The iPhone 5 Review
by Anand Lal Shimpi, Brian Klug & Vivek Gowri on October 16, 2012 11:33 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 5
Apple's Swift: Pipeline Depth & Memory Latency
Section by Anand Shimpi
For the first time since the iPhone's introduction in 2007, Apple is shipping a smartphone with a CPU clock frequency greater than 1GHz. The Cortex A8 in the iPhone 3GS hit 600MHz, while the iPhone 4 took it to 800MHz. With the iPhone 4S, Apple chose to maintain the same 800MHz operating frequency as it moved to dual-Cortex A9s. Staying true to its namesake, Swift runs at a maximum frequency of 1.3GHz as implemented in the iPhone 5's A6 SoC. Note that it's quite likely the 4th generation iPad will implement an even higher clocked version (1.5GHz being an obvious target).
Clock speed alone doesn't tell us everything we need to know about performance. Deeper pipelines can easily boost clock speed but come with steep penalties for mispredicted branches. ARM's Cortex A8 featured a 13 stage pipeline, while the Cortex A9 moved down to only 8 stages while maintining similar clock speeds. Reducing pipeline depth without sacrificing clock speed contributed greatly to the Cortex A9's tangible increase in performance. The Cortex A15 moves to a fairly deep 15 stage pipeline, while Krait is a bit more conservative at 11 stages. Intel's Atom has the deepest pipeline (ironically enough) at 16 stages.
To find out where Swift falls in all of this I wrote two different codepaths. The first featured an easily predictable branch that should almost always be taken. The second codepath featured a fairly unpredictable branch. Branch predictors work by looking at branch history - branches with predictable history should be, well, easy to predict while the opposite is true for branches with a more varied past. This time I measured latency in clocks for the main code loop:
| Branch Prediction Code | ||||||
| Apple A3 (Cortex A8 @ 600MHz | Apple A5 (2 x Cortex A9 @ 800MHz | Apple A6 (2 x Swift @ 1300MHz | ||||
| Easy Branch | 14 clocks | 9 clocks | 12 clocks | |||
| Hard Branch | 70 clocks | 48 clocks | 73 clocks | |||
The hard branch involves more compares and some division (I'm basically branching on odd vs. even values of an incremented variable) so the loop takes much longer to execute, but note the dramatic increase in cycle count between the Cortex A9 and Swift/Cortex A8. If I'm understanding this data correctly it looks like the mispredict penalty for Swift is around 50% longer than for ARM's Cortex A9, and very close to the Cortex A8. Based on this data I would peg Swift's pipeline depth at around 12 stages, very similar to Qualcomm's Krait and just shy of ARM's Cortex A8.
Note that despite the significant increase in pipeline depth Apple appears to have been able to keep IPC, at worst, constant (remember back to our scaled Geekbench scores - Swift never lost to a 1.3GHz Cortex A9). The obvious explanation there is a significant improvement in branch prediction accuracy, which any good chip designer would focus on when increasing pipeline depth like this. Very good work on Apple's part.
The remaining aspect of Swift that we have yet to quantify is memory latency. From our iPhone 5 performance preview we already know there's a tremendous increase in memory bandwidth to the CPU cores, but as the external memory interface remains at 64-bits wide all of the changes must be internal to the cache and memory controllers. I went back to Nirdhar's iOS test vehicle and wrote some new code, this time to access a large data array whose size I could vary. I created an array of a finite size and added numbers stored in the array. I increased the array size and measured the relationship between array size and code latency. With enough data points I should get a good idea of cache and memory latency for Swift compared to Apple's implementation of the Cortex A8 and A9.
