AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher, Cont
Having established what’s bad about VLIW as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).

A Single GCN SIMD
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
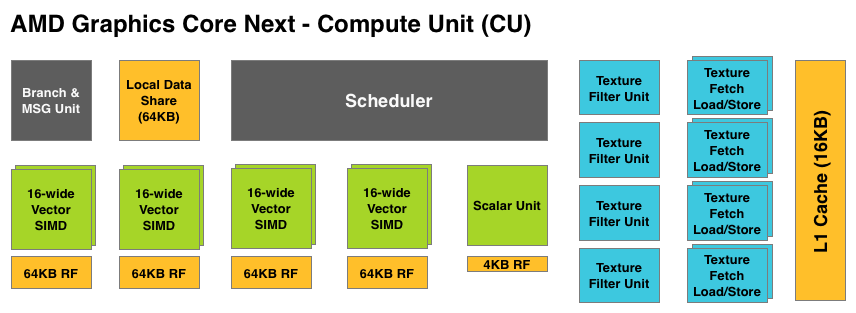
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
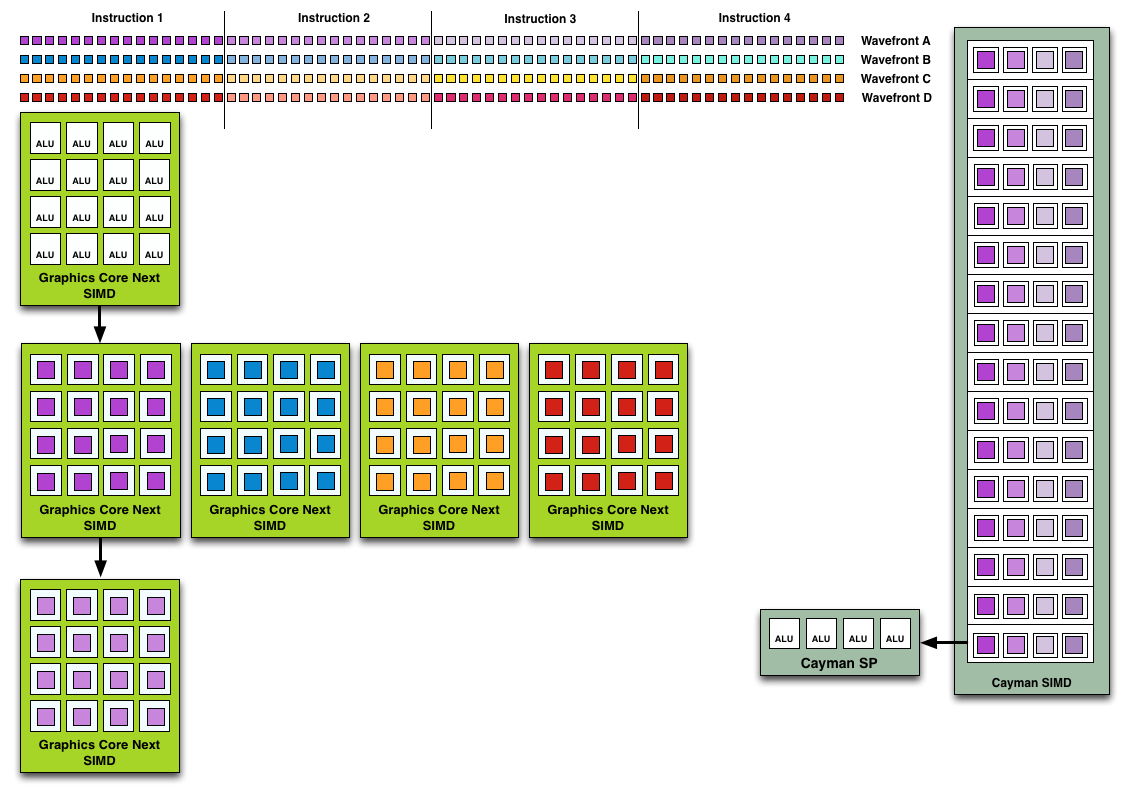
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup. Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
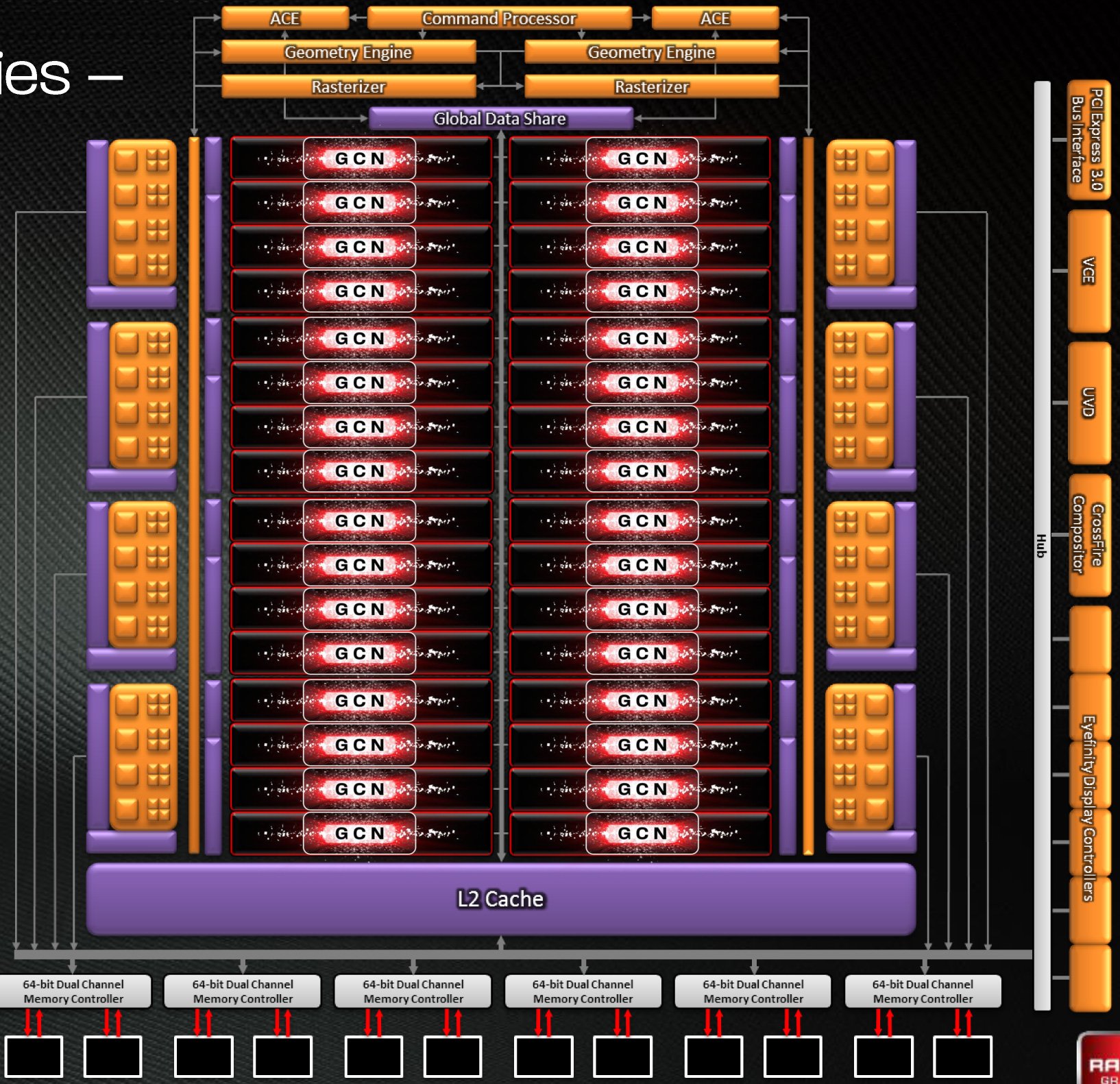
At the end of the day if AMD has done their homework GCN should significantly improve compute performance relative to VLIW4 while gaming performance should be just as good. Gaming shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. And for games that use compute shaders, they should directly benefit from the compute improvements. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing gaming performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.








292 Comments
View All Comments
Ryan Smith - Thursday, December 22, 2011 - link
Since 1920x1200 has already been commented on elsewhere I'm just going to jump right to your comment on minimum FPS.I completely agree, and we're trying to add it where it makes sense. A lot of benchmarks are wildly inconsistent about their minimum FPS, largely thanks to the fact that minimum FPS is an instantaneous data point. When your values vary by 20%+ per run (as minimums often do), even averaging repeated trials isn't nearly accurate enough to present meaningful results.
