AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Video & Movies: The Video Codec Engine, UVD3, & Steady Video 2.0
When Intel introduced the Sandy Bridge architecture one of their big additions was Quick Sync, their name for their hardware H.264 encoder. By combining a specialized fixed function encoder with some GPU-based processing Intel was able to create a small, highly efficient H.264 encoder that had quality that was as good as or better than AMD and NVIDIA’s GPU based encoders that at the same time was 2x to 4x faster and consumed a fraction of the power. Quick Sync made real-time H.264 encoding practical on even low-power devices, and made GPU encoding redundant at the time. AMD of course isn’t one to sit idle, and they have been hard at work at their own implementation of that technology: the Video Codec Engine (VCE).
The introduction of VCE brings up a very interesting point for discussing the organization of AMD. As both a CPU and a GPU company the line between the two divisions and their technologies often blurs, and Fusion has practically made this mandatory. When AMD wants to implement a feature, is it a GPU feature, a CPU feature, or perhaps it’s both? Intel implemented Quick Sync as a CPU company, but does that mean hardware H.264 encoders are a CPU feature? AMD says no. Hardware H.264 encoders are a GPU feature.
As such VCE is being added to the mix from the GPU side, meaning it shows up first here on the Southern Islands series. Fundamentally VCE is very similar to Quick Sync – it’s based on what you can accomplish with the addition of a fixed function encoder – but AMD takes the concept much further to take full advantage of what the compute side of GCN can do. In “Full Mode” VCE behaves exactly like Quick Sync, in which virtually every step of the H.264 encoding process is handled by fixed function hardware. Just like Quick Sync Full Mode is fast and energy efficient. But it doesn’t make significant use of the rest of the GPU.
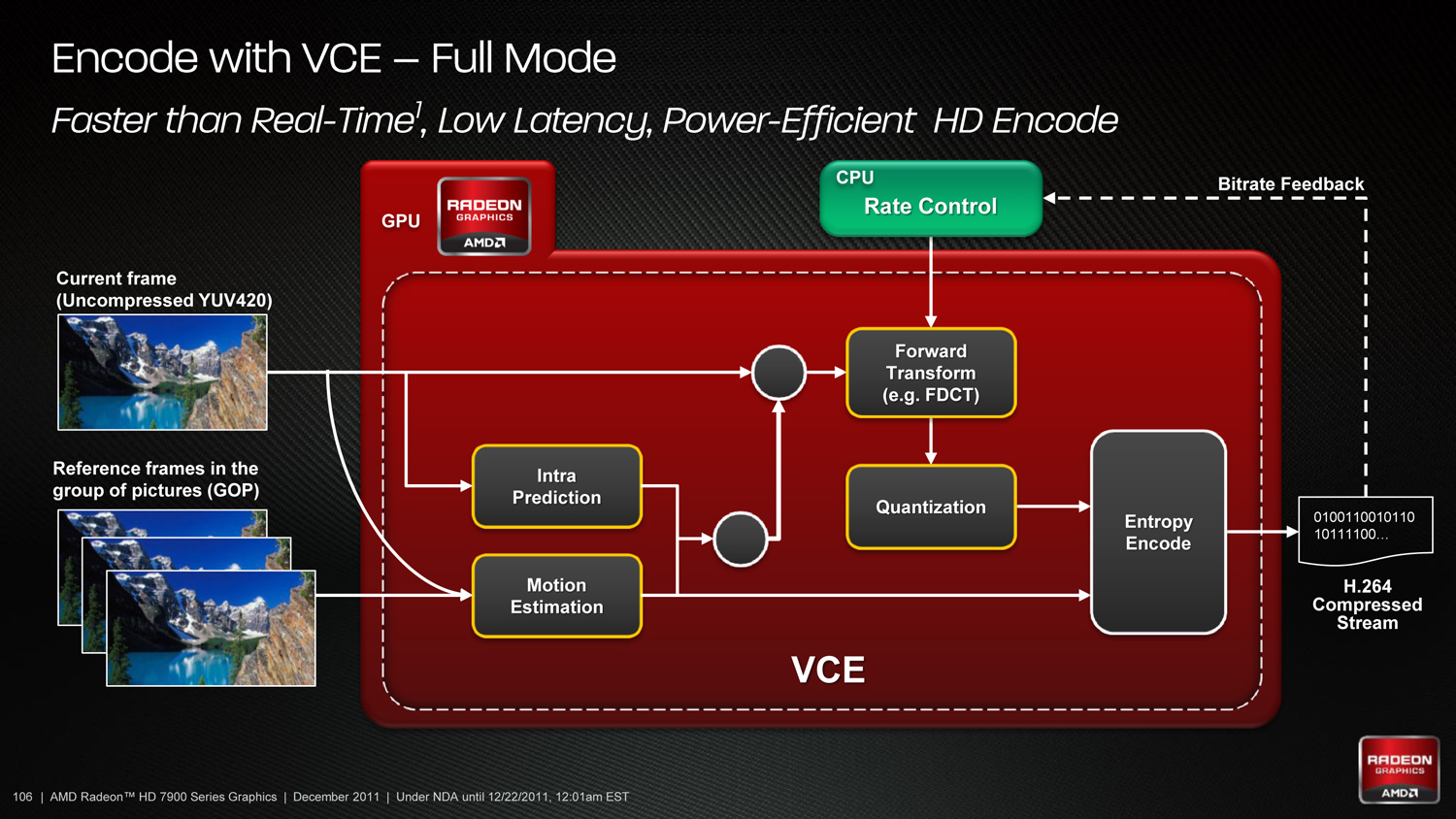
