AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher, Cont
Having established what’s bad about VLIW as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).

A Single GCN SIMD
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
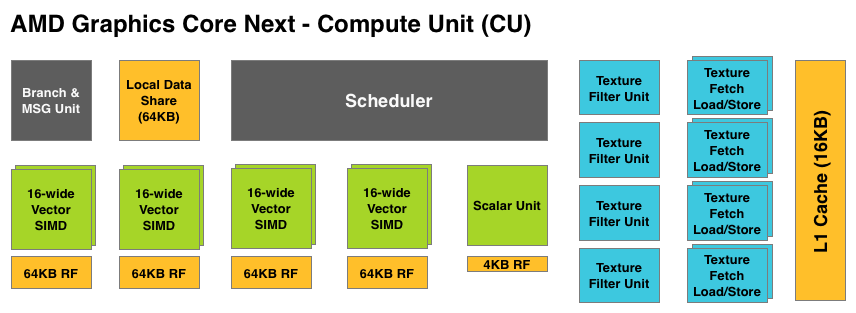
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
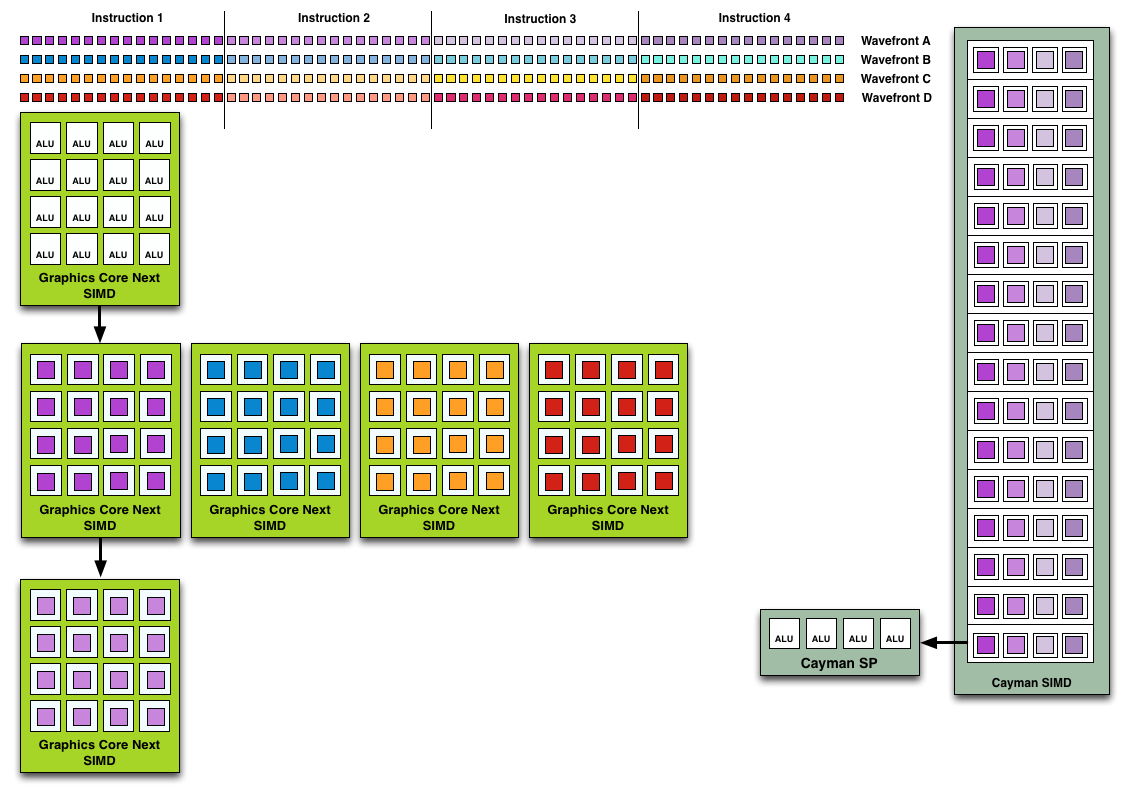
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup. Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
