Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
Integer Processing
To measure the integer processing potential of the various CPUs, we'll turn to several different workloads. First up, we have 7z LZMA compression and decompression, again looking at performance with one to four threads. On the next page, we'll look at gcc compiler performance.
Compression
Compression is a low IPC workload that's sensitive to memory parallelism and latency. The instruction mix is a bit different, but this kind of workload is still somewhat similar to many server workloads.
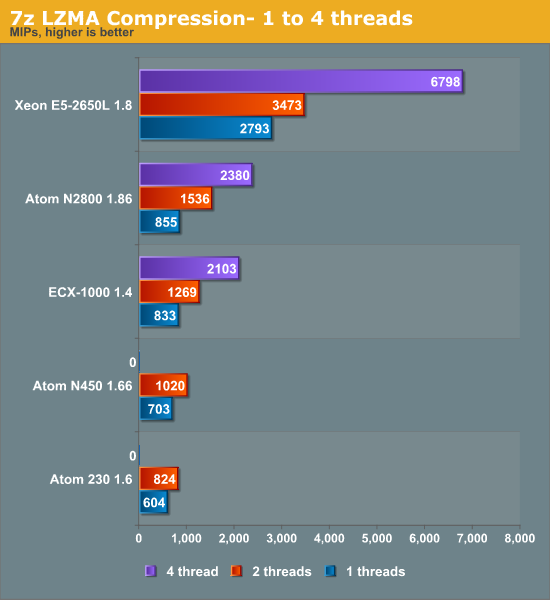
Clock for clock, the out-of-order Cortex-A9 inside the Calxeda EXC-1000 beats the in-order Atom core. A single Cortex-A9 has no trouble beating the older Atoms while likewise coming close to the much higher clocked N2800. The N2800 and ECX-1000 perform similarly.
Decompression
Decompression is pretty branch intensive and depends on the latencies of multiply and shift instructions.
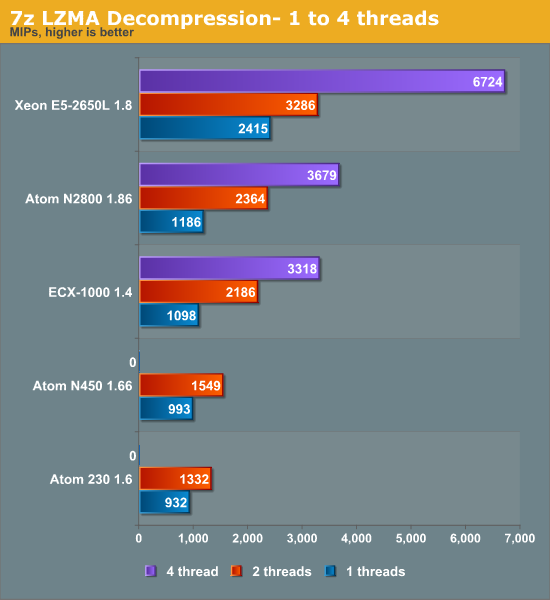
Branch mispredictions are common and the Atom tackles branch mispredictions well with its Simulteanous MultiThreaded (SMT) core. The boost from Hyper-Threading is very large here: a second ARM Cortex-A9 core gives a 52% boost and Hyper-Threading gives a 56% boost. This is very much the exception as far as Hyper-Threading performance is concerned.
Looking at both decompression and compression, it looks like a quad ARM Cortex-A9 is about as fast as one Xeon core (without Hyper-Threading) at the same clock. We need about six Cortex-A9 cores to match the Xeon core with Hyper-Threading enabled. The quad-core ECX-1000 1.4GHz is also close to the dual-core, four-threaded Atom at 1.86GHz. This bodes well for Calxeda as the 6.1W S1240 only runs at 1.6GHz.








99 Comments
View All Comments
Madpacket - Wednesday, March 13, 2013 - link
And all of a sudden AMD's acquisition of SeaMicro is starting to make sense. Thanks Johan, great article!JohanAnandtech - Wednesday, March 13, 2013 - link
I really really hope they downscale the current SeaMicro's soon. Because with a starting price at $139000, they are not catering to the typical SME :-).joshv - Wednesday, March 13, 2013 - link
It seems this has a very narrow application in VM hosting, but I am not sure it's applicable when you have the choice of just scaling up memory or process usage of the single instance Xeon server. For example, I could load 24 instances of my production middle tier on the ARM server - or I could run one instance on a Xeon server and give it all the memory and make sure it spawns enough threads to keep all the internal cores busy. Perhaps my middle tier software has issues with handling all that RAM, so maybe I run 4 instances of it as a process, not a biggy.I am going to bet that the Xeon server will win as it won't have the VM overhead.
Kurge - Wednesday, March 13, 2013 - link
I would be interested in a bare metal comparison. Since you're serving up the same app why would you split it between 24 VMs on the Xeon server? It's a bit contrived.Just load up Server 2012 and IIS or Linux + Apache straight up on the Xeon and see how it performs.
MrSpadge - Wednesday, March 13, 2013 - link
Very interesting!I'd prefer a fat machine with virtualized servers to get automatic load balancing, but it's not like one couldn't shuffle tasks around in the ARM farm. And there's room for improvement: be it the next Atom or the memory controller in the current ECX-1000 CPUs. And take a look at how badly they scale from 2 to 4 threads - surely, there's lot's of rooms left!
rubyl - Wednesday, March 13, 2013 - link
What is the average CPU utilization for the Viridis nodes and for the Xeon system under the 5 different concurrency loads (for the 24 webserver workload)?gercho - Wednesday, March 13, 2013 - link
When you said " The next generation ARM servers are already on the way and will probably hit the market in the third quarter of this year. The "Midway" SoC is based on a 28nm (TSMC) Cortex-A15 chip. A 28nm A15 offers 50% higher single-threaded integer performance at slightly higher power levels and can address up to 16GB of RAM." As far as I know the A15 cores have 50% more performance but consume 3X more power, that's not "slightly".........nofumble62 - Wednesday, March 13, 2013 - link
50% more performance at 3X more power... reminding me of the Netburst architect.thenewguy617 - Wednesday, March 13, 2013 - link
Can you please point me to sources of your number?Thanks
Wilco1 - Thursday, March 14, 2013 - link
Where on earth you do get that 3x from? So far no 28nm Cortex-A15 chips have been released. The A15 in the Exynos Octo uses about 1.25W per core at 1.8GHz according to Samsung. That's slightly more power than a Calxeda A9 uses per core, but the A15 gives twice the performance per core.