NVIDIA Launches Tesla K20 & K20X: GK110 Arrives At Last
by Ryan Smith on November 12, 2012 9:00 AM ESTEfficiency Through Hyper-Q, Dynamic Parallelism, & More
When NVIDIA first announced K20 they stated that their goal was to offer 3x the performance per watt of their Fermi based Tesla solutions. With wattage being held nearly constant from Fermi to Kepler, NVIDIA essentially needed to triple their total performance to reach that number.
However as we’ve already seen from NVIDIA’s hardware specifications, K20 triples their theoretical FP32 performance but not their theoretical FP64 performance, due to the fact that NVIDIA’s FP64 execution rate falls from ½ to 1/3their FP32 rate. Does that mean NVIDIA has given up on tripling their performance? No, but with Kepler the solution isn’t just going to be raw hardware, but the efficient use of existing hardware.
Of everything Kepler and GK110 in particular add to NVIDIA’s compute capabilities, their marquee features, HyperQ and Dynamic Parallelism, are firmly rooted in maximizing their efficiency. Now that we’ve seen what NVIDIA’s hardware can do at a low level, we’ll wrap up our look at K20 and GK110 by looking at how NVIDIA intends to maximize their efficiency and best feed the beast that is GK110.
Hyper-Q
Sometimes the simplest things can be the most powerful things, and this is very much the case for Hyper-Q. Simply put, Hyper-Q expands the number of hardware work queues from 1 on GF100 to 32 on GK110. The significance of this being that having 1 work queue meant that GF100 could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM or if there were dependency issues, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.
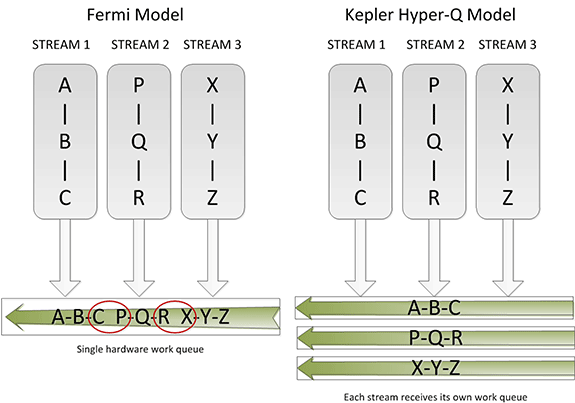
The simplistic nature of Hyper-Q is further reinforced by the fact that it’s designed to easily map to MPI, a common message passing interface frequently used in HPC. As NVIDIA succinctly puts it, legacy MPI-based algorithms that were originally designed for multi-CPU systems and that became bottlenecked by false dependencies now have a solution. By increasing the number of MPI jobs (a very easy modification) it’s possible to utilize Hyper-Q on these algorithms to improve the efficiency all without changing the core algorithm itself. Ultimately this is also one of the ways NVIDIA hopes to improve their HPC market share, as by tweaking their hardware to better map to existing HPC workloads is in this fashion NVIDIA’s hardware will become a much higher performing option.
Dynamic Parallelism
If Hyper-Q was the simple efficiency feature, then NVIDIA’s other marquee feature, Dynamic Parallelism, is the harder and more complex of the features.
Dynamic Parallelism is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.

The difficult of course comes from the fact that dynamic parallelism implicitly relies on recursion, to which as the saying goes “to understand recursion, you must first understand recursion”. The use of recursion brings with it many benefits so the usefulness of dynamic parallelism should not be understated, but if nothing else it’s a forward looking feature. Recursion isn’t something that can easily be added to existing algorithms, so taking full advantage of dynamic parallelism will require new algorithms specifically designed around it. (ed: fork bombs are ready-made for this)
Reduced ECC Overhead
Although this isn’t strictly a feature, one final efficiency minded addition to GK110 is the use of a new lower-overhead ECC algorithm. As you may recall, Tesla GPUs implement DRAM ECC in software, allowing ECC to be added without requiring wider DRAM busses to account for the checkbits, and allowing for ECC to be enabled and disabled as necessary. The tradeoff for this is that enabling ECC consumes some memory bandwidth, reducing effective memory bandwidth to kernels running on the GPU. GK110 doesn’t significantly change this model, but what it does do is reduce the amount of ECC checkbit traffic that results from ECC being turned on. The amount of memory bandwidth saved is workload dependent, but NVIDIA’s own tests are showing that the performance hit from enabling ECC has been reduced by 66% for their internal test suite.
