AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTAdvancing Primitives: Dual Graphics Engines & New ROPs
AMD has clearly taken NVIDIA’s comments on geometry performance to heart. Along with issuing their manifesto with the 6800 series, they’ve also been working on their own improvements for their geometry performance. As a result AMD’s fixed function Graphics Engine block is seeing some major improvements for Cayman.
Prior to Cypress, AMD had 1 graphics engine, which contained 1 each of the fundamental blocks: the rasterizers/hierarchical-Z units, the geometry/vertex assemblers, and the tessellator. With Cypress AMD added a 2nd rasterizer and 2nd hierarchical-Z unit, allowing them to set up 32 pixels per clock as opposed to 16 pixels per clock. However while AMD doubled part of the graphics engine, they did not double the entirety of it, meaning their primitive throughput rate was still 1 primitive/clock, a typical throughput rate even at the time.
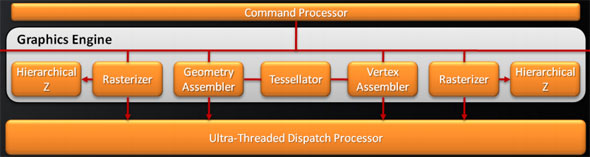
Cypress's Graphics Engine
In 2010 with the launch of Fermi, NVIDIA raised the bar on primitive performance, with rasterization moved to NVIDIA’s GPCs, NVIDIA could theoretically push out as many primitives/clock as they had GPCs, in the case of GF100/GF110 pushing this to 4 primitives/clock, a simply massive improvement in geometry performance for a single generation.
With Cayman AMD is catching up with NVIDIA by increasing their own primitive throughput rate, though not by as much as NVIDIA did with Fermi. For Cayman the rest of the graphics engine is being fully duplicated – Cayman will have 2 separate graphics engines, each containing one fundamental block, and each capable of pushing out 1 primitive/clock. Between the two of them AMD’s maximum primitive throughput rate will now be 2 primitives/clock; half as much as NVIDIA but twice that of Cypress.
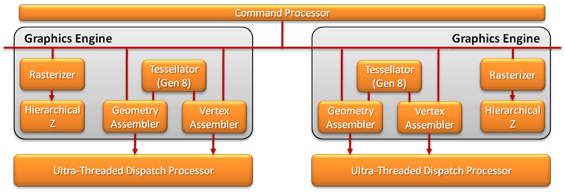
Cayman's Dual Graphics Engines
As was the case for NVIDIA, splitting up rasterization and tessellation is not a straightforward and easy task. For AMD this meant teaching the graphics engine how to do tile-based load balancing so that the workload being spread among the graphics engines is being kept as balanced as possible. Furthermore AMD believes they have an edge on NVIDIA when it comes to design - AMD can scale the number of eraphics engines at will, whereas NVIDIA has to work within the logical confines of their GPC/SM/SP ratios. This tidbit would seem to be particularly important for future products, when AMD looks to scale beyond 2 graphics engines.
At the end of the day all of this tinking with the graphics engines is necessary in order for AMD to further improve their tessellation performance. AMD’s 7th generation tessellator improved their performance at lower tessellation factors where the tessellator was the bottleneck, but at higher tessellation factors the graphics engine itself is the bottleneck as the graphics engine gets swamped with more incoming primitives than it can set up in a single clock. By having two graphics engines and a 2-primitive/clock rasterization rate, AMD is shifting the burden back away from the graphics engine.
Just having two 7th generation-like tessellators goes a long way towards improving AMD’s tessellation performance. However all of that geometry can still lead to a bottleneck at times, which means it needs to be stored somewhere until it can be processed. As AMD has not changed any cache sizes for Cayman, there’s the same amount of cache for potentially thrice as much geometry, so in order to keep things flowing that geometry has to go somewhere. That somewhere is the GPU’s RAM, or as AMD likes to put it, their “off-chip buffer.” Compared to cache access RAM is slow and hence this isn’t necessarily a desirable action, but it’s much, much better than stalling the pipeline entirely while the rasterizers clear out the backlog.
