Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
Measuring Bandwidth
Stream measures "sustainable memory bandwidth" and is thus a good indication of how a CPU will handle data intensive applications. Dr. John McCalpin is the developer and maintainer of the STREAM benchmark.
We compiled with gcc 4.7 on all platforms and used the -O3 -fopen -static settings. It is important to remark that this version of gcc has been optimized by the Linaro group, a non-profit software engineering effort. Linaro's objective is to optimize the kernel and typical tools for the ARM-Cortex A-series CPUs.
On the Intel CPUs we force the threads to make use of Hyper-Threading with taskset. So for example, the four threads measurement is done on two physical cores with four threads. This gives an idea of how a quad-core ARM server node compares to a virtual machine that gets a few physical and few logical cores from the hypervisor. It also allows us to evaluate how two threads on top of an Atom core compare to two ARM cores. When you compare CPUs with similar power consumption, you typically get two ARM cores for each Hyper-Threaded Atom core.
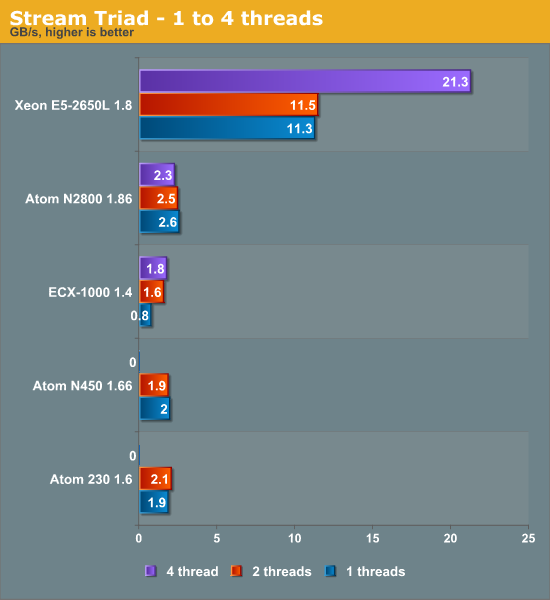
The ARM based server is a pretty bad choice right now for memory intensive workloads. Even with four cores and DDR3-1333, the useable bandwidth is less than one sixth of what one Xeon core can sustain.
In a similar vein, the ECX-1000 is not capable of providing more bandwidth than an Atom system equipped with DDR2-667. However, both the Atom and ARM cores are pretty bad when it comes to bandwidth. Although the specs claim that the CPUs can drive one channel of DDR3-1066, the measured bandwidth comes nowhere near the theoretical 8.5GB/s that such a DIMM can deliver.








99 Comments
View All Comments
JohanAnandtech - Wednesday, March 13, 2013 - link
Ok, good question. I'll look into it, as I am definitely considering a follow-upskyroski - Wednesday, March 13, 2013 - link
I make performance oriented web apps for a living and I was looking forward to this performance test very much. However, I was quite disappointed at how you have done the "real world" test.If you're serving a single site you would never put a Xeon through the performance penalties of virtualisation, so I deem your real world results flawed/unusable.
Basically, if I was to consider buying a Calxeda server tomorrow, I want to know if I can serve a site faster/better by using the "cluster in a box" solution which ARM's partners are going for or if a single Xeon server with standardised dedicated hardware will serve me and my businesses better.
The other thing that I would have also tested is SSL request performance because Intel has AES-NI built in and I believe ARM has something similar? I would say the majority of request today for a serious web app/site will be traffic using the SSL protocol, so that would also be one of those deciding factors I would look at.
If I was a cloud host provider your comparison may contain some truth as their business model would be to presumably let each ARM node out as a VPS alternative, but that isn't what you were testing were you?
JohanAnandtech - Wednesday, March 13, 2013 - link
1. The single site: it is not meant to be an environment of one single site. The reason why we use the same site over and over again, is that it makes it easier to interpret the results and more repeatable. Consider a hosting provider who host many similar - but not the same - LAMP sites.The repeatable part is the part that most people don't understand very well: we don't just hit the same URL over and over again. We perform real user interactions and randomize them in realworld patterns (like logging in first and then several real actions) and then getting a repeatable benchmark gets very complex.
2. The SSL comment is definitely good feedback. We are currently writing the connection code for such SSL websites but also need to find one or more good examples. If your site is a good example, maybe we can use yours (even under NDA if necessary) ?
3. Lastly, the virtualization overhead of ESXi 5 is very small.
Kurge - Wednesday, March 13, 2013 - link
You know, you can host multiple different LAMP sites on bare metal ;)klmccaughey - Wednesday, March 13, 2013 - link
It won't be LAMP sites any more though - take a trawl through something like the Linode forums to get an idea of what people are building. You are talking higher concurrency and more likely nginx.Someone made a valid comment about database sharding - for web apps this is much more likely as people try to make sure they have failover.
Whilst initially very disappointed, if you imaging the refresh on the ARM cores over the next 2 years (and considering the rate of change due to the phone market) you might actualy be looking at a beast of a machine in two or three iterations. Imagine if you could buy these off the shelf for under $10k: That feels to me like mission critical failover systems in a box. I can see this taking off in a couple of years.
klmccaughey - Wednesday, March 13, 2013 - link
And kudos for the review - I look forward to the follow-up. This is a space that needs watching!Silma - Thursday, March 14, 2013 - link
True but do you think Intel will stop product development for the next 3 years? In addition who will have the best fabs then? My guess is Intel.Krysto - Monday, March 18, 2013 - link
I don't know how fast it actually is, but relative to the ARMv7 architecture, AES should be up to 10x faster on ARMv8.kfreund - Wednesday, March 13, 2013 - link
Nice job, Johan. Can't wait to see your next one; we will be sure to get you an A15 based system as soon as we get it out! Let the debates begin!kfreund - Wednesday, March 13, 2013 - link
Regarding Stream performance, this is a known limitation of A9; it just can't handle a lot of concurrent memory requests. A15 will nearly triple the memory bandwidth at same DDR rate.