AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Image Quality: Anisotropic Filtering Tweaks & Tessellation Speed
Since the launch of Evergreen AMD has continued to tweak their anisotropic filtering quality. Evergreen introduced angle-independent filtering, and with the 6000 series AMD tweaked their AF algorithm to better handle high frequency textures. With Southern Islands that trend continues with another series of tweaks.
For Southern Islands AMD has changed the kernel weights of their anisotropic filtering mechanism in order to further reduce shimmering of high frequency textures. The algorithm itself remains unchanged and as does performance, but image quality is otherwise improved. Admittedly these AF changes seem to be targeting increasingly esoteric scenarios – we haven’t seen any real game where the shimmering matches the tunnel test – but we’ll gladly take any IQ improvements we can get.
Since AMD’s latest changes are focused on reducing shimmering in motion we’ve put together a short video of the 3D Center Filter Tester running the tunnel test with the 7970, the 6970, and GTX 580. The tunnel test makes the differences between the 7970 and 6970 readily apparent, and at this point both the 7970 and GTX 580 have similarly low levels of shimmering.

While we’re on the subject of image quality, had you asked me two weeks ago what I was expecting with Southern Islands I would have put good money on new anti-aliasing modes. AMD and NVIDIA have traditionally kept parity with AA modes, with both implementing DX9 SSAA with the previous generation of GPUs, and AMD catching up to NVIDIA by implementing Enhanced Quality AA (their version of NVIDIA’s CSAA) with Cayman. Between Fermi and Cayman the only stark differences are that AMD offers their global faux-AA MLAA filter, while NVIDIA has support for true transparency and super sample anti-aliasing on DX10+ games.
Thus I had expected AMD to close the gap from their end with Southern Islands by implementing DX10+ versions of Adaptive AA and SSAA, but this has not come to pass. AMD has not implemented any new AA modes compared to Cayman, and as a result AAA and SSAA continue to only available in DX9 titles. And admittedly alpha-to-coverage support does diminish the need for these modes somewhat, but one only needs to fire up our favorite testing game, Crysis, to see the advantages these modes can bring even to DX10+ games. What’s more surprising is that it was AMD that brought AA IQ back to the forefront in the first place by officially adding SSAA, so to see them not continue that trend is surprising.
As a result for the time being there will continue to be an interesting division in image quality between AMD and NVIDIA. AMD still maintains an advantage with anisotropic filtering thanks to their angle-independent algorithm, but NVIDIA will have better anti-aliasing options in DX10+ games (ed: and Minecraft). It’s an unusual status quo that apparently will be maintained for quite some time to come.
Update: AMD has sent us a response in regard to our question about DX10+ SSAA
Basically the fact that most new game engines are moving to deferred rendering schemes (which are not directly compatible with hardware MSAA) has meant that a lot of attention is now being focused on shader-based AA techniques, like MLAA, FXAA, and many others. These techniques still tend to lag MSAA in terms of quality, but they can run very fast on modern hardware, and are improving continuously through rapid iteration. We are continuing work in this area ourselves, and we should have some exciting developments to talk about in the near future. But for now I would just say that there is a lot more we can still do to improve AA quality and performance using the hardware we already have.
Regarding AAA & SSAA, forcing these modes on in a general way for DX10+ games is problematic from a compatibility standpoint due to new API features that were not present in DX9. The preferred solution would be to have games implement these features natively, and we are currently investigating some new ways to encourage this going forward.
Finally, while AMD may be taking a break when it comes to anti-aliasing they’re still hard at work on tessellation. As we noted when discussing the Tahiti/GCN architecture AMD’s primitive pipeline is still part of their traditional fixed function pipeline, and just as with Cayman they have two geometry engines that can process up to two triangles per clock. On paper at least Tahiti doesn’t significantly improve AMD’s geometry performance, but as it turns out there’s a great deal you can do to improve geometry performance without throwing more geometry hardware at the task.
For Southern Islands AMD has implemented several techniques to boost the efficiency of their geometry engines. A larger parameter cache is a big part of this, but AMD has also increased vertex re-use and off-chip buffering. As such while theoretical geometry throughput is unchanged outside of the clockspeed differences between 7970 and 6970, AMD will be making better use of the capabilities of their existing geometry pipeline.
By AMD’s numbers these enhancements combined with the higher clockspeed of the 7970 versus the 6970 give it anywhere between a 1.7x and 4x improvement in tessellation performance. In our own tests the improvements aren’t quite as great, but they’re still impressive. Going by the DX11DetailTessellation sample program the 7970 has better performance than the GTX 580 at both normal and high tessellation factors (and particularly at high tessellation factors), while under Unigine Heaven – a tessellation-heavy synthetic benchmark – the 7970 leads the GTX 580 by over 20%. Or compared to the 6970 the difference is even more stark, with the 7970 leading the 6970 by about 55% in both of these benchmarks.
