AMD’s Radeon HD 6870 & 6850: Renewing Competition in the Mid-Range Market
by Ryan Smith on October 21, 2010 10:08 PM ESTFor a while now we’ve been trying to establish a proper cross-platform compute benchmark suite to add to our GPU articles. It’s not been entirely successful.
While GPUs have been compute capable in some form since 2006 with the launch of G80, and AMD significantly improved their compute capabilities in 2009 with Cypress, the software has been slow to catch on. From gatherings such as NVIDIA’s GTC we’ve seen first-hand how GPU computing is being used in the high-performance computing market, but the consumer side hasn’t materialized as quickly as the right situations for using GPU computing aren’t as straightforward and many developers are unwilling to attach themselves to a single platform in the process.
2009 saw the ratification of OpenCL 1.0 and the launch of DirectCompute, and while the launch of these cross-platform APIs removed some of the roadblocks, we heard as recently as last month from Adobe and others that there’s still work to be done before companies can confidently deploy GPU compute accelerated software. The immaturity of OpenCL drivers was cited as one cause, however there’s also the fact that a lot of computers simply don’t have a suitable compute-capable GPU – it’s Intel that’s the world’s biggest GPU vendor after all.
So here in the fall of 2010 our search for a wide variety of GPU compute applications hasn’t panned out quite like we expected it too. Widespread adoption of GPU computing in consumer applications is still around the corner, so for the time being we have to get creative.
With that in mind we’ve gone ahead and cooked up a new GPU compute benchmark suite based on the software available to us. On the consumer side we have the latest version of Cyberlink’s MediaEspresso video encoding suite and an interesting sub-benchmark from Civilization V. On the professional side we have SmallLuxGPU, an OpenCL based ray tracer. We don’t expect this to be the be all and end all of GPU computing benchmarks, but it gives us a place to start and allows us to cover both cross-platform APIs and NVIDIA & AMD’s platform-specific APIs.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes.
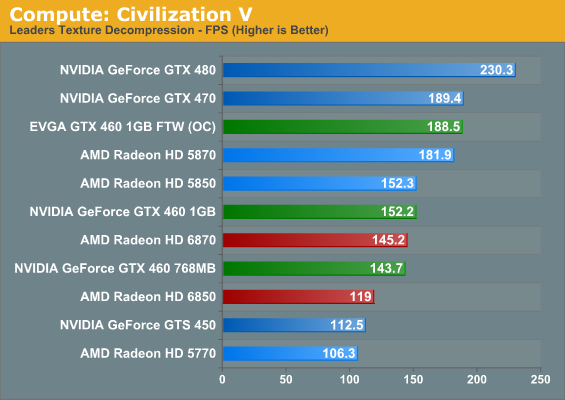
In our look at Civ V’s performance as a game, we noted that it favors NVIDIA’s GPUs at the moment, and this may be part of the reason why. NVIDIA’s GPUs clean up here, particularly when compared to the 6800 series and its reduced shader count. Furthermore within the GPU families the results are very straightforward, with the order following the relative compute power of each GPU. To be fair to AMD they made a conscious decision to not chase GPU computing performance with the 6800 series, but as a result it fares poorly here.
Our second compute benchmark is Cyberlink’s MediaEspresso 6, the latest version of their GPU-accelerated video encoding suite. MediaEspresso 6 doesn’t currently utilize a common API, and instead has codepaths for both AMD’s APP (née Stream) and NVIDIA’s CUDA APIs, which gives us a chance to test each API with a common program bridging them. As we’ll see this doesn’t necessarily mean that MediaEspresso behaves similarly on both AMD and NVIDIA GPUs, but for MediaEspresso users it is what it is.
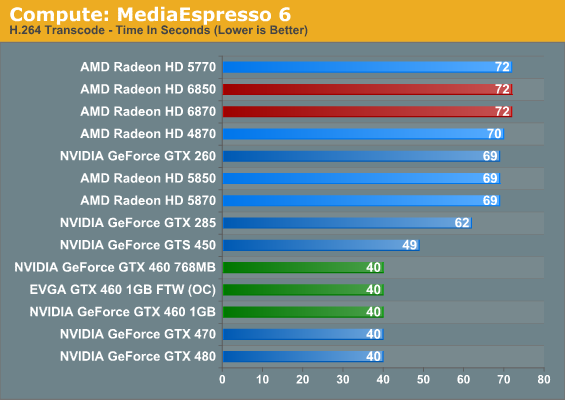
We decided to go ahead and use MediaEspresso in this article not knowing what we’d find, and it turns out the results were both more and less than we were expecting at the same time. While our charts don’t show it, video transcoding isn’t all that GPU intensive with MediaEspresso; once we achieve a certain threshold of compute performance on a GPU – such as a GTX 460 in the case of an NVIDIA card – the rest of the process is CPU bottlenecked. As a result all of our Fermi NVIDIA cards at the GTX 460 or better take just as long to encode our sample video, and while the AMD cards show some stratification, it’s on the order of only a couple of seconds. From this it’s clear that with Cyberlink’s technology having a GPU is going to help, but it can’t completely offload what’s historically been a CPU-intensive activity.
