The Intel Ivy Bridge (Core i7 3770K) Review
by Anand Lal Shimpi & Ryan Smith on April 23, 2012 12:03 PM EST- Posted in
- CPUs
- Intel
- Ivy Bridge
Quick Sync Image Quality & Performance
Intel obviously focused on increasing GPU performance with Ivy Bridge, but a side effect of that increased GPU performance is more compute available for Quick Sync. As you may recall, Sandy Bridge's secret weapon was an on-die hardware video transcode engine (Quick Sync), designed to keep Intel's CPUs competitive when faced with the onslaught of GPU computing applications. At the time, video transcode seemed to be the most likely candidate for significant GPU acceleration so the move made sense. Plus it doesn't hurt that video transcoding is an extremely popular activity to do with one's PC these days.
The power of Quick Sync was how it leveraged fixed function decode (and some encode) hardware with the on-die GPU's EU array. The combination of the two resulted in some pretty incredible performance gains not only over traditional software based transcoding, but also over the fastest GPU based solutions as well.
Intel put to rest any concerns about image quality when Quick Sync launched, and thankfully the situation hasn't changed today with Ivy Bridge. In fact, you get a bit more flexibility than you had a year ago.
Intel's latest drivers now allow for a selectable tradeoff between image quality and performance when transcoding using Quick Sync. The option is exposed in Media Espresso and ultimately corresponds to an increase in average bitrate. To test image quality and performance, I took the last Harry Potter Blu-ray, stripped it of its DRM and used Media Espresso to make it playable on an iPad 2 (1024 x 768 preset).
In the case of our Harry Potter transcode, selecting the Better Quality option increased average bitrate from to 3.86Mbps to 5.83Mbps. The resulting file size for the entire movie increased from 3.78GB to 5.71GB. Both options produced a good quality transcode, picking one over the other really depends on how much time (and space) you have as well as the screen size of the device you'll be watching it on. For most phone/tablet use I'd say the faster performing option is ideal.

| Intel Core i7 3770K (x86) | Intel Quick Sync (SNB) | Intel Quick Sync (IVB) | Intel Quick Sync, Better (IVB) | NVIDIA GeForce GTX 680 | AMD Radeon HD 7970 |
| original | original | original | original | original | original |
While AMD has yet to enable VCE in any publicly available software, NVIDIA's hardware encoder built into Kepler is alive and well. Cyberlink Media Espresso 6.5 will take advantage of the 680's NVENC engine which is why we standardized on it here for these tests. Once again, Quick Sync's transcoding abilities are limited to applications like Media Espresso or ArcSoft's Media Converter—there's still no support in open source applications like Handbrake.
Compared to the output from Quick Sync, NVENC appears to produce a softer image. However, if you compare the NVENC output to what we got from the software/x86 path you'll see that the two are quite similar. It seems that Quick Sync, at least in this case, is sharpening/adding more noise beyond what you'd normally expect. I'm not sure I'd call it bad, but I need to do some more testing before I know whether or not it's a good thing.
The good news is that NVENC doesn't pose any of the horrible image quality issues that NVIDIA's CUDA transcoding path gave us last year. For getting videos onto your phone, tablet or game console I'd say the output of either of these options, NVENC or Quick Sync, is good enough.
Unfortunately AMD's solution hasn't improved. The washed out images we saw last year, particularly in dark scenes prior to a significant change in brightness are back again. While NVENC delivers acceptable image quality, AMD does not.
The performance story is unfortunately not much different from last year either. The chart below is average frame rate over the entire encode process.
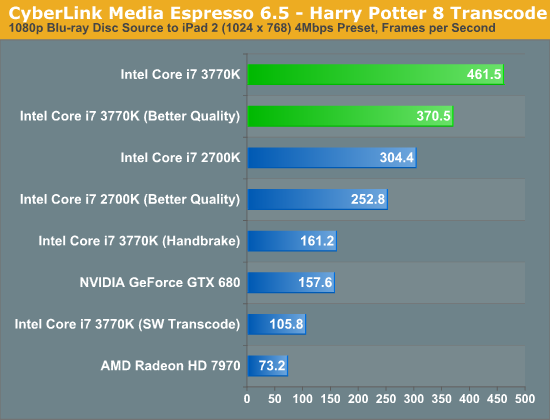
Just as we saw with Sandy Bridge, Quick Sync continues to be an incredible way to get video content onto devices other than your PC. One thing I wanted to make sure of was that Media Espresso wasn't somehow holding x86 performance back to make the GPU accelerated transcodes seem much better than they actually are. I asked our resident video expert, Ganesh, to clone Media Espresso's settings in a Handbrake profile. We took the profile and performed the same transcode, the result is listed above as the Core i7 3770K (Handbrake). You will notice that the Handbrake x86/x264 path is definitely faster than Cyberlink's software path, by over 50% to be exact. However even using Handbrake as a reference, Quick Sync transcodes over 2x faster.
