The iPhone 5 Review
by Anand Lal Shimpi, Brian Klug & Vivek Gowri on October 16, 2012 11:33 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 5
Apple's Swift: Pipeline Depth & Memory Latency
Section by Anand Shimpi
For the first time since the iPhone's introduction in 2007, Apple is shipping a smartphone with a CPU clock frequency greater than 1GHz. The Cortex A8 in the iPhone 3GS hit 600MHz, while the iPhone 4 took it to 800MHz. With the iPhone 4S, Apple chose to maintain the same 800MHz operating frequency as it moved to dual-Cortex A9s. Staying true to its namesake, Swift runs at a maximum frequency of 1.3GHz as implemented in the iPhone 5's A6 SoC. Note that it's quite likely the 4th generation iPad will implement an even higher clocked version (1.5GHz being an obvious target).
Clock speed alone doesn't tell us everything we need to know about performance. Deeper pipelines can easily boost clock speed but come with steep penalties for mispredicted branches. ARM's Cortex A8 featured a 13 stage pipeline, while the Cortex A9 moved down to only 8 stages while maintining similar clock speeds. Reducing pipeline depth without sacrificing clock speed contributed greatly to the Cortex A9's tangible increase in performance. The Cortex A15 moves to a fairly deep 15 stage pipeline, while Krait is a bit more conservative at 11 stages. Intel's Atom has the deepest pipeline (ironically enough) at 16 stages.
To find out where Swift falls in all of this I wrote two different codepaths. The first featured an easily predictable branch that should almost always be taken. The second codepath featured a fairly unpredictable branch. Branch predictors work by looking at branch history - branches with predictable history should be, well, easy to predict while the opposite is true for branches with a more varied past. This time I measured latency in clocks for the main code loop:
| Branch Prediction Code | ||||||
| Apple A3 (Cortex A8 @ 600MHz | Apple A5 (2 x Cortex A9 @ 800MHz | Apple A6 (2 x Swift @ 1300MHz | ||||
| Easy Branch | 14 clocks | 9 clocks | 12 clocks | |||
| Hard Branch | 70 clocks | 48 clocks | 73 clocks | |||
The hard branch involves more compares and some division (I'm basically branching on odd vs. even values of an incremented variable) so the loop takes much longer to execute, but note the dramatic increase in cycle count between the Cortex A9 and Swift/Cortex A8. If I'm understanding this data correctly it looks like the mispredict penalty for Swift is around 50% longer than for ARM's Cortex A9, and very close to the Cortex A8. Based on this data I would peg Swift's pipeline depth at around 12 stages, very similar to Qualcomm's Krait and just shy of ARM's Cortex A8.
Note that despite the significant increase in pipeline depth Apple appears to have been able to keep IPC, at worst, constant (remember back to our scaled Geekbench scores - Swift never lost to a 1.3GHz Cortex A9). The obvious explanation there is a significant improvement in branch prediction accuracy, which any good chip designer would focus on when increasing pipeline depth like this. Very good work on Apple's part.
The remaining aspect of Swift that we have yet to quantify is memory latency. From our iPhone 5 performance preview we already know there's a tremendous increase in memory bandwidth to the CPU cores, but as the external memory interface remains at 64-bits wide all of the changes must be internal to the cache and memory controllers. I went back to Nirdhar's iOS test vehicle and wrote some new code, this time to access a large data array whose size I could vary. I created an array of a finite size and added numbers stored in the array. I increased the array size and measured the relationship between array size and code latency. With enough data points I should get a good idea of cache and memory latency for Swift compared to Apple's implementation of the Cortex A8 and A9.