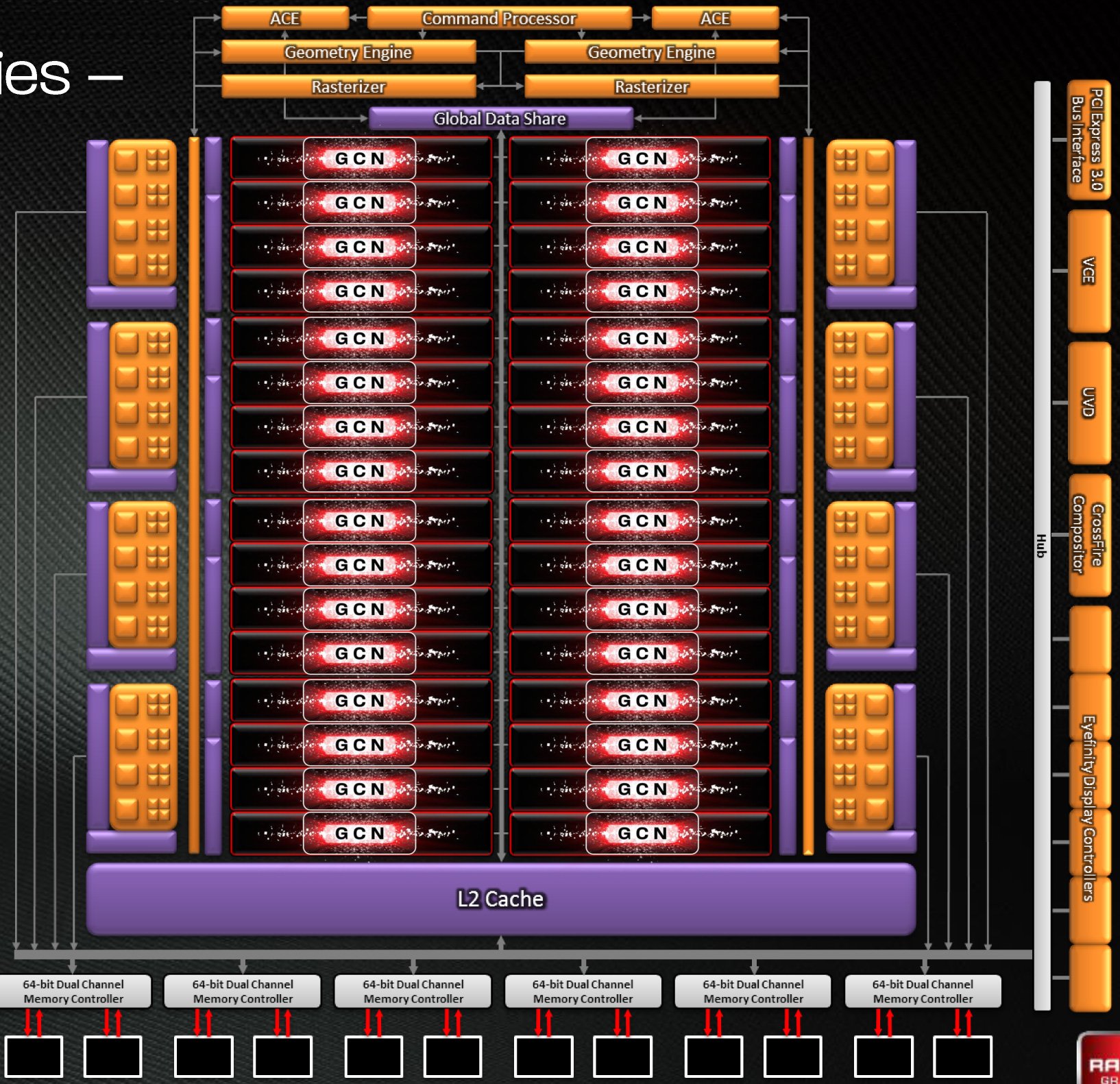
At the end of the day if AMD has done their homework GCN should significantly improve compute performance relative to VLIW4 while gaming performance should be just as good. Gaming shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. And for games that use compute shaders, they should directly benefit from the compute improvements. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing gaming performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.








