AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTAdvancing Primitives: Dual Graphics Engines & New ROPs
AMD has clearly taken NVIDIA’s comments on geometry performance to heart. Along with issuing their manifesto with the 6800 series, they’ve also been working on their own improvements for their geometry performance. As a result AMD’s fixed function Graphics Engine block is seeing some major improvements for Cayman.
Prior to Cypress, AMD had 1 graphics engine, which contained 1 each of the fundamental blocks: the rasterizers/hierarchical-Z units, the geometry/vertex assemblers, and the tessellator. With Cypress AMD added a 2nd rasterizer and 2nd hierarchical-Z unit, allowing them to set up 32 pixels per clock as opposed to 16 pixels per clock. However while AMD doubled part of the graphics engine, they did not double the entirety of it, meaning their primitive throughput rate was still 1 primitive/clock, a typical throughput rate even at the time.
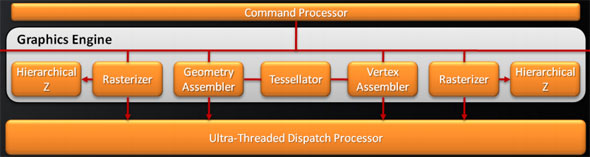
Cypress's Graphics Engine
In 2010 with the launch of Fermi, NVIDIA raised the bar on primitive performance, with rasterization moved to NVIDIA’s GPCs, NVIDIA could theoretically push out as many primitives/clock as they had GPCs, in the case of GF100/GF110 pushing this to 4 primitives/clock, a simply massive improvement in geometry performance for a single generation.
With Cayman AMD is catching up with NVIDIA by increasing their own primitive throughput rate, though not by as much as NVIDIA did with Fermi. For Cayman the rest of the graphics engine is being fully duplicated – Cayman will have 2 separate graphics engines, each containing one fundamental block, and each capable of pushing out 1 primitive/clock. Between the two of them AMD’s maximum primitive throughput rate will now be 2 primitives/clock; half as much as NVIDIA but twice that of Cypress.
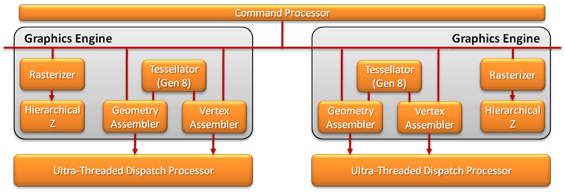
Cayman's Dual Graphics Engines
As was the case for NVIDIA, splitting up rasterization and tessellation is not a straightforward and easy task. For AMD this meant teaching the graphics engine how to do tile-based load balancing so that the workload being spread among the graphics engines is being kept as balanced as possible. Furthermore AMD believes they have an edge on NVIDIA when it comes to design - AMD can scale the number of eraphics engines at will, whereas NVIDIA has to work within the logical confines of their GPC/SM/SP ratios. This tidbit would seem to be particularly important for future products, when AMD looks to scale beyond 2 graphics engines.
At the end of the day all of this tinking with the graphics engines is necessary in order for AMD to further improve their tessellation performance. AMD’s 7th generation tessellator improved their performance at lower tessellation factors where the tessellator was the bottleneck, but at higher tessellation factors the graphics engine itself is the bottleneck as the graphics engine gets swamped with more incoming primitives than it can set up in a single clock. By having two graphics engines and a 2-primitive/clock rasterization rate, AMD is shifting the burden back away from the graphics engine.
Just having two 7th generation-like tessellators goes a long way towards improving AMD’s tessellation performance. However all of that geometry can still lead to a bottleneck at times, which means it needs to be stored somewhere until it can be processed. As AMD has not changed any cache sizes for Cayman, there’s the same amount of cache for potentially thrice as much geometry, so in order to keep things flowing that geometry has to go somewhere. That somewhere is the GPU’s RAM, or as AMD likes to put it, their “off-chip buffer.” Compared to cache access RAM is slow and hence this isn’t necessarily a desirable action, but it’s much, much better than stalling the pipeline entirely while the rasterizers clear out the backlog.