Putting It All Together: The Programmer
Bringing things to a close, while we were on the subject of efficiency the issue of coder efficiency came up in our discussions with NVIDIA. GK110 is in many ways a direct continuation of Fermi, but at the same time it brings about a significant number of changes. Given the fact that HPC is so performance-centric and consequently often so heavily tuned for specific processors (a problem that also spans to consumer GPGPU workloads) we asked NVIDIA about just how well existing programs run on K20.
The short answer is that despite the architectural changes between Fermi and GK110, existing programs run well on K20 and are usually capable of taking advantage of the additional performance offered by the hardware. It’s clear that peak performance on K20 will typically require some rework, particularly to take advantage of features like dynamic parallelism, but otherwise we haven’t been hearing about any notable issues transitioning to K20 thus far.

Meanwhile as part of their marketing plank NVIDIA is also going to be focusing on bringing over additional HPC users by leveraging their support for OpenACC, MPI, and other common HPC libraries and technologies, and showcasing just how easy porting HPC programs to K20 is when using those technologies. Note that these comparisons can be a bit misleading since the core algorithms of most programs are complex yet code dense, but the main idea is not lost. For NVIDIA to continue to grow their HPC market share they will need to covert more HPC users from other systems, which means they need to make it as easy as possible to accommodate their existing code and tools.








73 Comments
View All Comments
dcollins - Monday, November 12, 2012 - link
It should be noted that recursive algorithms are not always more difficult to understand than their iterative counterparts. For example, the quicksort algorithm used in nvidia's demos is extremely simple to implement recursively but somewhat tricky to get right with loops.The ability to directly spawn sub-kernels has applications beyond supporting recursive GPU programming. I could see the ability to create your own workers would simplify some problems and leave the CPU free to do other work. Imagine an image processing problem where a GPU kernel could do the work of sharding an image and distributing it to local workers instead of relying on a (comparatively) distant CPU to perform that task.
In the end, this gives more flexibility to GPU compute programs which will eventually allow them to solve more problems, more efficiently.
mayankleoboy1 - Monday, November 12, 2012 - link
We need compilers that can work on GPGPU to massively speed up compilation times.Loki726 - Tuesday, November 13, 2012 - link
I'm working on this. It actually isn't as hard as it might seem at first glance.The amount of parallelism in many compiler optimizations scale with program size, and the simplest algorithms basically boil down to for(all instructions/functions/etc) { do something; }. Everything isn't so simple though, and it still isn't clear if there are parallel versions of some algorithms that are as efficient as their sequential implementations (value-numbering is a good example).
So far the following work very well on a massively parallel processor:
- instruction selection
- dataflow analysis (live sets, reaching defs)
- control flow analysis
- dominance analysis
- static single assignment conversion
- linear scan register allocation
- strength reduction, instruction simplification
- constant propagation (local)
- control flow simplification
These are a bit harder and need more work:
- register allocation (general)
- instruction scheduling
- instruction subgraph isomorphism (more general instruction selection)
- subexpression elimination/value numbering
- loop analysis
- alias analysis
- constant propagation (global)
- others
Some of these might end up being easy, but I just haven't gotten to them yet.
The language frontend would also require a lot of work. It has been shown
that it is possible to parallelize parsing, but writing a parallel parser for a language
like C++ would be a very challenging software design project. It would probably make more sense to build a parallel parser generator for framework like Bison or ANTLR than to do it by hand.
eachus - Wednesday, November 14, 2012 - link
I've always assumed that the way to do compiles on a GPU or other heavily parallel CPU is to do the parsing in a single sequential process, then spread the semantic analysis and code generation over as many threads as you can.I may be biased in this since I've done a lot of work with Ada, where adding (or changing) a 10 line file can cause hundreds of re-analysis/code-generation tasks. The same thing can happen in any object-oriented language. A change to a class library, even just adding another entry point, can cause all units that depend on the class to be recompiled to some extent. In Ada you can often bypass the parser, but there are gotchas when the new function has the same (simple) name as an existing function, but a different profile.
