NVIDIA GeForce GTX 670 Review Feat. EVGA: Bringing GK104 Down To $400
by Ryan Smith on May 10, 2012 9:00 AM ESTCompute
Shifting gears, as always our final set of benchmarks is a look at compute performance. As we have seen with GTX 680, GK104 appears to be significantly less balanced between rendering and compute performance than GF110 or GF114 were, and as a result compute performance suffers. Cache and register file pressure in particular seem to give GK104 grief, which means that GK104 can still do well in certain scenarios, but falls well short in others.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. Note that this is a DX11 DirectCompute benchmark.
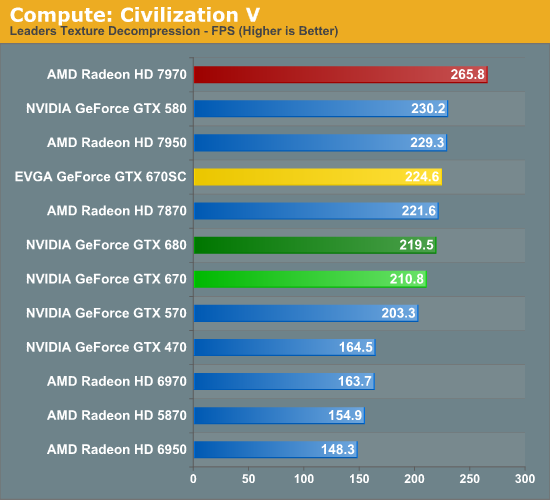
It’s quite shocking to see the GTX 670 do so well here. For sure it’s struggling relative to the Radeon HD 7900 series and the GTX 500 series, but compared to the GTX 680 it’s only trailing by 4%. This is a test that should cause the gap between the two cards to open up due to the lack of shader performance, but clearly that this not the case. Perhaps we’ve been underestimating the memory bandwidth needs of this test? If that’s the case, given AMD’s significant memory bandwidth advantage it certainly helps to cement the 7970’s lead.
Our next benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. We’re now using a development build from the version 2.0 branch, and we’ve moved on to a more complex scene that hopefully will provide a greater challenge to our GPUs.

SmallLuxGPU on the other hand finally shows us that larger gap we’ve been expecting between the GTX 670 and GTX 680. The GTX 680’s larger number of SMXes and higher clockspeed cause the GTX 670 to fall behind by 10%, performing worse than the GTX 570 or even the GTX 470. More so than any other test, this is the test that drives home the point that GK104 isn’t a strong compute GPU while AMD offers nothing short of incredible compute performance.
For our next benchmark we’re looking at AESEncryptDecrypt, an OpenCL AES encryption routine that AES encrypts/decrypts an 8K x 8K pixel square image file. The results of this benchmark are the average time to encrypt the image over a number of iterations of the AES cypher.

Once again the GTX 670 has a weak showing here, although not as bad as with SmallLuxGPU. Still, it’s enough to fall behind the GTX 570; but at least it’s enough to beat the 7950. Clockspeeds help as showcased by the EVGA GTX 670SC but nothing really makes up for the missing SMX.
Our foruth benchmark is once again looking at compute shader performance, this time through the Fluid simulation sample in the DirectX SDK. This program simulates the motion and interactions of a 16k particle fluid using a compute shader, with a choice of several different algorithms. In this case we’re using an (O)n^2 nearest neighbor method that is optimized by using shared memory to cache data.

For reasons we’ve yet to determine, this benchmark strongly dislikes GTX 670 in particular. There doesn’t seem to be a performance regression in NVIDIA’s drivers, and there’s not an incredible gap due to TDP, it just struggles on the GTX 670. As a result performance of the GTC 670 only hits 42% of the GTX 680, which is well below what the GTX 670 should theoretically be getting. Barring some kind of esoteric reaction between this program and the unbalanced GPC a driver issue is still the most likely culprit, but it looks to only affect the GTX 670.
Finally, we’re adding one last benchmark to our compute run. NVIDIA and the Folding@Home group have sent over a benchmarkable version of the client with preliminary optimizations for GK104. Folding@Home and similar initiatives are still one of the most popular consumer compute workloads, so it’s something NVIDIA wants their GPUs to do well at.
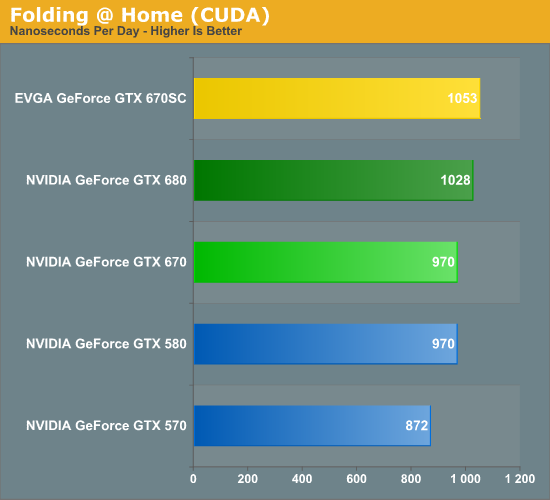
Whenever NVIDIA sends over a benchmark you can expect they have good reason to, and this is certainly the case for Folding@Home. GK104 is still a slouch given its resources compared to GF110, but at least it can surpass the GTX 580. At 970 nanoseconds per day the GTX 670 can tie the GTX 580, while the GTX 680 can pull ahead by 6%. Interestingly this benchmark appears to be far more constrained by clockspeed than the number of shaders, as the EVGA GTX 670SC outperforms the GTX 680 thanks to its 1188MHz boost clock, which it manages to stick to the entire time.