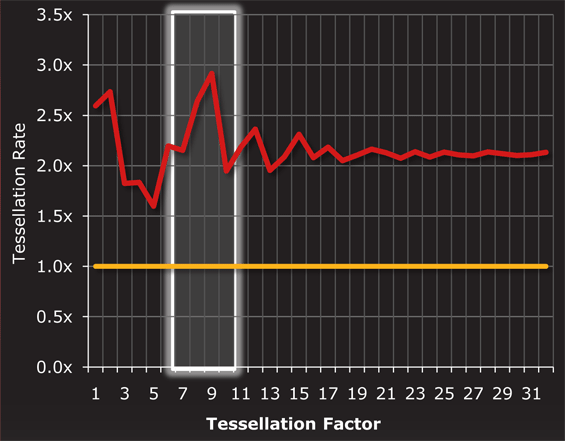
Red = 6970. Yellow = 5870
Overall, clock for clock tessellation performance is anywhere between 1.5x and 3x that of Cypress. In situations where AMD’s already improved tessellation performance at lower tessellation factors plays a part, AMD approaches 3x performance; while at around a factor of 5 the performance drops to near 1.5x. Elsewhere performance is around 2x that of Cypress, representing the doubling of graphics engines.
Tessellation also plays a factor in AMD’s other major gaming-related improvement: ROP performance. As tessellation produces many mini triangles, these triangles begin to choke the ROPs when performing MSAA. Although tessellation isn’t the only reason, it certainly plays a factor in AMD’s reasoning for improving their ROPs to improve MSAA performance.
The 32 ROPs (the same as Cypress) have been tweaked to speed up processing of certain types of values. In the case of both signed and unsigned normalized INT16s, these operations are now 2x faster. Meanwhile FP32 operations are now 2x to 4x faster depending on the scenario. Finally, similar to shader read ops for compute purposes, ROP write ops for graphics purposes can be coalesced, improving performance by requiring fewer operations.








168 Comments
View All Comments
AnnonymousCoward - Wednesday, December 15, 2010 - link
First of all, 30fps is choppy as hell in a non-RTS game. ~40fps is a bare minimum, and >60fps all the time is hugely preferred since then you can also use vsync to eliminate tearing.Now back to my point. Your counter was "you know that non-AA will be higher than AA, so why measure it?" Is that a point? Different cards will scale differently, and seeing 2560+AA doesn't tell us the performance landscape at real-world usage which is 2560 no-AA.
Dug - Wednesday, December 15, 2010 - link
Is it me, or are the graphs confusing.Some leave out cards on certain resolutions, but add some in others.
It would be nice to have a dynamic graph link so we can make our own comparisons.
Or a drop down to limit just ati, single card, etc.
Either that or make a graph that has the cards tested at all the resolutions so there is the same number of cards in each graph.
benjwp - Wednesday, December 15, 2010 - link
Hi,You keep using Wolfenstein as an OpenGL benchmark. But it is not. The single player portion uses Direct3D9. You can check this by checking which DLLs it loads or which functions it imports or many other ways (for example most of the idTech4 renderer debug commands no longer work).
The multiplayer component does use OpenGL though.
Your best bet for an OpenGL gaming benchmark is probably Enemy Territory Quake Wars.
Ryan Smith - Wednesday, December 15, 2010 - link
We use WolfMP, not WolfSP (you can't record or playback timedemos in SP).7Enigma - Wednesday, December 15, 2010 - link
Hi Ryan,What benchmark do you use for the noise testing? Is it Crysis or Furmark? Along the same line of questioning I do not think you can use Furmark in the way you have the graph setup because it looks like you have left Powertune on (which will throttle the power consumption) while using numbers from NVIDIA's cards where you have faked the drivers into not throttling. I understand one is a program cheat and another a TDP limitation, but it seems a bit wrong to not compare them in the unmodified position (or VERBALLY mention this had no bearing on the test and they should not be compared).