292 Comments
View All Comments
mczak - Thursday, December 22, 2011 - link
Oh yes _for this test_ certainly 32 ROPs are sufficient (FWIW it uses FP16 render target with alpha blend). But these things have caches (which they'll never hit in the vantage fill test, but certainly not everything will have zero cache hits), and even more important than color output are the z tests ROPs are doing (which also consume bandwidth, but z buffers are highly compressed these days).You can't really say if 32 ROPs are sufficient, nor if they are somehow more efficient judged by this vantage test (as just about ANY card from nvidia or amd hits bandwidth constraints in that particular test long before hitting ROP limits).
Typically it would make sense to scale ROPs along with memory bandwidth, since even while it doesn't need to be as bad as in the color fill test they are indeed a major bandwidth eater. But apparently AMD disagreed and felt 32 ROPs are enough (well for compute that's certainly true...)
cactusdog - Thursday, December 22, 2011 - link
The card looks great, undisputed win for AMD. Fan noise is the only negative, I was hoping for better performance out the new gen cooler but theres always non-reference models for silent gaming.Temps are good too so theres probably room to turn the fan speed down a little.
rimscrimley - Thursday, December 22, 2011 - link
Terrific review. Very excited about the new test. I'm happy this card pushes the envelope, but doesn't make me regret my recent 580 purchase. As long as AMD is producing competitive cards -- and when the price settles on this to parity with the 580, this will be the market winner -- the technology benefits. Cheers!nerfed08 - Thursday, December 22, 2011 - link
Good read. By the way there is a typo in final words.faster and cooler al at once
Anand Lal Shimpi - Thursday, December 22, 2011 - link
Fixed, thank you :)Take care,
Anand
hechacker1 - Thursday, December 22, 2011 - link
I think most telling is the minimum FPS results. The 7970 is 30-45% ahead of the previous generation; in a "worse case" situation were the GPU can't keep up or the program is poorly coded.Of course they are catching up with Nvidia's already pretty good minimum FPS, but I am glad to see the improvement, because nothing is worse than stuttering during a fasted pace FPS. I can live with 60fps, or even 30fps, as long as it's consistent.
So I bet the micro-stutter problem will also be improved in SLI with this architecture.
jgarcows - Thursday, December 22, 2011 - link
While I know the bitcoin craze has died down, I would be interested to see it included in the compute benchmarks. In the past, AMD has consistently outperformed nVidia in bitcoin work, it would also be interesting to see Anandtech's take as to why, and to see if the new architecture changes that.dcollins - Thursday, December 22, 2011 - link
This architecture will most likely be a step backwards in terms of bitcoin mining performance. In the GCN architecture article, Anand mentioned that buteforce hashing was one area where a VLIW style architecture had an advantage over a SIMD based chip. Bitcoin mining is based on algorithms mathematically equivalent to password hashing. With GCN, AMD is changing the very thing that made their card better miners than Nvidia's chips.The old architecture is superior for "pure," mathematically well defined code while GCN is targeted at "messy," more practical and thus widely applicable code.
wifiwolf - Thursday, December 22, 2011 - link
a bit less than expected, but not really an issue:http://www.tomshardware.co.uk/radeon-hd-7970-bench...
dcollins - Thursday, December 22, 2011 - link
You're looking at a 5% increase in performance for a whole new generation with 35% more compute hardware, increased clock speed and increased power consumption: that's not an improvement, it's a regression. I don't fault AMD for this because Bitcoin mining is a very niche use case, but Crossfire 68x0 cards offer much better performance/watt and performance/$.