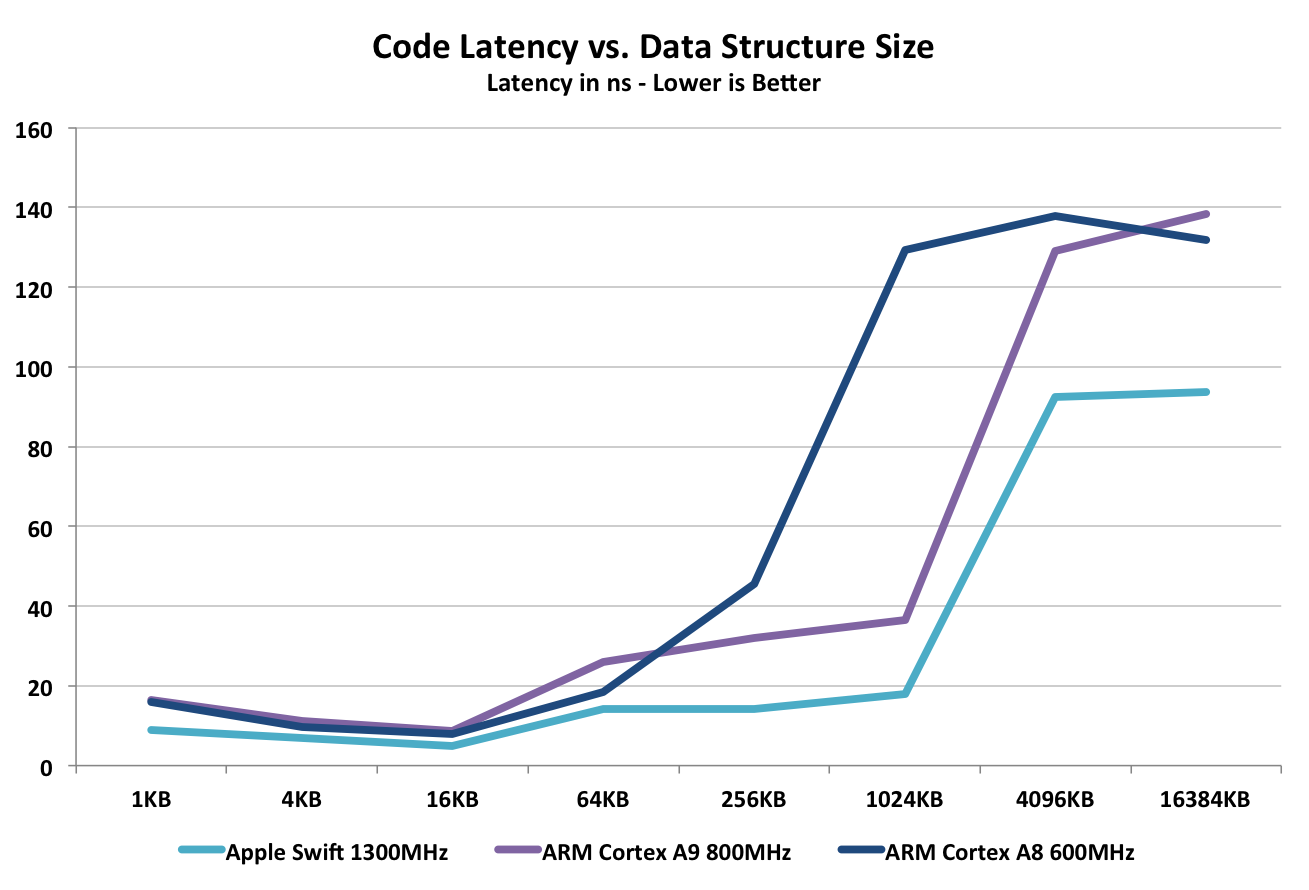
At relatively small data structure sizes Swift appears to be a bit quicker than the Cortex A8/A9, but there's near convergence around 4 - 16KB. Take a look at what happens once we grow beyond the 32KB L1 data cache of these chips. Swift manages around half the latency for running this code as the Cortex A9 (the Cortex A8 has a 256KB L2 cache so its latency shoots up much sooner). Even at very large array sizes Swift's latency is improved substantially. Note that this data is substantiated by all of the other iOS memory benchmarks we've seen. A quick look at Geekbench's memory and stream tests show huge improvements in bandwidth utilization:
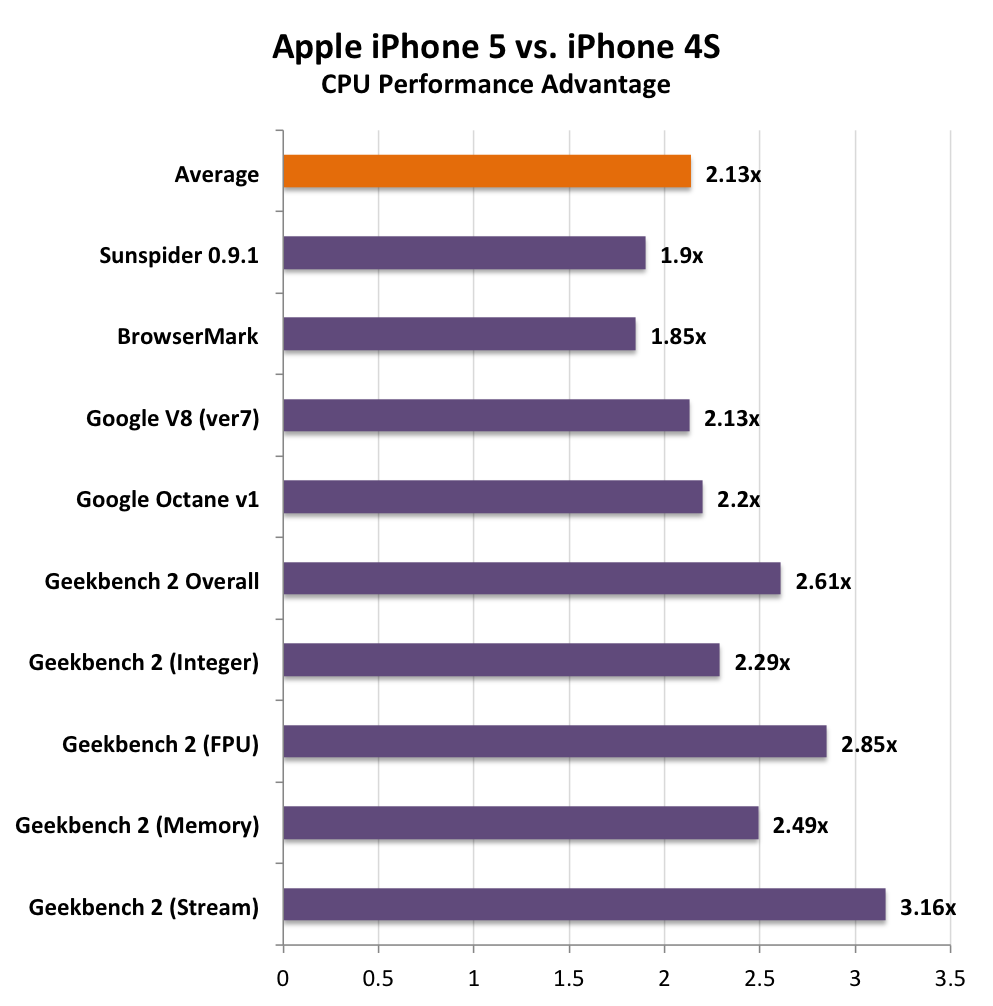
Couple the dedicated load/store port with a much lower latency memory subsystem and you get 2.5 - 3.2x the memory performance of the iPhone 4S. It's the changes to the memory subsystem that really enable Swift's performance.








276 Comments
View All Comments
Zink - Wednesday, October 17, 2012 - link
That's would be light enough to float.manders2600 - Wednesday, October 17, 2012 - link
It would be really nice to see some of these benchmarks next to an Android device running Jellybean.From my personal experience with the Galaxy Nexus, all of the benchmarks run in this article improve dramatically (many by more than 50%) with that OS version.
I'm really curious to see what a comparison between the performance of an S4 (Krait) and an A6 would be in that situation, since so much of the CPU tests are impacted by OS.
manders2600 - Wednesday, October 17, 2012 - link
But great read, though!. . . sorry, forgot to include that.