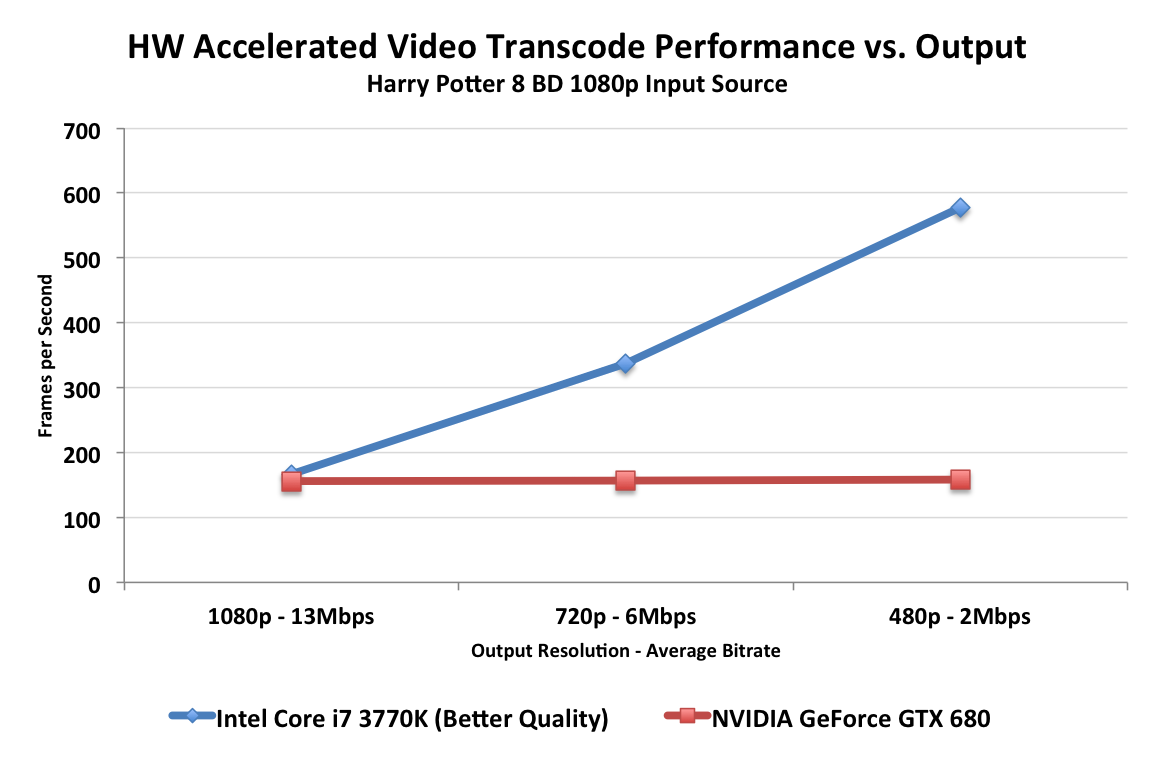
In the tests below I took the same source and varied the output quality with some custom profiles. I targeted 1080p, 720p and 480p at decreasing average bitrates to illustrate the relationship between compression demands and performance:
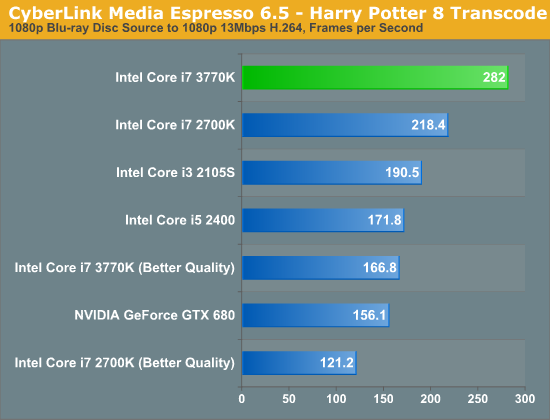
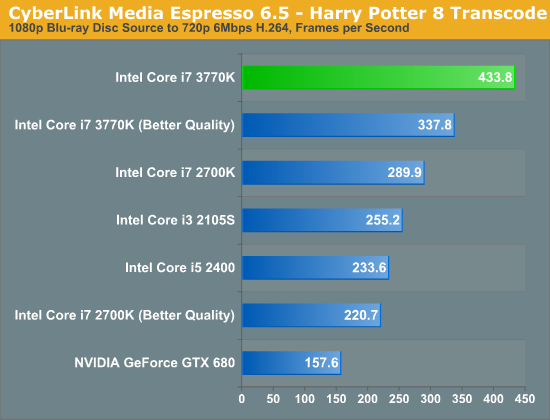
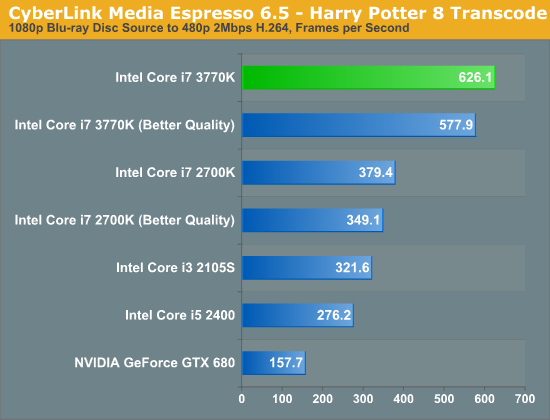
Unfortunately NVENC performance does not scale like Quick Sync. When asked to preserve a good amount of data, both NVENC and Quick Sync perform similarly in our 1080p/13Mbps test. However ask for more aggressive compression ratios for lower resolution/bitrate targets, and the Intel solution quickly distances itself from NVIDIA. One theory is that NVIDIA's entropy encode block could be the limiting factor here.