Hybrid Mode is where AMD takes things a step further, by throwing the compute resources of the GPU back into the mix. In Hybrid Mode only Entropy Encode is handled by fixed function hardware (this being a highly serial process that was ill suited to a GPU) with all the other steps being handled by the flexible hardware of the GPU. The end goal of Hybrid Mode is that as these other steps are well suited to being done on a GPU, Hybrid Mode will be much faster than even the highly optimized fixed function hardware of Full Mode. Full Mode is already faster than real time – Hybrid Mode should be faster yet.
With VCE AMD is also targeting Quick Sync’s weaknesses regardless of the mode used. Quick Sync has limited tuning capabilities which impacts the quality of the resulting encode. AMD is going to offer more tuning capabilities to allow for a wider range of compression quality. We don’t expect that it will be up to the quality standards of X264 and other pure-software encoders that can generate archival quality encodes, but if AMD is right it should be closer to archival quality than Quick Sync was.
The catch right now is that VCE is so new that we can’t test it. The hardware is there and we’re told it works, but the software support for it is lacking as none of AMD’s partners have added support for it yet. On the positive side this means we’ll be able to test it in-depth once the software is ready as opposed to quickly testing it in time for this review, however the downside is that we cannot comment on the speed or quality at this time. Though with the 7970 not launching until next year, there’s time for software support to be worked out before the first Southern Islands card ever goes on sale.
Moving on, while encoding has been significantly overhauled decoding will remain largely the same. AMD doesn’t refer to the Universal Video Decoder on Tahiti as UVD3, but the specifications match UVD3 as we’ve seen on Cayman so we believe it to be the same decoder. The quality may have been slightly improved as AMD is telling us they’ve scored 200 on HQV 2.0 – the last time we scored them they were at 197 – but HQV is a partially subjective benchmark.