Overall nice review, but the new cards are pretty underwhelming IMO.
Ryan Smith - Thursday, December 16, 2010 - link
Hi 7Enigma;For noise testing it's FurMark. As is the case with the rest of our power/temp/noise benchmarks, we want to establish the worst case scenario for these products and compare them along those lines. So the noise results you see are derived from the same tests we do for temperatures and power draw.
And yes, we did leave PowerTune at its default settings. How we test power/temp/noise is one of the things PowerTune made us reevaluate. Our decision is that we'll continue to use whatever method generates the worst case scenario for that card at default settings. For NVIDIA's GTX 500 series, this means disabling OCP because NVIDIA only clamps FurMark/OCCT, and to a level below most games at that. Other games like Program X that we used in the initial GTX 580 article clearly establish that power/temp/noise can and do get much worse than what Crysis or clamped FurMark will show you.
As for the AMD cards the situation is much more straightforward: PowerTune clamps everything blindly. We still use FurMark because it generates the highest load we can find (even with it being reduced by over 200MHz), however because PowerTune clamps everything, our FurMark results are the worst case scenario for that card. Absolutely nothing will generate a significantly higher load - PowerTune won't allow it. So we consider it accurate for the purposes of establishing the worst case scenario for noise.
In the long run this means that results will come down as newer cards implement this kind of technology, but then that's the advantage of such technology: there's no way to make the card louder without playing wit the card's settings. For the next iteration of the benchmark suite we will likely implement a game-based noise test, even though technologies like PowerTune are reducing the dynamic range.
In conclusion: we use FurMark, we will disable any TDP limiting technology that discriminates based on the program type or is based on a known program list, and we will allow any TDP limiting technology that blindly establishes a firm TDP cap for all programs and games.
-Thanks
Ryan Smith
7Enigma - Friday, December 17, 2010 - link
Thanks for the response Ryan! I expected it to be lost in the slew of other posts. I highly recommend (as you mentioned in your second to last paragraph) that a game-based benchmark is used along with the Furmark for power/noise. Until both adopt the same TDP limitation it's going to put the NVIDIA cards in a bad light when comparisons are made. This could be seen as a legitimate beef for the fanboys/trolls, and we all know the less ammunition they have the better. :)Also to prevent future confusion it would be nice to have what program you are using for the power draw/noise/heat IN the graph title itself. Just something as simple as "GPU Temperature (Furmark-Load)" would make it instantly understandable.
Thanks again for the very detailed review (on 1 week nonetheless!)
Hrel - Wednesday, December 15, 2010 - link
I really hope these architexture changes lead to better minimum FPS results. AMD is ALWAYS behind Nvidia on minimum FPS and in many ways that's the most important measurment since min FPS determines if the game is playable or not. I dont' care if it maxes out 122 FPS if when the shit hits the fan I get 15 FPS, I won't be able to accurately hit anything.Soldier1969 - Wednesday, December 15, 2010 - link
I'm dissapointed in the 6970, its not what I was expecting over my 5870. I will wait to see what the 6990 brings to the table next month. I'm looking for a 30-40% boost from my 5870 at 2560 x 1600 res I game at.stangflyer - Wednesday, December 15, 2010 - link
Now that we see the power requirements for the 6970 and that it needs more power than the 5870 how would they make a 6990 without really cutting off the performance like the 5970?I had a 5970 for a year b4 selling it 3 weeks ago in preparation of getting 570 in sli or 6990.
It would obviously have to be 2x8 pin power! Or they would have to really use that powertune feature.
I liked my 5970 as I didn't have the stuttering issues (or i don't notice them) And actually have no issues with eyefinity as i have matching dell monitors with native dp inputs.
If I was only on one screen I would not even be thinking upgrade but the vram runs out when using aa or keeping settings high as I play at 5040x1050. That is the only reason I am a little shy of getting the 570 in sli.
Don't see how they can make a 6990 without really killing the performance of it.
I used my 5970 at 5870 and beyond speeds on games all the time though.