AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTCompute & Tessellation
Moving on from our look at gaming performance, we have our customary look at compute performance, bundled with a look at theoretical tessellation performance. This will give us our best chance to not only look at the theoretical aspects of AMD’s tessellation improvements, but to isolate shader performance to see whether AMD’s theoretical performance advantages and disadvantages from VLIW4 map out to real world scenarios.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes.

Civilization V’s compute shader benchmark has always benefitted NVIDIA, but that’s not the real story here. The real story is just how poorly the 6900 series does compared to the 5870. The 6970 barely does better than the 5850, meanwhile the 6950 is closest to NVIDIA’s GTX 460, the 768MB version. If what AMD says is true about the Cayman shader compiler needing some further optimization, then this is benchmark where that’s readily apparent. As an application of GPU computing, we’d expect the 6900 series to do at least somewhat better than the 5870, not notably worse.
Our second GPU compute benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. While it’s still in beta, SmallLuxGPU recently hit a milestone by implementing a complete ray tracing engine in OpenCL, allowing them to fully offload the process to the GPU. It’s this ray tracing engine we’re testing.

Unlike Civ 5, SmallLuxGPU’s performance is much closer to where things should be theoretically. Even with all of AMD’s shader changes both the 5870 and 6970 have a theoretical 2.7 TFLOPs of compute performance, and SmallLuxGPU backs up that number. The 5870 and 6970 are virtually tied, exactly where we’d expect our performance to be if everything is running under reasonably optimal conditions. Note that this means that the 6950 and 6970 both outperform the GTX 580 here, as SmallLuxGPU does a good job setting AMD’s drivers up to extract ILP out of the OpenCL kernel it uses.
Our final compute benchmark is Cyberlink’s MediaEspresso 6, the latest version of their GPU-accelerated video encoding suite. MediaEspresso 6 doesn’t currently utilize a common API, and instead has codepaths for both AMD’s APP and NVIDIA’s CUDA APIs, which gives us a chance to test each API with a common program bridging them. As we’ll see this doesn’t necessarily mean that MediaEspresso behaves similarly on both AMD and NVIDIA GPUs, but for MediaEspresso users it is what it is.
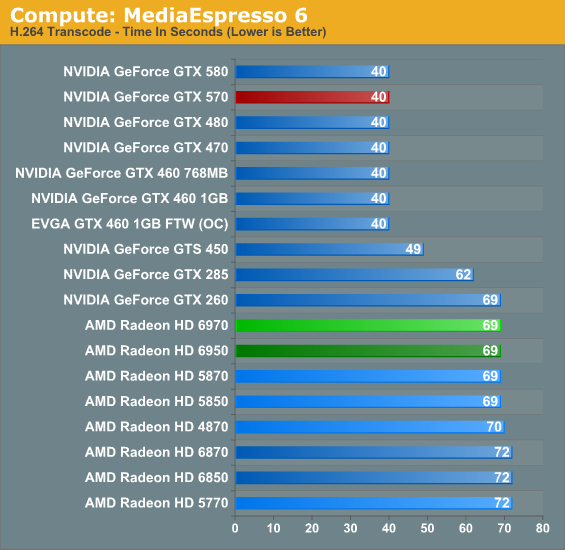
MediaEspresso 6 quickly gets CPU bottlenecked when paired with a faster GPU, leading to our clusters of results. For the 6900 series this mostly serves as a sanity check, proving that transcoding performance has not slipped even with AMD’s new architecture.
At the other end of the spectrum from GPU computing performance is GPU tessellation performance, used exclusively for graphical purposes. For the Radeon 6900 series, AMD significantly enhanced their tessellation by doubling up on tessellation units and the graphic engines they reside in, which can result in up to 3x the tessellation performance over the 5870. In order to analyze the performance of AMD’s enhanced tessellator, we’re using the Unigine Heaven benchmark and Microsoft’s DirectX 11 Detail Tessellation sample program to measure the tessellation performance of a few of our cards.
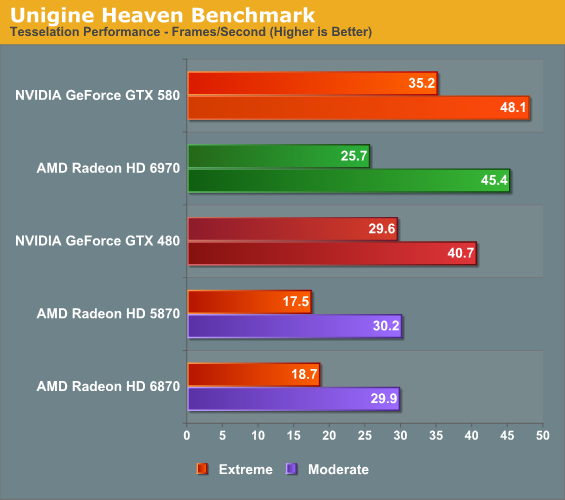
Since Heaven is a synthetic benchmark at the moment (the DX11 engine isn’t currently used in any games) we’re less concerned with performance relative to NVIDIA’s cards and more concerned with performance relative to the 5870. So with AMD’s tessellation improvements we see the 6970 shoot to life on this benchmark, coming in at nearly 50% faster than the 5870 at both moderate and extreme tessellation settings. This is actually on the low end of AMD’s theoretical tessellation performance improvements, but then even the geometrically overpowered GTX 580 doesn’t get such clear gains. But on that note while the 6970 does well at moderate tessellation levels, at extreme tessellation levels it still falls to the more potent GTX 400/500 series.

