 22nm atom system, I am eager to see how it plays out.
Th-z - Wednesday, March 13, 2013 - link
Very interesting article, thanks! This really piques another curiosity: how does latest IBM Power based server fair these days.Flunk - Wednesday, March 13, 2013 - link
It really doesn't sound like the price\performance is there. Also, lack of Windows support makes it useless for those of us who run ASP.NET websites (like the company I work for).It's still nice to see companies trying something different from the standard strategy. Maybe this is be better in a few generations and take the web server market by storm. If we see a Windows Server arm I could see considering it as an option.
skyroski - Wednesday, March 13, 2013 - link
I agree your testing suite's method is good and ok, so you were testing in consideration with hosting providers, fair enough.However on the topic of if you were serving a single site would a standard Xeon be better or ARM based ones? Which - is the case of consideration to FB/Twitter/Google/Baidu etc..., whom are as I have been led to believe by the media this past year, companies that ARM partners are trying to sell this piece of kit to. This test unfortunately cannot tell us.
A quick search on Google on performance impact of VMs yielded a thread in the VMware community forum by a vExpert/Moderator that mentioned expectation of 90% performance, and frankly, no matter how small you think the performance impact of a VM maybe, it is still using up CPU cycles to emulate hardware, that point will remain true no matter how efficient the hypervisor gets.
Secondly, coupled with the overhead of running 24 physical copies of the OS + Apache + DB on a box that would otherwise be running a single copy of the OS + Apache + DB is total overkill (on that topic)
It would be great if you can also test Xeon's req/sec if it ran a single instance so we can see it from a different perspective, as of now as I said, your test is skewered towards hosting providers whom might invest in Calxeda to provide VPS alternatives. But to them (and their client base), the benefit of a VPS is it's portability, which, 24 physical ARM nodes isn't going to provide, so I don't see them considering it as an alternative solution anyway.
skyroski - Wednesday, March 13, 2013 - link
I also want to ask if your Xeon test server's network adapter is capable of and was using Intel VT-c?JohanAnandtech - Thursday, March 14, 2013 - link
It was using VMDq/Netqueue (via VMXnet) but not SR-IOV/VT-c