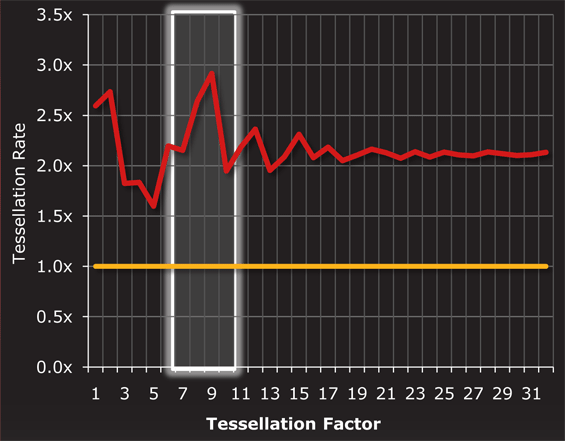
Red = 6970. Yellow = 5870
Overall, clock for clock tessellation performance is anywhere between 1.5x and 3x that of Cypress. In situations where AMD’s already improved tessellation performance at lower tessellation factors plays a part, AMD approaches 3x performance; while at around a factor of 5 the performance drops to near 1.5x. Elsewhere performance is around 2x that of Cypress, representing the doubling of graphics engines.
Tessellation also plays a factor in AMD’s other major gaming-related improvement: ROP performance. As tessellation produces many mini triangles, these triangles begin to choke the ROPs when performing MSAA. Although tessellation isn’t the only reason, it certainly plays a factor in AMD’s reasoning for improving their ROPs to improve MSAA performance.
The 32 ROPs (the same as Cypress) have been tweaked to speed up processing of certain types of values. In the case of both signed and unsigned normalized INT16s, these operations are now 2x faster. Meanwhile FP32 operations are now 2x to 4x faster depending on the scenario. Finally, similar to shader read ops for compute purposes, ROP write ops for graphics purposes can be coalesced, improving performance by requiring fewer operations.








168 Comments
View All Comments
Ryan Smith - Wednesday, December 15, 2010 - link
Exactly the same as on Cypress.L2: 128KB per ROP block (so 512KB)
L1: 8KB per SIMD
LDS: 32KB per SIMD
GDS: 64KB
http://images.anandtech.com/doci/4061/MidLevelView...
I don't have the register file size readily available.
DanNeely - Wednesday, December 15, 2010 - link
How likely is the decrease from 2 to 1 operations per clock likely to affect real world applications?yeraldin37 - Wednesday, December 15, 2010 - link
My current cards are running at 870Mhz(GPU) and 1100Mhz(clock), faster than stock 5870, those benchmarks for new 6970 are really disappointing, I was seriously expecting to get a single 6970 for Christmas to replace my 5850OC CF cards and make room for additional cards or even have a free pcie to plug my gtx460 for physx capability. I was going to be happy to get at least 80% of my current 5850CF setup from new 6970. what a joke! I will not make any move and wait for upcoming next generation 28nm amd GPU's. We have to be fair and mention all great efforts from AMD team to bring new technology to newest radeon cards, however not enough performance for die hard gamers. If gtx 580 were 20% cheaper I might consider to buy one, I personally never ever pay more than $400 for one(1) video card.Nfarce - Wednesday, December 15, 2010 - link
Reading Tom's Hardware they essentially slam AMD's marketing these cards as a 570-580 beater. Guru3D is also less than friendly. Interstingly, *both* sites have benches showing the 570 an d580 beating the 6950 and 6970 commandingly. What's up with that exactly?fausto412 - Wednesday, December 15, 2010 - link
it's called AMD didn't deliver on the hype...they deserve to get slammed.medi01 - Wednesday, December 15, 2010 - link
AMD delivers cards with better performance/price ratio that also consume less power. How come there is a reason to "slam", eh?zst3250 - Friday, December 31, 2010 - link
Off yourself cretin, prefearbly by getting your cranium kicked in.Mr Perfect - Thursday, December 16, 2010 - link
Wait, is Tom's reputable again? Haven't read that site since the Athlon XP was new....AnnonymousCoward - Wednesday, December 15, 2010 - link
As a 30" owner and gamer, I would never run at 2560x1600 with AA enabled if that causes <60fps. I'd disable AA. Who wouldn't value framerate over AA? So when the fps is <60, please compare cards at 2560x1600 without AA, so that I'm able to apply the results to a purchase decision.SimpJee - Wednesday, December 15, 2010 - link
Greetings, also a 30'' gamer. If you see the FPS above 30 with AA enabled, you can assume it will be (much) higher without it enabled so what's the point in actually having the author bench it without AA? Plus, anything above 30 FPS is just icing on the cake as far as I'm concerned.