Tremendous research went into this, and it is well appreciated.
phillyry - Sunday, October 21, 2012 - link
I agree.I mean it's good that you have the devices on their native OSes but showing them on their upgraded OSes would bee good too 'cause it would add another realistic point of comparison.
cjl - Wednesday, October 17, 2012 - link
In the article, you state:"Which brings us to the next key detail with the anodization process: typically, the thickness of the anodization is half the thickness of the base aluminum. So if you had an aluminum plate that was 1mm thick, post-anodization, you would end up with a 1.5mm thick plate"
You also talk about the pore density in anodizing, and claim that apple has a pore density higher than most.
To put it quite simply, all of this is wrong.
Anodizing creates a layer that is on the order of micrometers thick. How thick the coating is depends on the details of the anodizing process, not on the thickness of the base metal. Most decorative anodized coatings are a few micrometers thick, and as you discussed, it's really not that hard to scratch them. Thicker anodizing, sometimes known as hard anodizing, is possible, and it can be done to thicknesses of 25 micrometers (0.001") or greater - from what I can find, over 100 micrometers is possible. These thicker coatings provide pretty substantial scratch resistance, and significant increases in durability, but they require substantially more process control, and it is more difficult to get a consistent coating. Note that even the thickest of these coatings is around 0.006 inches (150 micrometers) or so, which is far, far less than a 2:1 ratio on the aluminum on which it is applied. Interestingly, this thickest possible coating is about what you speculate is the thickness on the iPhone 5, but given its propensity for scratching, I sincerely doubt this to be the case.
Now for pores. The pore size on anodized aluminum is a few tens of nanometers. There is absolutely no way that you could visibly see this, or any improvement in this from one product to the next. This is 20 times smaller than the smallest wavelength of visible light. Quite simply, you can't possibly see this, and this won't be any different between Apple and any other manufacturer.
That having been said, there are some slight differences in pore structure between coatings. They won't make a significant visible difference (if any at all), but they can make a difference in durability. Specifically, hard anodized coatings (as mentioned above) tend to have thicker walled pores relative to the pore diameter. This again helps increase the wear resistance of hard anodized parts.
TL,DR: The iPhone probably has a really thin anodizing coat (<10 um). The pores are never visible on anodizing. Anodizing can be done, even on very thin aluminum, such that it would be incredibly scratch resistant.
Jaguar36 - Wednesday, October 17, 2012 - link
+1 on this.Not sure where the Vivek got the 2:1 ratio for an anodization thickness, but its nonsense. If you have a 0.25" thick part you're not going to be getting a 0.125" thick anodization. Anodization is usually less than 0.001" thick, and has no relation to the base part thickness.
Cibafsa - Wednesday, October 17, 2012 - link
Whilst Android based device manufacturers do not have to bear the majority of the SOC design/manufacture costs or the OS development costs, they do not share in the iAds/App Store type revenue Apple does.Surely it is Apple that can afford to cut prices to cost or even lower. Perhaps it is the Android manufacturers that have to worry about cheap high end phones.
Will be interesting to see what price point the iPad mini comes in at.
steven75 - Wednesday, October 17, 2012 - link
Most people following this industry are well aware by now that the App Store is run near break-even and iAds were not very successful.Calista - Wednesday, October 17, 2012 - link
A good and through review but I found it a bit too long-winded. An example would be the following example straight from the first page:'All previous iPhones have maintained the same 3.5-inch, 3:2 aspect ratio display. With the rest of the world quickly moving to much larger displays, and with 16:9 the clear aspect ratio of choice, when faced with the decision of modernizing the iPhone platform the choice was obvious.'
It could have been shortened to:
'iPhone 5 moves from the previously used 3.5", 3:2 aspect ration to a 4", 16:9 aspect ratio as common among smartphones of today. They kept roughly the same width while increasing the hight with xx mm. The resolution went from 960x640 to 1136x640."
More information is contained in the rewritten part while at the same time being shorter. Don't forget that this is Anandtech and I assume every single one of your readers are familiar with both the size and resolution of previous iPhones as well as common aspect ratios used on phones.
The same could be said about the design. I'm sure every single one of your readers have held and played with an iPhone 4/4s, and so when comparing to those two you guys could have kept a lot shorter.
phillyry - Sunday, October 21, 2012 - link
Read better as originally posted than as you rewrote it.