Ivy Bridge's improved Quick Sync appears to be aided both by an improved decoder and the HD 4000's faster/larger EU array. The graph below helps illustrate:

If we rely on software decoding but use Intel's hardware encode engine, Ivy Bridge is 18% faster than Sandy Bridge in this test (1080p 13Mbps output from BD source, same as above). If we turn on both hardware decode and encode, the advantage grows to 29%. More than half of the performance advantage in this case is due to the faster decode engine on Ivy Bridge.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
173 Comments
View All Comments
frozentundra123456 - Tuesday, April 24, 2012 - link
On the desktop, you are correct, especially if one overclocks. On the mobile front, IVB is a definite step up on the graphics front. My main reason for the responses to this thread was that it seemed premature for the original poster to imply that this site is being unfair to AMD/Trinity before we even know how much the improvement will be or read a review.iwod - Tuesday, April 24, 2012 - link
I read other press about 22nm 3D transistor as 11 years in the making. 11 years! Did anyone remember a article Anandtech posted a long time ago. It was about 3D transistors and Die Stacking. I did Google and Site search but could not find it. I cant record when was the article written but i was a long time. We have been waiting forever on these tech. We thought we wont see it for another 5 years.... and this is 11 years since then!Bit About Haswell Monster Graphics. Charlie also pointed towards CrystalWell, or a piece of silicon L4 SRAM Cache that is built for Graphics. Could Die Stacking be it, a piece of SRAM Cache on top or under?
I hope we do get more then 300% increase in performance. These way Ultrabook can really do get away with discrete graphics.
Well Ivy Bridge QuickSync wasn't as fast as we first thought. 7 min to transfer to iPad is fast, but what we want is sub 3 min. I.e the time transcode 1080P to portable format should be the same time to transfer 2.5 GB File from a USB 2.0 to iPad. Both Process should be happening in the same time. So when you "transfer" you are literally transcoding on the fly.
JarredWalton - Tuesday, April 24, 2012 - link
I'd say most of the same things to you. If you think the 15% clock speed increase of the CPU in Llano MX chips will somehow magically translate into significantly faster GPU performance, you're dreaming. Best-case it would improve some titles 15%, but of the 15 games I tested I can already tell you that CPU speed won't matter in over half of them--the HD 6620G isn't fast enough to use a more powerful CPU. The 10W TDP difference only matters for CPU performance, not the GPU performance, as the CPU clocks change but the GPU clocks don't.JarredWalton - Tuesday, April 24, 2012 - link
No, I think they're equal because these are the parts that are being sold, and they perform roughly the same. Actually, I think that the laptops most people buy with Llano are actually WORSE than Ivy Bridge's HD 4000, because what most people are buying with Llano is the cheap A6 chips, but that's not what we compared.But let's just say that we add DDR3-1600 memory to Llano, and we test with 8GB RAM. (Again, if you think 8GB actually helps in gaming performance, you don't understand technology.) Let's also say that every single game is CPU limited on Llano for kicks. With an MX chip in our hypothetical laptop, the best Llano would d would be to average 15% faster than HD 4000.
That's meaningless. It's the difference between 35FPS and 40FPS in a game, or 30FPS and 26FPS. Congratulations: you GPU might be 15% faster on average buy your CPU is half the speed. That's not a "win" for AMD.