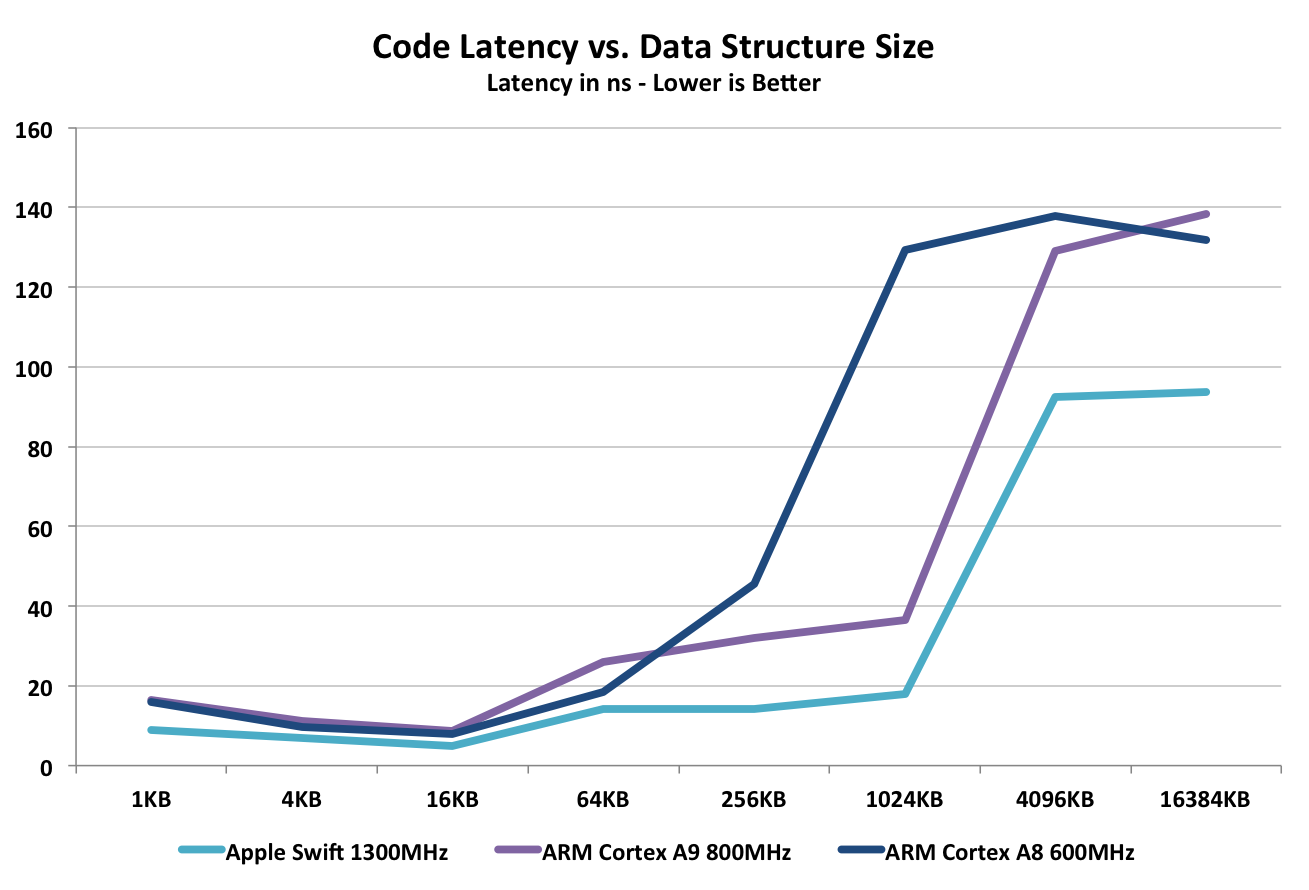
At relatively small data structure sizes Swift appears to be a bit quicker than the Cortex A8/A9, but there's near convergence around 4 - 16KB. Take a look at what happens once we grow beyond the 32KB L1 data cache of these chips. Swift manages around half the latency for running this code as the Cortex A9 (the Cortex A8 has a 256KB L2 cache so its latency shoots up much sooner). Even at very large array sizes Swift's latency is improved substantially. Note that this data is substantiated by all of the other iOS memory benchmarks we've seen. A quick look at Geekbench's memory and stream tests show huge improvements in bandwidth utilization:
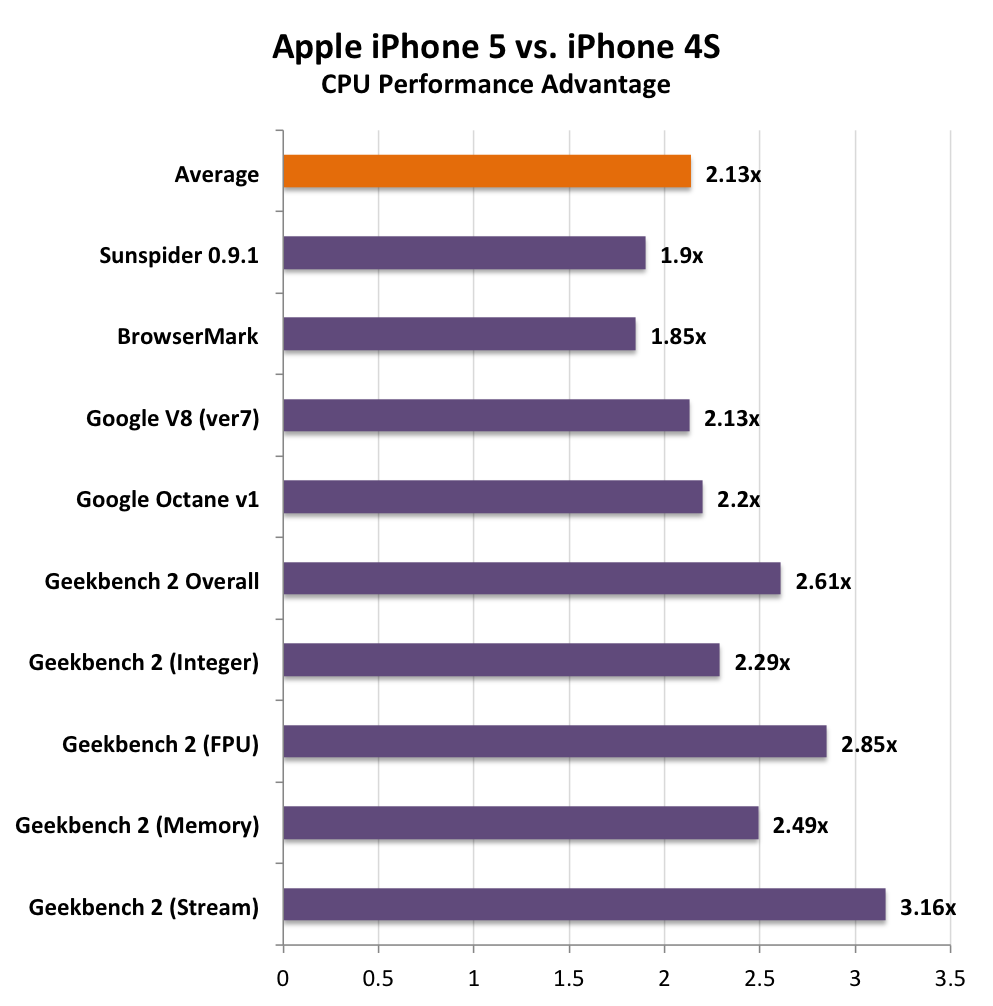
Couple the dedicated load/store port with a much lower latency memory subsystem and you get 2.5 - 3.2x the memory performance of the iPhone 4S. It's the changes to the memory subsystem that really enable Swift's performance.








276 Comments
View All Comments
Calista - Sunday, October 21, 2012 - link
English is not my native language (as I'm sure you have noticed) and so the flow in the language is far from flawless. But I still believe my opinions are valid and that the review was too long-winded.Teknobug - Wednesday, October 17, 2012 - link
I live in a big city and I don't know a single person that went and got the iPhone 5, most are happy with the iPhone 4 or whatever phone they're using, I don't see what's so great about the iPhone 5 other than it being built better than the iPhone 4's double sided glass structure (I've seen people drop their's on the train or sidewalk and it shattering on both sides!).And what now? iPad mini? I thought Apple wasn't interested in the 6-7" tablet market, Steve Jobs said 9" is small enough. I know Apple tried a 6" tablet a decade ago but the market wasn't read for it back then.
name99 - Wednesday, October 17, 2012 - link
You know what AnandTech REALLY needs now?A comment moderation system like Ars Technica, so that low-content comments and commenters (like the above) can be suppressed.
Teknobug is a PERFECT example of Ars' Troll Type #1: "Son of the "I don't even own a TV" guy: "
This is the poster who thinks other people will find it interesting that he cares nothing about their discussion or their interests, and in fact judges himself as somehow morally superior as a result. The morphology of this on Ars Technica includes people popping into threads about Windows 8 to proclaim how they will never use Windows, people popping into threads about iOS 6 to proclaim that they never have and never will buy an Apple product, and people popping into Android related threads and claiming that they will never purchase "crappy plastic phones." In these cases, the posters have failed to understand that no one really cares what their personal disposition is on something, if they have nothing to add to the discussion.
ratte - Wednesday, October 17, 2012 - link
yeah, my thoughts exactly.worldbfree4me - Wednesday, October 17, 2012 - link
I finished reading the review a few moments ago. Kudos again for a very thorough review, however I do a have a few questions and points that I would like to ask and make.Am I wrong to say, Great Job on Apple finally catching up to the Android Pack in terms of overall performance? The GS3, HTC X debuted about 6 months ago yes?