Anyway, most Ada compilers, including the GNAT front-end for GCC will use as many CPU cores as are available. However, I don't know of any compiler yet that uses GPUs.
Loki726 - Thursday, November 15, 2012 - link
The language frontend (semantic analysis and IR generation, not just parsing) for C++ is generally harder than languages that have concepts of import/modules or interfaces because you typically need to parse all included files for every object file. This is especially true for big code bases (with template libraries).GPUs need thousands of way parallelism rather than just one dimension for each file/object, so it is necessary to extract parallelism on a much finer granularity (e.g. for each instruction/value).
A major part of the reason why GPU compilers don't exist is because they are typically large/complex codebases that don't map well onto parallel models like OpenMP/OpenACC etc. The compilers for many languages like OpenCL are also immature enough that writing a debugging a large codebase like this would be intractable.
CUDA is about the only language right now that is stable enough and has enough language features (dynamic memory allocation, object oriented programming, template) to try. I'm writing all of the code in C++ right now and hoping that CUDA will eventually cease to be a restricted subset of C++ and just become C++ (all it is missing is exceptions, the standard library, and some minor features that other compilers are also lax about supporting).
CeriseCogburn - Thursday, November 29, 2012 - link
Don't let the AMD fans see that about OpenCL sucking so badly and being immature.It's their holy grail of hatred against nVidia/Cuda.
You might want to hire some protection.
I can only say it's no surprise to me, as the amd fanboys are idiots 100% of the time.
Now as amd crashes completely, gets stuffed in a bankruptcy, gets dismantled and bought up as it's engineers are even now being pillaged and fired, the sorry amd fanboy has "no drivers" to look forward to.
I sure hope their 3G ram 79xx "futureproof investment" they wailed and moaned about being the way to go for months on end will work with the new games...no new drivers... 3rd tier loser engineers , sparse crew, no donuts and coffee...
*snickering madly*
The last laugh is coming, justice will be served !
I'd just like to thank all the radeon amd ragers here for all the years of lies and spinning and amd tokus kissing, the giant suction cup that is your pieholes writ large will soon be able to draw a fresh breath of air, you'll need it to feed all those delicious tears.
ROFL
I think I'll write the second edition of "The Joys of Living".
inaphasia - Tuesday, November 13, 2012 - link
Everybody seems to be fixated on the fact that the K20 doesn't have ALL it's SMXes enabled and assuming this is the result of binning/poor yields, whatever...AFAICT the question everybody should be asking and the one I'd love to know the answer to is:
Why does the TFLOP/W ratio actually IMPROVE when nVidia does that?
Watt for Watt the 660Ti is slightly better at compute than the 680 and far better than the 670, and we all know they are based on the "same" GK104 chip. Why? How?
My theory is that even if TSCM's output of the GK110 was golden, we'd still be looking at disabled SMXes. Of course since it's just a theory, it could very well be wrong.
frenchy_2001 - Tuesday, November 13, 2012 - link
No, you are probably right.Products are more than their raw capabilities. When GF100 came out, Nvidia placed a 480 core version (out of 512) in the consumer market (at 700MHz+) and a 448 at 575MHz in the Quadro 6000. Power consumption, reliability and longevity were all parts of that decision.
This is part of what was highlighted in the article as a difference between K20X and K20, the 235W vs 225W makes a big difference if your chassis is designed for the latter.
Harry Lloyd - Tuesday, November 13, 2012 - link
Can you actually play games with these cards (drivers)?I reckon some enthusiasts would pick this up.
Ryan Smith - Wednesday, November 14, 2012 - link
Unfortunately not. If nothing else, because there aren't any display outputs.