As for an AMD/NVIDIA cross comparison, the results are straightforward but not particularly enlightening. It turns out that MediaEspresso 6 is significantly faster on NVIDIA GPUs than it is on AMD GPUs, but since we’ve already established that MediaEspresso 6 is CPU limited when using these powerful GPUs, it doesn’t say anything about the hardware. AMD and NVIDIA both provide common GPU video encoding frameworks for their products that Cyberlink taps in to, and it’s here where we believe the difference lies.
In particular we see MediaEspresso 6 achieve 50% CPU utilization (4 core) when being used with an NVIDIA GPU, while it only achieves 13% CPU utilization (1 core) with an AMD GPU. At this point it would appear that the CPU portions of NVIDIA’s GPU encoding framework are multithreaded while AMD’s framework is singlethreaded. And since the performance bottleneck for video encoding still lies with the CPU, this would be why the NVIDIA GPUs do so much better than the AMD GPUs in this benchmark.
Our final GPU compute benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. While it’s still in beta, SmallLuxGPU recently hit a milestone by implementing a complete ray tracing engine in OpenCL, allowing them to fully offload the process to the GPU. It’s this ray tracing engine we’re testing.

Compared to our other two GPU computing benchmarks, SmallLuxGPU follows the theoretical performance of our GPUs much more closely. As a result our Radeon GPUs with their difficult-to-utilize VLIW5 design end up topping the charts by a significant margin, while the fastest comparable NVIDIA GPU is still 10% slower than the 6850. Ultimately what we’re looking at is what amounts to the best-case scenarios for these GPUs, with this being as good an example as any that in the right circumstances AMD’s VLIW5 shader design can go toe-to-toe with NVIDIA’s compute-focused design and still win.
At the other end of the spectrum from GPU computing performance is GPU tessellation performance, used exclusively for graphical purposes. For the Radeon 6800 series, AMD enhanced their tessellation unit to offer better tessellation performance at lower tessellation factors. In order to analyze the performance of AMD’s enhanced tessellator, we’re using the Unigine Heaven benchmark and Microsoft’s DirectX 11 Detail Tessellation sample program to measure the tessellation performance of a few of our cards.
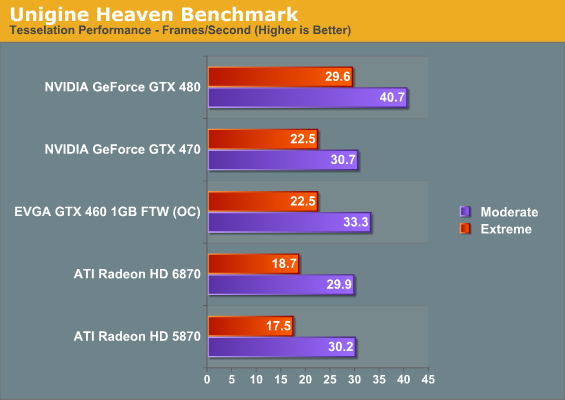
Since Heaven is a synthetic benchmark at the moment (the DX11 engine isn’t currently used in any games) we’re less concerned with performance relative to NVIDIA’s cards and more concerned with performance relative to the 5870. Compared to the 5870 the 6870 ends up being slightly slower when using moderate amounts of tessellation, while it pulls ahead when using extreme amounts of tessellation. Considering that the 6870 is around 7% slower in games than the 5870 this is actually quite an accomplishment for Barts, and one that we can easily trace back to AMD’s tessellator improvements.