CeriseCogburn - Thursday, March 8, 2012 - link
HardOCP shows long in game fps per second charts that show dips and bottom outs are more than one momentary lapse and often are extended time periods of lowest frame rate runs, so I have to respectfully disagree.Perhaps the fault is fraps can show you a single instance of lowest frame rate number, and hence it's the analysis that utterly fails - given the time constraints that were made obvious, it is also clear that the extra work it would take for an easily reasoned and reasonable result that is actually of worthy accuracy is not in the cards here.
thunderising - Thursday, December 22, 2011 - link
Okay. This card has left me thrilled, but wanting for more. Why?Well, for example, every reviewer has hit the CCC Core and Memory Max Limits, which turns into a healthy 10-12% performance boost, all for 10W.
What, legit reviews got it to 1165MHz core and 6550Mhz memory for a 21-24% increase in performance. Now that's HUGE!
I think AMD could have gone for something like this with the final clocks, to squeeze out every last bit of performance from this amazing card:
Core - 1050 MHz
Memory - 1500 MHz (6000MHz QDR)
This was not only easily achievable, but would have placed this card at a 8-10% increase in performance all for a mere <10W rise in Load Power.
Hoping for AIBs like Sapphire to show their magic! HD7970 Toxic, MmmmmmM...
Otherwise, fantastic card I say.
Death666Angel - Friday, December 23, 2011 - link
Maybe they'll do a 4870/4890 thing again? Launch the HD7970 and HD7970X2 and then launch a HD7990 with higher clocks later to counter nVidia.... Who knows. :-)Mishera - Sunday, December 25, 2011 - link
They've been doing it for quite some time now. Their plan has been to release a chip balancing die size, performance, and cost. Then later to compete on high end release a dual-chip card. Anand wrote on this a while ago with the rv770 story (http://www.anandtech.com/show/2679).Even looking at the picture of chip sizes, the 7970 is still a reasonable size. And this really was a brilliant move as though Nvidia has half the marketshare and does make a lot of money from their cards, their design philosophy has been hurting them a lot from a business standpoint.
On a side note, Amd really made a great choice by choosing to wait until now to push for general computing. Though that probably means more people to support development and drivers, which means more hiring which is the opposite way Amd has been going. It will be interesting to see how this dichotomy will develop in the future. But right now kudos to Amd.
CeriseCogburn - Thursday, March 8, 2012 - link
Does that mean amd is abandoning gamers as we heard the scream whilst Nvidia was doing thus ?I don't quite get it - now what nvidia did that hurt them, is praise worthy since amd did it, finally.
Forgive me as I scoff at the immense dichotomy...
"Perfect ripeness at the perfect time" - sorry not buying it....
privatosan - Thursday, December 22, 2011 - link
PRT is a nice feature, but there is an failure in the article:'For AMD’s technology each tile will be 64KB, which for an uncompressed 32bit texture would be enough room for a 4K x 4K chunk.'
The tile would be 128 x 128 texels; 4K x 4K would be quite big for a tile.
futrtrubl - Thursday, December 22, 2011 - link
I was going to comment on that too. A 4k x 4k x 32bit (4byte) texture chunk would be around 67MB uncompressed. For a 32bit texture you could only fit a 128x128 array in a 64KB chunk. An 8bit/pixel texture could be 4k*4kStonedofmoo - Thursday, December 22, 2011 - link
Thanks for the review. A request though...To the hardware sites doing these reviews, many of us in this day and age run dual monitor or more. It always frustrates in me in these reviews that we get a long write up on the power saving techniques the new cards use, and never any mention of it helps those of us running more than one display.
For those not in the know, if you run more than one display on all the current generations the cards do NOT downclock the GPU and memory nearly as much as they do on single montor configurations. This burns quite a lot more power and obviously kicks out more heat. No site ever mentions this which is odd considering so many of us have more than one display these days.
I would happily buy the card that finally overcomes this and actually finds a way of knocking back the clocks with multi-monitor setups. Is the new Radeon 7xxx series that card?
Galcobar - Thursday, December 22, 2011 - link
It's in the article, on the page entitled "Meet the Radeon 7970."Ryan also replied to a similar comment by quoting the paragraph addressing multi-monitor setups and power consumption at the top of page of the comments.
That's two mentions, and the answer to your question.