As for Microsoft’s DirectX 11 Detail Tessellation Sample program, a different story is going on. The 6970 once again shows significant gains over the 5870, but this time not against the 6870. With the 6870 implementing AMD’s tessellation factor optimized tessellator, most of the 6970’s improvements are already accounted for here. At the same time we can still easily see just how much of an advantage NVIDIA’s GTX 400/500 series still has in the theoretical tessellation department.








168 Comments
View All Comments
mac2j - Wednesday, December 15, 2010 - link
Um - if you have the money for a 580 ... pick up another $80-100 and get 2 x 6950 - you'll get nearly the best possible performance on the market at a similar cost.Also I agree that Nvidia will push the 580 price down as much as possible... the problem is that if you believe all of the admittedly "unofficial" breakdowns ... it costs Nvidia 1.5-2x as much to make a 580 as it costs AMD to make a 6970.
So its hard to be sure how far Nvidia can push down the price on the 580 before it ceases to become profitable - my guess is they'll focus on making a 565 type card which has almost 570 performance but for a manufacturing cost closer to what a 460 runs them.
fausto412 - Wednesday, December 15, 2010 - link
yeah. AMD let us down on this here product. We see what gtx580 is and what 6970 is...i would say if you planning to spend 500...the gtx580 is worth it.truepurple - Wednesday, December 15, 2010 - link
"support for color correction in linear space"What does that mean?
Ryan Smith - Wednesday, December 15, 2010 - link
There are two common ways to represent color, linear and gamma.Linear: Used for rendering an image. More generally linear has a simple, fixed relationship between X and Y, such that if you drew the relationship it would be a straight line. A linear system is easy to work with because of the simple relationship.
Gamma: Used for final display purposes. It's a non-linear colorspace that was originally used because CRTs are inherently non-linear devices. If you drew out the relationship, it would be a curved line. The 5000 series is unable to apply color correction in linear space and has to apply it in gamma space, which for the purposes of color correction is not as accurate.
IceDread - Wednesday, December 15, 2010 - link
Yet again we do not get to see hd 5970 in crossfire despite it being a single card! Is this an nvidia site?Anyway, for those of you who do want to see those results, here is a link to a professional Swedish site!
http://www.sweclockers.com/recension/13175-amd-rad...
Maybe there is some google translation available or so if you want to understand more than the charts shows.
medi01 - Wednesday, December 15, 2010 - link
Wow, 5970 in crossfire consumes less than 580 in SLI.http://www.sweclockers.com/recension/13175-amd-rad...
ggathagan - Wednesday, December 15, 2010 - link
Absolutely!!!There's no way on God's green earth that Anandtech doesn't currently have a pair of 5970's on hand, so that MUST be the reason.
I'll go talk to Anand and Ryan right now!!!!
Oh, wait, they're on a conference call with Huang Jen-Hsun.....
I'd like to note that I do not believe Anadtech ever did a test of two 5970's, so it's somewhat difficult to supply non-existent into any review.
Ryan did a single card test in November 2009.That is the only review I've found of any 5970's on the site.
vectorm12 - Wednesday, December 15, 2010 - link
I was not aware of the fact that the 32nm process had been canned completely and was still expecting the 6970 to blow the 580 out of the water.Although we can't possibly know and are unlikely to ever find out what cayman at 32nm would have performed like I suspect AMD had to give up a good chunk of performance to fit it on the 389mm^2 40nm die.
This really makes my choice easy as I'll pickup another cheap 5870 and run my system in CF.
I think I'll be able to live with the performance until the refreshed cayman/next gen GPUs are ready for prime time.
Ryan: I'd really like to see what ighashgpu can do with the new 6970 cards though. Although you produce a few GPGPU charts I feel like none of them really represent the real "number-crunching" performance of the 6970/6950.
Ivan has already posted his analysis in his blog and it seems like the change from LWIV5 to LWIV4 made a negligible impact at the most. However I'd really love to see ighashgpu included in future GPU tests to test new GPUs and architectures.
Thanks for the site and keep up the work guys!
slagar - Wednesday, December 15, 2010 - link
Gaming seems to be in the process of bursting its own bubble. Graphics of games isn't keeping up with the hardware (unless you cound gaming on 6 monitors) because most developers are still targeting consoles with much older technology.Consoles won't upgrade for a few more years, and even then, I'm wondering how far we are from "the final console generation". Visual improvements in graphics are becoming quite incremental, so it's harder to "wow" consumers into buying your product, and the costs for developers is increasing, so it's becoming harder for developers to meet these standards. Tools will always improve and make things easier and more streamlined over time I suppose, but still... it's going to be an interesting decade ahead of us :)
darckhart - Wednesday, December 15, 2010 - link
that's not entirely true. the hardware now allows not only insanely high resolutions, but it also lets those of us with more stringent IQ requirements (large custom texture mods, SSAA modes, etc) to run at acceptable framerates at high res in intense action spots.