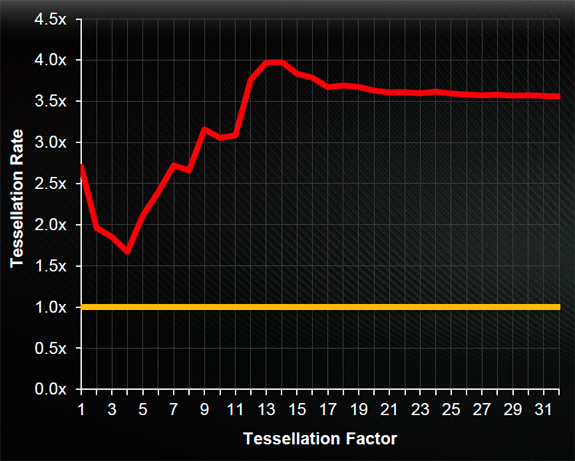
Of course both of these benchmarks are synthetic and real world performance can (and will) differ, but it does prove that AMD’s improvements in tessellation efficiency really do matter. Even though the GTX 580 can push up to 8 triangles/clock, it looks like AMD can achieve similar-to-better tessellation performance in many situations with their Southern Islands geometry pipeline at only 2 triangles/clock.
Though with that said, we’re still waiting to see the “killer app” for tessellation in order to see just how much tessellation is actually necessary. Current games (even BF3) are DX10 games with tessellation added as an extra instead of being a fundamental part of the rendering pipeline. There are a wide range of games from BF3 to HAWX 2 using tessellation to greatly different degrees and none of them really answer the question of how much tessellation is actually necessary. Both AMD and NVIDIA have made tessellation performance a big part of their marketing pushes, so there’s a serious question over whether games will be able to utilize that much geometry performance, or if AMD and NVIDIA are in another synthetic numbers war.








292 Comments
View All Comments
RussianSensation - Thursday, December 22, 2011 - link
I think his comment still stands. In terms of a performance leap, at 925mhz speeds at least, this is the worst improvement from 1 major generation to the next since X1950XTX -->2900XT. Going from 5870 to 6970 is not a full generation, but a refresh. So for someone with an HD5870 who wants 2x the speed increase, this card isn't it yet.jalexoid - Thursday, December 22, 2011 - link
How's OpenCL on Linux/*BSD? Because I fail to see real high performance use in Windows environments for any GPGPU.For GPGPU the biggest target should be still Linux/*BSD because they are the dominating platforms there....
R3MF - Thursday, December 22, 2011 - link
"Among the features added to Graphics Core Next that were explicitly for gaming, the final feature was Partially Resident Textures, which many of you are probably more familiar with in concept as Carmack’s MegaTexture technology."Is this feature exclusive to gaming, or is it an extension of a visualised GPU memory feature?
i.e. if running Blender on the GPU via the cycles renderer will i be able to load scenes larger than local graphics memory?
Ryan Smith - Thursday, December 22, 2011 - link
It's exclusive to graphics. Virtualized GPU memory is a completely different mechanism (even if some of the cache concepts are the same).With that said I see no reason it couldn't benefit Blender, but the benefits would be situational. Blender would only benefit in situations where it can't hold the full scene, but can somehow hold the visibly parts of the scene by using tiles.
R3MF - Friday, December 23, 2011 - link
cheers RyanFinally - Thursday, December 22, 2011 - link
...the 2nd generation HD8870 feat. GCN, 3W idle consumption and hopefully less load consumption than my current HD6870. Just let a company like Sapphire add a silent cooler and I'm happy.poohbear - Thursday, December 22, 2011 - link
Btw why didnt Anandtech overclock this card? it overclocks like a beast according to all the other review sites!Esbornia - Thursday, December 22, 2011 - link
Cause they want you to think this card sucks come on guys everybody in the internet knows this site sucks for reviews that are not from Intel products.SlyNine - Thursday, December 22, 2011 - link
lol troll. This site has prefered who ever had the advantage in what ever area. They will do a follow up of its OCing and when they first show a card they show it at stock only.I do not OC my videocards, whats the point in adding 5% more gain in games that are running maxed anyways.
RussianSensation - Thursday, December 22, 2011 - link
Is this comment supposed to be taken seriously? Go troll somewhere else.