414 Comments
View All Comments
CeriseCogburn - Sunday, May 13, 2012 - link
This is your false claim about obviously. It's your and Charlie D's semi-accurate hit piece opinion and nothing else.dagamer34 - Thursday, May 10, 2012 - link
Products actually have to be consistently available for significant price drops like what you want to happen. Right now, if you need a high end card TODAY, waiting around for a GTX 680 isn't really an option, you'll have to go for the 7970 and AMD knows that.CeriseCogburn - Thursday, May 10, 2012 - link
Nope, 670 is all over the egg. Sorry you're late with that crap, and it's USA only BTW concerning 680 - the rest of the non obama world isn't suffering and can you really blame the asain(China/ commie cap government) manufacturers ?anubis44 - Friday, May 11, 2012 - link
"In the end they can't keep GK104 in stock anywhere and they still manage to beat AMD convincingly in both price and performance."You mean nvidia can't seem to make any. According to this article, nvidia has only been able to make a fraction of the GK104s that AMD has made Tahitis:
http://semiaccurate.com/2012/05/08/nvidias-five-ne...
That's what happens when you don't understand the manufacturing process you're moving to. You design a chip that's so ambitious, the failure rate is spectacular. AMD (and ATI before) on the other hand are much more familiar with the limits of successive process technology at TSMC, hence they are getting higher yields per wafer despite having a slightly larger die size, even without neutering their GPGPU compute circuitry like nvidia did.
eddman - Friday, May 11, 2012 - link
I wouldn't put too much weight in charlie's opinionated so called articles.CeriseCogburn - Friday, May 11, 2012 - link
If you read them on nVidia, and it is painful to see the twisted incoherent lies and completely contradictory links that disprove his stated reason for posting them or simply do not contain what he claimed they do, any bit of weight is too much weight at all.It's an amd fanboy firestarter flamer site, charlie's biggest purchase is red tipped matches and gasoline in a red can.
chizow - Sunday, May 13, 2012 - link
Can't agree with this for a lot of reasons. Maybe in the past with the huge GPU dies, but GK104 is *SMALLER* than Tahiti so there's really nothing ambitious about it.For capacities, Nvidia and TSMC have very close relationships and we know for a fact Nvidia is selling 2 GPUs for every 1 of AMDs, so Nvidia has an advantage there in terms of orders placed as well.
There's no reason to believe Nvidia is at any process disadvantage relative to AMD on 28nm, if anything everyone is supply constrained as other players try to move in (like Apple).
The fact there's plenty of GTX 670s still available after 3 days after launch with EXTREMELY favorable reviews tells me supply is excellent, and that Nvidia is only supply constrained on the high-end with perfect ASICs splitting good die between GTX 680 and 690.
chizow - Thursday, May 10, 2012 - link
Per usual Ryan, very relevant observations and interesting insight in regard to the changes Nvidia has made.I think I would take some of your first page insights a bit further:
1) GTX 680 is probably already heavily "overclocked" and binned to achieve a SKU Nvidia may not have planned originally, in order to beat the 7970 with a mid-range ASIC.
2) We will probably see an even more heavily harvested GK104 chip soon, given how little GTX 670 cuts from GTX 680 (just 1 SMX), but Nvidia can't cut too much without significantly impacting performance.
3) Pricing as you've laid out nicely, is probably $50-$100 too high across the board for all of these 28nm parts somewhere in the +20-25% premium range based on relative performance and historical pricing.
There's quite a few minor grammar errors throughout your article, nothing a quick proofread won't correct, but the content is excellent as usual.
Iketh - Thursday, May 10, 2012 - link
will you take the words "historical pricing" and remove them from your vocabulary? PLEASE?chizow - Thursday, May 10, 2012 - link
Its obvious the term is completely foreign to many here, including yourself, so until its well understood what it means and why its important and relevant to the discussion, I'll continue to use it."Those who do not learn from their mistakes are doomed to repeat them".
You're not even in a position to learn from your mistakes when you don't even understand the importance of "historical pricing".