Have these benchmark scores from the competing phones been updated to reflect the latest OS updates from GOOG such as OS 4.1.X aka Jelly Bean?
Clearly the LG Optimus G is a preview of the Nexus 4,complete with a modern GPU In Adreno 320 and 2GB ram. I think based on history, the Nexus 4 will again serve as a foundation for all future Androids to follow. But again, good Job on Apple finally catching up to Android with the caveat being, iOS only has to push its performance to a 4inch screen akin to a 1080p LCD monitor verses a true gamers 1440p LCD Home PC setup. Ciao
Zinthar - Thursday, October 18, 2012 - link
Caught up and passed, actually (if you were actually reading the review). As far as graphics are concerned, no smartphone has yet to eclipse the 4S's 543MP2 other than, of course, the iPhone 5.I have no idea what you're going on about with the Adreno 320, because that only gets graphics performance up to about the level of the PowerVR SGX 543MP2. Please see Anand's preview: http://www.anandtech.com/show/6112/qualcomms-quadc...
yottabit - Wednesday, October 17, 2012 - link
Anand, as a Mech-E, I think somewhere the anodization facts in this article got very wonkyI didn't have time to read thoroughly but I saw something about the anodized layer equaling half the material thickness? The idea of having half a millimeter anodized is way off the mark
Typically there are two types of anodizing I use: regular, and "hard coat anodize" which is much more expensive
If the iPhone is scuffing then it's definitely using regular anodizing, and the thickness of that layer is likely much less than .001" or one thousandth of an inch. More on the order of a ten-thousandth of an inch, actually. The thickness of traditional anodizing is so negligible that in fact most engineers don't even need to compensate for it when designing parts.
Hard-coat anodize is a much more expensive process and can only result in a few darker colors, whereas normal anodizing has a pretty wide spectrum. Hard-coat thicknesses can be substantial, in the range of .001" to .003". This usually must be compensated for in the design process. Hard coat anodize results in a much flatter looking finish than typical anodize, and is also pretty much immune to scratches of any sort.
Aluminum oxide is actually a ceramic which is harder than steel. So having a sufficient thickness of anodize can pretty much guarantee it won't be scratched under normal operating conditions. However it's much cheaper and allows more colors to do a "regular" anodize
When I heard about scuffgate I immediately thought one solution would be to have a hardcoat anodize, but it would probably be cost prohibitive, and would alter the appearance significantly
guy007 - Wednesday, October 17, 2012 - link
A little late to the party with the review, the iPhone 6 is almost out now...jameskatt - Wednesday, October 17, 2012 - link
Anand is pessimistic about Apple's ability to keep creating its own CPUs every year. But realize that the top two smartphone manufacturers (Apple and Samsung) are CRUSHING the competition. And BOTH create their own CPUs.Apple has ALWAYS created custom chips for its computers - except for a few years when Steve Jobs accidentally let their chip engineers go when they switched to Intel and Intel's motherboard designs.
Apple SAVES a lot of money by designing its own chips because it doesn't have to pay the 3rd party profit on each chip.
Apple PREVENTS Samsung from spying on its chip designs and giving the data to its own chip division to add to its own designs. This is a HUGE win given Samsung's copycat mentality.
Apple can now always be a step ahead of the competition by designing its own chips. Realize that others will create copies of the ARM A15. But only Apple can greatly improve on the design. Apple, for example, greatly improved the memory subsystem on its own ARM chips. This is a huge weakness on otherARM chips. Apple can now custom design the power control as well - prolonging battery life even more. Etc. etc.
phillyry - Sunday, October 21, 2012 - link
Good points re: copycat and profit margin savings.I've always been baffled by the fact that Apple outsources their part manufacturing to the competition. I know that Samsung is a huge OEM player but they are stealing Apple's ideas. They are doing a very good job of it and now improving on those ideas and techs, which is good for the consumer but still seems completely illogical to me from Apple's perspective. Must be the 20/20 hindsight kicking in again.