Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
Integer Processing
To measure the integer processing potential of the various CPUs, we'll turn to several different workloads. First up, we have 7z LZMA compression and decompression, again looking at performance with one to four threads. On the next page, we'll look at gcc compiler performance.
Compression
Compression is a low IPC workload that's sensitive to memory parallelism and latency. The instruction mix is a bit different, but this kind of workload is still somewhat similar to many server workloads.
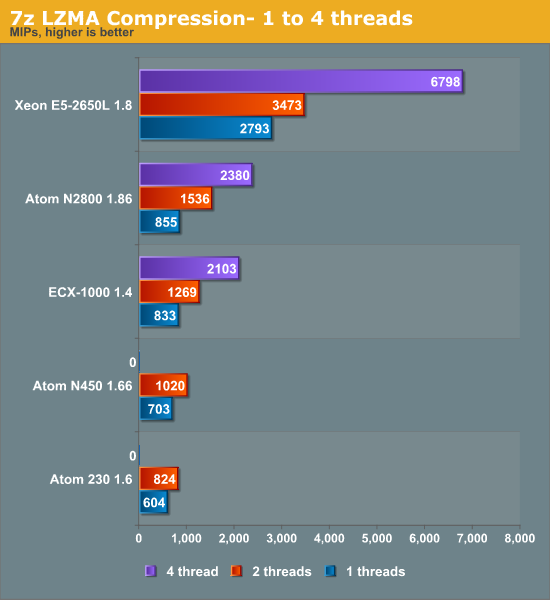
Clock for clock, the out-of-order Cortex-A9 inside the Calxeda EXC-1000 beats the in-order Atom core. A single Cortex-A9 has no trouble beating the older Atoms while likewise coming close to the much higher clocked N2800. The N2800 and ECX-1000 perform similarly.
Decompression
Decompression is pretty branch intensive and depends on the latencies of multiply and shift instructions.
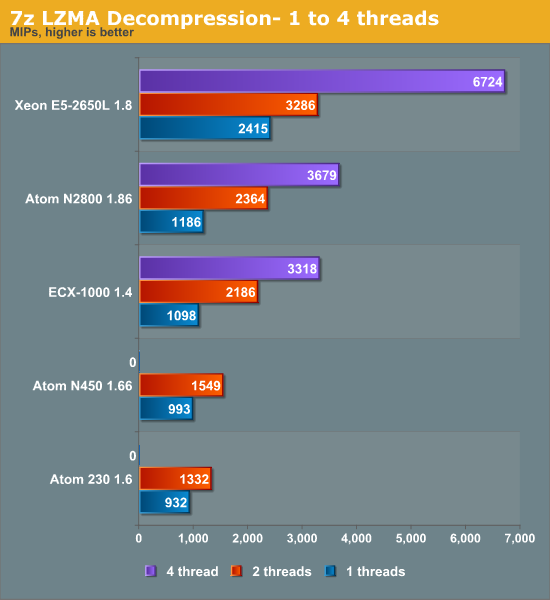
Branch mispredictions are common and the Atom tackles branch mispredictions well with its Simulteanous MultiThreaded (SMT) core. The boost from Hyper-Threading is very large here: a second ARM Cortex-A9 core gives a 52% boost and Hyper-Threading gives a 56% boost. This is very much the exception as far as Hyper-Threading performance is concerned.
Looking at both decompression and compression, it looks like a quad ARM Cortex-A9 is about as fast as one Xeon core (without Hyper-Threading) at the same clock. We need about six Cortex-A9 cores to match the Xeon core with Hyper-Threading enabled. The quad-core ECX-1000 1.4GHz is also close to the dual-core, four-threaded Atom at 1.86GHz. This bodes well for Calxeda as the 6.1W S1240 only runs at 1.6GHz.








99 Comments
View All Comments
kfreund - Friday, March 15, 2013 - link
Keep in mind that this is VERY early in the life cycle, and therefore costs are artificially high due to low volumes. Ramp up the volumes, and the prices will come WAY down.wsw1982 - Wednesday, April 3, 2013 - link
Ja, IF they have high volume. But even if there is high volume, it's shared between different ARM suppliers and needless to say, the ATOM. How much can it be for one company?But the question is where the ARM get the volume? less performance, comparable power consumption, less performance/watt rational (not this kind extreme bias case ), less flexibility, less software support (stability), vendor specific (you can build a normal server, but can you build up a massive parallel cluster?), oh, don't forgot, more (much more) expensive. Which company will sacrifice themselves to beef up the market volume of the ARM server?
Sputnik_b - Thursday, March 14, 2013 - link
Hi Johan,Nice job benchmarking and analyzing the results. Our group at EPFL has recently done some work aimed at understanding the demands that scale-out workloads, such as web serving, place on processor architectures. Our findings very much agree with your benchmark conclusions for the Xeon/Calxeda pair. However, a key result of our work was that many-core processors (with dozens of simple cores per chip) are the sweet spot with regard to performance per TCO dollar. I encourage you to take a look at our work -- http://parsa.epfl.ch/~grot/pubs/SOP-TCO_IEEEMicro....
Please consider benchmarking a Tilera system to round-out your evaluation.
Best regards!
Sputnik_b - Thursday, March 14, 2013 - link
Sorry, bad URL in the post above. This should work: http://parsa.epfl.ch/~grot/pubs/SOP-TCO_IEEEMicro....aryonoco - Friday, March 15, 2013 - link
LWN.net has a very interesting write-up on a talk given by Facebook's Director of Capacity Engineering & Analysis on the future of ARM servers and how they see ARM servers fit in with their operation. I think it gives valuable insight on this topic.http://lwn.net/SubscriberLink/542518/bb5d5d3498359... (free link)
phoenix_rizzen - Friday, March 15, 2013 - link
ARM already has hardware virtualisation extensions. Linux-KVM has already been ported over to support it.Andys - Saturday, March 16, 2013 - link
Great article, finally good to see some realistic benchmarks run on the new ARM platform.But I feel that you screwed up in one regard: You should have tested the top Xoen CPU also - the E5-2690.
As you know from your own previous articles, Intel's top CPUs are also the most power efficient under full load, and the price would still be cheaper than the full loaded Calxeda box anyway.
an3000 - Monday, March 25, 2013 - link
It is a test using wrong software stack. Yes, I am not afraid to say that! Apache will never be used on such ARM servers. They are exact match for Memcached or Nginx or another set-get type services, like static data serving. Using Apache or LAMP stack is too much favorable for Xeon.What I would like to see is: Xeon server with max RAM non-virtualized running 4-8 (similar to core count) instances of Memcached/Nginx/lighttpd vs cluster of ARM cores doing the same light task. Measure performance and power usage.
wsw1982 - Wednesday, April 3, 2013 - link
My suggestion will be let them run one hard-disk to one hard-disk copy and measure the power usage:)