NVIDIA’s Maximus Technology: Quadro + Tesla, Launching Today
by Ryan Smith on November 14, 2011 9:00 AM ESTNVIDIA’s Maximus Technology – Quadro + Tesla, Launching Today
Back at SIGGRAPH 2011 NVIDIA announced Project Maximus, an interesting technology initiative to allow customers to combine Tesla and Quadro products together in a single workstation and to use their respective strengths. At the time NVIDIA didn’t have a launch date to announce, but as this is a software technology rather than a hardware product, the assumption has always been that it would be a quick turnaround. And a quick turnaround it has been: just over 3 months later NVIDIA is officially launching Project Maximus as NVIDIA Maximus Technology.

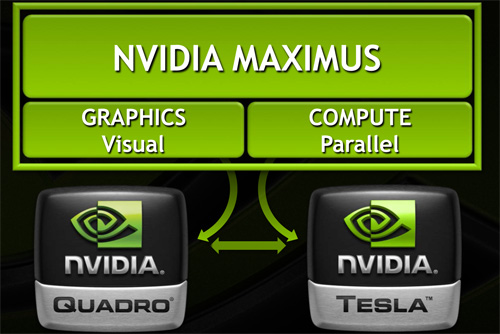
So what is Maximus Technology? As NVIDIA likes to reiterate to their customers it’s not a new product, it’s a new technology – a new way to use NVIDIA’s existing Quadro and Tesla products together. There’s no new hardware involved, just new features in NVIDIAs drivers and new hooks exposed to application developers. Or put more succinctly, in the same vein that Optimus was a driver technology to allow the transparent combination of NVIDIA mobile GPUs with Intel IGPs, Maximus is a driver technology to allow the transparent combination of NVIDIA’s Quadro and Tesla products.
With Maximus NVIDIA is seeking to do a few different things, all of which come back to a single concept: utilizing Quadro and Tesla cards together at the tasks they’re best suited at. This means using Quadro cards for graphical tasks while using Tesla for compute tasks where direct graphical rendering isn’t necessary. Ultimately this seems like an odd concept at first – high end Quadros are fully compute capable too – but it’s something that makes more sense once we look at the current technical limitations of NVIDIA’s hardware, and what use cases they’re proposing.
Combining Quadro & Tesla: The Technical Details
The fundamental base of Maximus is NVIDIA’s drivers. For Maximus NVIDIA needed to bring Quadro and Tesla together under a single driver, as they previously used separate drivers. NVIDIA has used a shared code base for many years now, so Tesla and Quadro (and GeForce) were both forks of the same drivers, but those forks needed to be brought together. This is harder than it sounds as while Quadro drivers are rather straightforward – graphical rendering without all the performance shortcuts and with support for more esoteric features like external synchronization sources – Tesla has a number of unique optimizations, primarily the Tesla Compute Cluster driver, which moved Tesla out from under Windows’ control as a graphical device.
The issue with the forks had to be resolved, and the result was that NVIDIA was finally able to merge the codebase back into a single Quadro/Tesla driver as of July with the 275.xx driver series.
But this isn’t just about combining driver codebases. Making Tesla and Quadro work in a single workstation resolves the hardware issues but it leaves the software side untouched. For some time now CUDA developers have been able to select what device to send a compute task to in a system with multiple CUDA devices, but this is by definition an extra development step. Developers had to work in support for multiple CUDA devices, and in most cases needed to expose controls to the user so that users could make the final allocations. This works well enough in the hands of knowledgeable users, but NVIDIA’s CUDA strategy has always been about pushing CUDA farther and deeper in the world in order to make it more ubiquitous, and this means it always needs to become easier to use.
This brings us back to Optimus. With Optimus NVIDIA’s goal was to replace manual GPU muxing with a fully transparent system so that users never needed to take any extra steps to use a mobile GeForce GPU alongside Intel’s IGPs, or for that matter concern themselves with what GPU was being used. Optimus would – and did – take care of it all by sending lightweight workloads to the IGP while games and certain other significant workloads were sent to the NVIDIA GPU.
Maximus embodies a concept very similar to this, except with Maximus it’s about transparently allocating compute workloads to the appropriate GPU. With a unified driver base for Tesla and Quadro, NVIDIA’s drivers can present both devices to an application as usable CUDA devices. Maximus takes this to its logical conclusion by taking the initiative to direct compute workloads to the Tesla device; CUDA device allocation becomes a transparent operation to users and developers alike, just like GPU muxing under Optimus. Workloads can of course still be manually controlled, but at the end of the day NVIDIA wants developers to sit back and do nothing, and leave device allocation up to NVIDIA.