Here's the facts: What was a gap of 50% with mobile Sandy Bridge vs. mobile Llano is now less than 5% on average. AMD has better drivers, but Intel is closing the gap. Trinity will improve GPU performance, and likely do very little for CPU performance. The end.
Riek - Tuesday, April 24, 2012 - link
Hi Anand & Ryan,Would it be possible to use one type of comparison through the pages?
Currently there are pages 'A8 is xx%faster than IvB' and their are pages ivyB trails A8 performance by .. or something similar.
My assumption is (since english is not my native language):
Trailing by 55% means that a A8 122% faster or vice versa. (e.g. it is is 55%slower than the A8)
Achieving 55% of the A8 means that A8 is 81% faster (e.g. it has 55% of the A8 score. if A8 scores 100, it scores 55).
Would great if the reader knows which one you use an can stick by it instead of having to recalculate it after they read every sentence twice. (and assume the understanding of the sentence is correct). I believe the general use would be part A is x% faster than part B or use the 2600K as a baseline and calculate all others as faster than compared to it.
JarredWalton - Tuesday, April 24, 2012 - link
I'll bet you $100 I can put 8GB RAM in the Llano laptop and it won't change any of the benchmark results by more than 2%. If I swap out the RAM for DDR3-1600, it will potentially increase gaming performance in a few titles by 5-10%, but that's about it.Anand's testing on the desktop showed that DDR3-1600 improved performance on the A8-3850 by around 12-14%, but the A8-3850 also has the 400 cores clocked 35% higher and can thus make better use of additional memory bandwidth. It's similar to DDR3-1866 vs. DDR3-1600 on desktop; the 17% increase in RAM speed only delivers an additional 6%, because the 600MHz HD 6550D cores are the bottleneck at that point. For laptops, the bottleneck is the cores a lot earlier; why do you think so many Llano laptops ship with DDR3-1333 still?
If you'd like to see someone's extensive testing (with a faster A8-3510MX chip even), here's a post that basically confirms everything I've said:
http://forum.notebookreview.com/gaming-software-gr...
BSMonitor - Wednesday, May 2, 2012 - link
Kudos Jarred on the professional way you handled that.Tough to argue with someone who doesn't base their arguments on facts, rather their impression/belief on how things work/perform.
Hrel - Tuesday, April 24, 2012 - link
If I have Ivy Bridge on the desktop, and have my monitor plugged into a dedicated GPU can I still use Quick Sync?Or do I still have to plug the monitor into the motherboard and be using integrated graphics?
Frankly quick sync is useless on the desktop if it doesn't work with a GTX560.
elkatarro - Tuesday, April 24, 2012 - link
Why the hell can't you see that comparing i7 3770K with 3,5 GHz to i7 2600K which runs at 3,4 GHz is POINTLESS?! Pretty much every other site got that point and used 2700K. Sure the 3770K will be faster than 2600K, duh...S20802 - Tuesday, April 24, 2012 - link
32 -> 22 nm, transistor dimension reduced by 31%,75% of die size, 20 % increase in transistor count. This means for the same die size there will be an increase of transistor count by 26%.
Projection
22 -> 14 nm, transistor dimension reduced by 36%.
Applying similar pattern we may get roughly 30% gain in transitor count.
However the gain may be lesser since the gain in IVB could have been due to 3D transistor tech.
So at best 30% and worst around 24% just for the decrease in transistor dimension.
This is by no means a precise calculation taking all factors into consideration.
Assuming the 14nm plant under construction goes online in 2013 with 450mm wafers, we can predict something like below
Transistor Count - nm - Die Size - Wafer Size - Dies/Wafer - Plant Capacity [Wafers/Month] - Plant Efficiency [%] - Yield [%] - Total Plants - Processors/Month
1.4B 22 160 300 441.9642857 50000 75 50 3 24,860,491.07
1.8B 14 160 450 994.4196429 50000 75 50 1 18,645,368.30
A staggering 18 Million working dies per month with 1.8B transistors at 160 mm2, with plant capacity of 50000 wafers/month, plant efficiency 75% and yield 50%, with 1 plant
Lets not forget the partly defective dies will be fused off to become some low end part which means the yield could touch 60%, taking the working dies to 22 Millions per month!!
This means Intel is going to make really cheap processors. 450mm wafer + 14nm = Game changer. Of course the fab is super expensive. But from what came out from Intel those first few batches of chips are paying for the ramp up to 22nm.
For an ultra mobile processor like Atom, in 2014, even a massive redesign of chip would still keep it well under 100 mm2. At 100 mm2, an Atom in 2014 will have ~1B transistors!!! Take that ARM.
My faith in Intel is rekindled. :-). AMD needs to be around to shove Intel whenever it gets too lazy. ARM is now helping AMD too in shoving Intel.