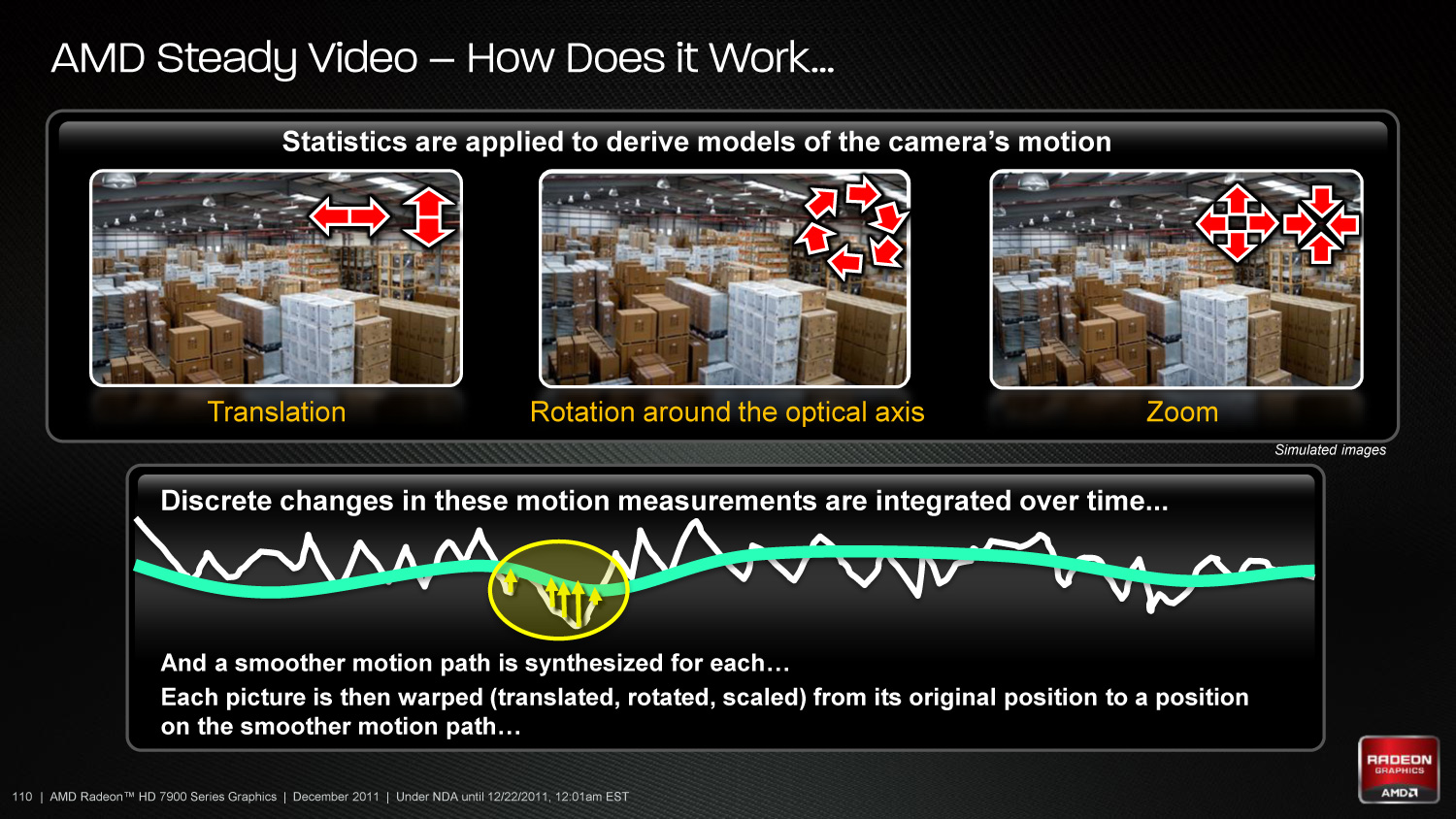
Finally, with Southern Islands AMD is introducing Steady Video 2.0, thesuccessor to Steady Video that was introduced with the Llano APU last year. Steady Video 2.0 adds support for interlaced and letter/pillar boxed content, along with a general increase in the effectiveness of the steadying effect. What makes this particularly interesting is that Steady Video implements a new GCN architecture instruction, Quad Sum of Absolute Differences (QSAD), which combines regular SAD operations with alignment operations into a single instruction. As a result AMD can now execute SADs at a much higher rate so long as they can be organized into QSADs, which is one of the principle reasons that AMD was able to improve Steady Video as it’s a SAD-heavy operation. QSAD extends to more than just Steady Video (AMD noted that it’s also good for other image analysis operations), but Steady Video is going to be the premiere use for it.