As with Optimus, NVIDIA’s desires here are rather straightforward: the harder something is to use, the slower the adoption. Optimus made it easier to get NVIDIA GPUs in laptops, and Maximus will make it easier to get CUDA adopted by more programs. Requiring developers to do any extra work to use CUDA is just one more thing that can go wrong and keep CUDA from being implemented, which in turn removes a reason for hardware buyers to purchase a high-end NVIDIA product.








29 Comments
View All Comments
MrSpadge - Monday, November 14, 2011 - link
Short answer: no.The chips are the same, but it's hard-wired which functionality they are allowed to expose. The professional cards also have ECC memory.. but anyone asking for an unlock probably wouldn't be terribly interested in this anyway ;)
MrS
hpvd - Monday, November 14, 2011 - link
will the quadro be automatically used for cuda calculation if their ist no strong graphic load on it?Or do I loose its compute power completely if I put in an additional Tesla??
if it could be used for computing together with the new tesla: What happens if graphic load increase?
will there be a smooth transition? eg
Tesla: compute load 100% , graphic load 0%
Quadro: compute load 30%, graphic load 70%
?
Ryan Smith - Monday, November 14, 2011 - link
It's going to depend on the software you're using. If the compute load can easily be split among multiple CUDA devices, then you can still use both the Quadro and the Tesla for compute as long as the software has a way to select this.NVIDIA has a case study video of 3ds Max where they show off compute device selection: http://www.youtube.com/watch?v=xCIAsvT5mYo
However using both cards for compute automatically doesn't seem like it's possible right now. Keep in mind that NVIDIA's favorite pairing is the Quadro 2000 - a GF106 part - with the C2075, so the Q2000 isn't even in the same league as the C2075. In any case if you did assign compute workloads to both GPUs, then things would be graphically sluggish until the application in question terminated the load on the Quadro.
Havor - Tuesday, November 15, 2011 - link
Dose Open CL not cover the same goals as this Maximus, so why use Maximus?Specially if you can use a open standard, used by all big players.
How good your product works with OpenCL depends on how good your drivers are, so why not focus on that and have the best product with the best OpenCL drivers?
It looks to me this is one of these product ware some will fall for the marketing crap, but as a product it will fail in the long run.
Dribble - Tuesday, November 15, 2011 - link
No, Maximus is a way of using compute hardware. Open CL is compute software that competes with CUDA. I would have thought the nvidia hardware does support open cl, but everyone uses CUDA because it's much more advanced.Nenad - Tuesday, November 15, 2011 - link
Why not allowing Tesla+GeForce?So far Nvidia was marketing cards more or less like:
- GeForce : primarily graphics/video
- Tesla: primarily/only compute
- Quadro: equaly capable of compute and graphics
Now with Maximus they say "if you have Quadro and Tesla, use Quadro for graphics and Tesla for compute", but that leaves one question:
If so far it was GeForce that was best suited for graphics (and its cheaper and much better performance/$ than Quadro for graphics), then why would someone want to buy Quadro just to limit it to graphics?
Why instead not allowing to have cheaper but faster GeForce (like GTX580), and pair it with Tesla in Maximus?
jecs - Wednesday, November 16, 2011 - link
It all depends on the Nvidia license and not on the hardware used.Look at it this way: If Nvidia allowed you to use GeForces on professional applications you either would have to pay the price difference to buy the additional "Quadro Drivers".
The important part here are the very specilized drivers Nvidia only allows to run with qualified Quadros or Tesla cards.
Quadro and Tesla class Drivers are very expensive in R&D, Nvidia puts to many engineering resources in the professional drivers, but those licenses are only distributed (sold) on a smaller professional user base and the why these drivers cost more even if used on a very similar hardware.
Also you can't use a Quadro driver on any similar GeForce because is illegal, sometimes there is not and equivalent hardware on the GeForce side and also because Nvidia physically fixes the installation on the card with transistors.
Freakie - Sunday, November 20, 2011 - link
PhysX, now for workstations! Unless I'm understanding it a bit wrong... but PhysX is quite similar in theory, is it not? Compute the physics of specific things (explosions/smoke/plasma cannon) with a separate card so that you have more realistic effects in your game, and then use a more powerful card to actually display everything else in the game. This is just reversing the power roles.Hobstob - Saturday, May 5, 2012 - link
It is extremely outdated! Why have they not released a new Line of quadro cards? Are they even planning on releasing a new line of card for workstations?