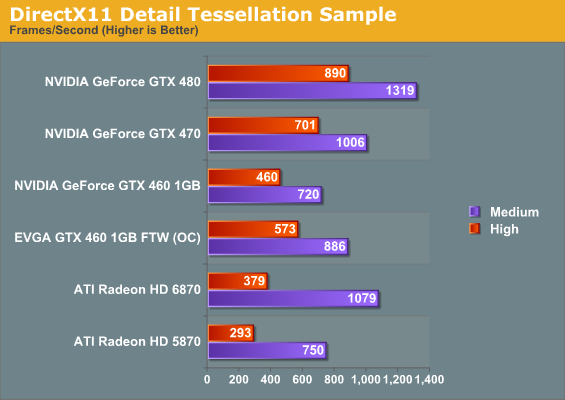
Our second tessellation test is Microsoft’s DirectX 11 Detail Tessellation sample program, which is a much more straightforward test of tessellation performance. Here we’re simply looking at the framerate of the program at different tessellation levels, specifically level 7 (the default level) and level 11 (the maximum level). Here AMD’s tessellation improvements become even more apparent, with the 6870 handily beating the 5870. In fact our results are very close to AMD’s own internal results – at level 7 the 6870 is 43% faster than the 5870, while at level 11 that improvement drops to 29% as the increased level leads to an increasingly large tessellation factor. However this also highlights the fact that AMD’s tessellation performance still collapses at high factors compared to NVIDIA’s GPUs, making it all the more important for AMD to encourage developers to use more reasonable tessellation factors.








197 Comments
View All Comments
Goty - Friday, October 22, 2010 - link
Other reviews show 6850s hitting 1GHz+ with software voltage modification, so I don't think that will be an issue.karlostomy - Monday, October 25, 2010 - link
The question then is, why did anandtech choose to include the EVGA card that NVIDIA no doubt hand picked and delivered?Including the OC 460 card is one thing, but at the very least some 'attempt' at oc'ing the 6850 would have retained a semblance of reviewer impartiality.
wyvernknight - Friday, October 22, 2010 - link
According to this article i just read it can do 6 way eyefinity.http://www.semiaccurate.com/2010/10/21/amds-6870-b...
The diagram is close to the bottom.
notty22 - Friday, October 22, 2010 - link
The reviewer addressed why the 460 o/c was included. Owners/gamers are reporting the ability to clock their 460's to the 810,820,850 mhz the clocks various "special" models come @ with stock voltage. I agree , its more of why did Nvidia do this ? Imho, it was to position the card without competing/obsoleting the gtx 465/470. Now that Nvidia has lowered the prices, and the good price point the new AMD cards launched with, this is a exciting time for the gamer.Now lets get some new, more powerful dx11 games !
Thanx for the COMPLETE review !
Kyanzes - Friday, October 22, 2010 - link
I could have sworn that AvP had been mentioned as a future standard test game on Anandtech. I could be wrong ofc.3DVagabond - Friday, October 22, 2010 - link
I'm really surprised you went along with using the EVGA (OC) card nVidia sent you. They sent you what is commonly referred to as "a ringer", and you went along. You should have used the stock 460 (both models) and a stock 470, IMO. Why let nVidia name the conditions? They are obviously going to do everything they can to tilt the playing field. Was there anything else they wanted that you did for them?AnandThenMan - Friday, October 22, 2010 - link
Well in the article, they basically admitted to "caving in" to Nvidia by including the overclocked card. Obviously Nvidia was very keen to have a specific card included, seems dubious."However with the 6800 launch NVIDIA is pushing the overclocked GTX 460 option far harder than we’ve seen them push overclocked cards in the past –we had an EVGA GTX 460 1GB FTW on our doorstep before we were even back from Los Angeles."
I mean stating, "a matter of editorial policy" then ignoring that policy outright seems pretty sketchy to me. Like you said, makes one question the results in general.
DominionSeraph - Friday, October 22, 2010 - link
If AMD's official segmentation strategy were to put a factory overclocked 6870 against the GTX 470, what would be the issue with AnandTech comparing the two? Granted, it doesn't mean much to enthusiasts who would just buy a stocker and overclock it to pocket the price differential, but I'd wager a card bought by your average idiot buying off the shelves of Best Buy isn't going to see anything other than the factory clocks.bji - Friday, October 22, 2010 - link
Actually the people overclocking their video cards and then dealing with overheating and loud-as-an-aircraft-engine fan noise are the idiots.Just thought that if you were going to go around saying disparaging things about people who have different values than you do, that you might appreciate some of the same.
spigzone - Friday, October 22, 2010 - link
Maybe if you had dropped testing the FTW 460 for the time being, saving it for your 'overview' test next week, you would have had enough time to release a fully fleshed out and organized review instead of letting Nvidia jerk you around, compromising your own 'editorial policy' on only using stock cards in the initial review and saving you the time and trouble of coming up with lame @$$ rationalizations.