292 Comments
View All Comments
SlyNine - Friday, December 23, 2011 - link
Are you nuts, the 5870 was nearly 2x as fast in DX 10/9 stuff, not to mention DX11 was way ahead of DX10. Sure the 6970 isn't a great upgrade from a 5870, but neither is the 7970.Questionable Premise
CeriseCogburn - Thursday, March 8, 2012 - link
That happened at the end of 2006 with the G80 Roald. That means AMD and their ATI Radeon aquisition crew are five years plus late to the party.FIVE YEARS LATE.
It's nice to know that what Nvidia did years ago and recently as well is now supported by more people as amd copycats the true leader.
Good deal.
Hauk - Thursday, December 22, 2011 - link
A stunningly comprehensive analysis of this new architecture. This is what sets Anandtech apart from its competition. Kudos Ryan, this is one of your best..eastyy - Thursday, December 22, 2011 - link
its funny though when it comes to new hardware you read these complicated technical jargon and lots of detailed specs about how cards do things different how much more technically complicated and in the end for me all it means is...+15fps and thats about itas soon as a card comes out for say 150 and the games i play become slow and jerky on my 460 then i will upgrade
Mockingbird - Thursday, December 22, 2011 - link
I'd like to see some benchmarks on FX-8150 based system (990fx)piroroadkill - Friday, December 23, 2011 - link
Haha, the irony is that AMD is putting out graphics cards that would be bottlenecked HARDCORE by ANY of their CPUs, overclocked as much as you like.It's kind of tragic...
Pantsu - Friday, December 23, 2011 - link
The performance increase was as expected, at least for me, certainly not for all those who thought this would double performance. Considering AMD had a 389mm^2 chip with Cayman, they weren't going to double the transistor count again. That would've meant the next gen after this would be Nvidia class huge ass chip. So 64% more transistors on a 365mm^2 chip. Looks like transistor density increase took a bit of a hit on 28nm, perhaps because of 384-bit bus? Still I think AMD is doing better than Nvidia when it comes to density.As far as the chip size is concerned, the performance is OK, but I really question whether 32 ROPs is enough on this design. Fermi has 48 ROPs and about a billion transistors less. I think AMD is losing AA performance due to such a skimpy ROP count.
Overall the card is good regardless, but the pricing is indeed steep. I'm sure people will buy it nonetheless, but as a 365mm^2 chip with 3GB GDDR5 I feel like it should be 100$ cheaper than what it is now. I blame lack of competition. It's Nvidia's time to drop the prices. GTX 580 is simply not worth that much compared to what 6950/560Ti are going for these days. And in turn that should drop 7970/50 price.
nadavvadan - Friday, December 23, 2011 - link
Am I really tired, or is:" 3.79TFLOPs, while its FP64 performance is ¼ that at 947MFLOPs"
supposed to be:
" 3.79TFLOPs, while its FP64 performance is ¼ that at 947-G-FLOPs"?
Enjoyed the review as always.
Death666Angel - Friday, December 23, 2011 - link
Now that you have changed the benchmark, would it be possible to publish a .pdf with the relevant settings of each game? I would be very interested to replicate some of the tests with my home system to better compare some results. If it is not too much work that is (and others are interested in this as well). :Dmarc1000 - Friday, December 23, 2011 - link
What about juniper? Could it make it's way to the 7000 series as a 7670 card? Of course, upgraded to GCN, but with same specs as current cards. I guess that at 28nm it would be possible to abandon the pci-e power requirement, making it the go-to card for oem's and low power/noise systems.I would not buy it because I own one now, but I'm looking forward to 7770 or 7870 and their nvidia equivalent. It looks like next year will be a great time to upgrade for who is in the middle cards market.