Intel's Sandy Bridge Architecture Exposed
by Anand Lal Shimpi on September 14, 2010 4:10 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
The Front End
Sandy Bridge’s CPU architecture is evolutionary from a high level viewpoint but far more revolutionary in terms of the number of transistors that have been changed since Nehalem/Westmere.
In Core 2 Intel introduced a block of logic called the Loop Stream Detector (LSD). The LSD would detect when the CPU was executing a software loop turn off the branch predictor and fetch/decode engines and feed the execution units through micro-ops cached by the LSD. This approach saves power by shutting off the front end while the loop executes and improves performance by feeding the execution units out of the LSD.
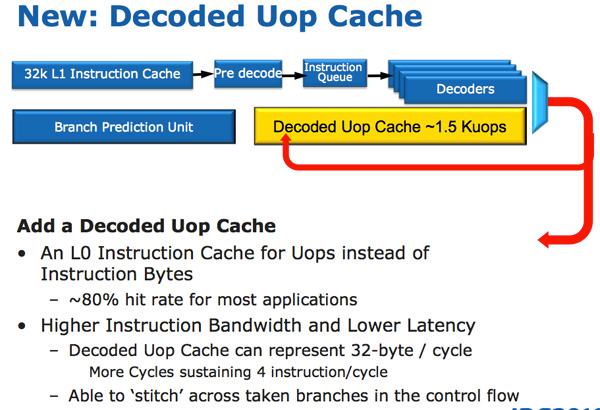
In Sandy Bridge, there’s now a micro-op cache that caches instructions as they’re decoded. There’s no sophisticated algorithm here, the cache simply grabs instructions as they’re decoded. When SB’s fetch hardware grabs a new instruction it first checks to see if the instruction is in the micro-op cache, if it is then the cache services the rest of the pipeline and the front end is powered down. The decode hardware is a very complex part of the x86 pipeline, turning it off saves a significant amount of power. While Sandy Bridge is a high end architecture, I feel that the micro-op cache would probably benefit Intel’s Atom lineup down the road as the burden of x86 decoding is definitely felt in these very low power architectures.
The cache is direct mapped and can store approximately 1.5K micro-ops, which is effectively the equivalent of a 6KB instruction cache. The micro-op cache is fully included in the L1 i-cache and enjoys approximately an 80% hit rate for most applications. You get slightly higher and more consistent bandwidth from the micro-op cache vs. the instruction cache. The actual L1 instruction and data caches haven’t changed, they’re still 32KB each (for total of 64KB L1).
All instructions that are fed out of the decoder can be cached by this engine and as I mentioned before, it’s a blind cache - all instructions are cached. Least recently used data is evicted as it runs out of space.
This may sound a lot like Pentium 4’s trace cache but with one major difference: it doesn’t cache traces. It really looks like an instruction cache that stores micro-ops instead of macro-ops (x86 instructions).
Along with the new micro-op cache, Intel also introduced a completely redesigned branch prediction unit. The new BPU is roughly the same footprint as its predecessor, but is much more accurate. The increase in accuracy is the result of three major innovations.
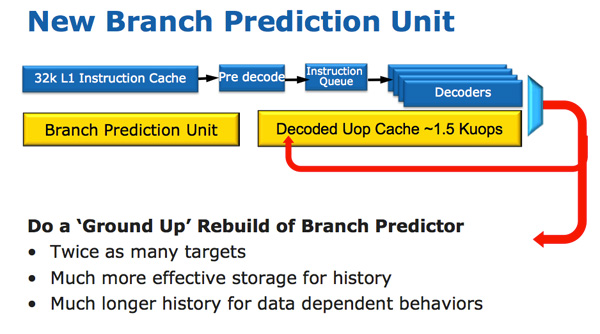
The standard branch predictor is a 2-bit predictor. Each branch is marked in a table as taken/not taken with an associated confidence (strong/weak). Intel found that nearly all of the branches predicted by this bimodal predictor have a strong confidence. In Sandy Bridge, the bimodal branch predictor uses a single confidence bit for multiple branches rather than using one confidence bit per branch. As a result, you have the same number of bits in your branch history table representing many more branches, which can lead to more accurate predictions in the future.
Branch targets also got an efficiency makeover. In previous architectures there was a single size for branch targets, however it turns out that most targets are relatively close. Rather than storing all branch targets in large structures capable of addressing far away targets, SNB now includes support for multiple branch target sizes. With smaller target sizes there’s less wasted space and now the CPU can keep track of more targets, improving prediction speed.
Finally we have the conventional method of increasing the accuracy of a branch predictor: using more history bits. Unfortunately this only works well for certain types of branches that require looking at long patterns of instructions, and not well for shorter more common branches (e.g. loops, if/else). Sandy Bridge’s BPU partitions branches into those that need a short vs. long history for accurate prediction.








62 Comments
View All Comments
yuhong - Tuesday, September 14, 2010 - link
There is no VEX.256 for 256-bit integer ops, but there is a VEX.128 prefix that zeros the upper part of YMM registers to reduce the delays..NaN42 - Tuesday, September 14, 2010 - link
Well, I found a summary of the prefixes. Interestingly there are some exception, like I guessed, e.g. a VEX.128 prefix does not exist for conversion of packed floating points<->packed integers and for CRC32c + POPCNT.CSMR - Tuesday, September 14, 2010 - link
Anand:The best info available on an exciting platform, good job.
I wonder if for the next article you could test DirectX / OpenGL compatibility? Intel advertises compliance for a lot of its products, but in reality the support is partial, and some applications that use DirectX / OpenGL entirely correctly are not supported by Intel graphics, including the current HD graphics.
I've found this with fastpictureviewer (DirectX, I think 9) and Photoshop CS5 (OpenGL 2)
This is quite shocking. Given that Intel is doing this currently, it would be great if reviewers could prod it into action, but unfortunately they tend to place speed first, correctness second or nowhere.
marass31 - Thursday, September 16, 2010 - link
Hi CSMR,Could you please write more details about problems with DX and OGL on Intel HD graphics( including gfx driver version, system config ...). You mentioned about two applications: Fastpictureviewer and PSCS5, so could you please write some steps to reproduce to each of them - THX a lot.
ssj4Gogeta - Tuesday, September 14, 2010 - link
What's the point of extreme editions if we're going to have affordable K SKUs?Or will socket 2011 not have any K SKUs? I'm guessing they'll leave the BCLCK unlocked on the 2011, and only have normal and extreme processors (no K processors). Or maybe extreme editions will just have more cores like 980X?
DanNeely - Tuesday, September 14, 2010 - link
The extreme editions have always been for people who buy retail or who're playing with LN2 and need the most insanely binned part available. They've never been a mainstream OCer part.MonkeyPaw - Tuesday, September 14, 2010 - link
I have a bad feeling about the "k" chips and the future of overclocking. Sure, intel gave us turbo mode, but that almost seems like appeasement before the last shoe drops. First, limited turbo with good overclockng, then better turbo and less overclocking, and now it's sounding like slightly better turbo and even less overclocking. It looks like we are moving to intel-controlled overclocking. There's virtually no value left for the enthusiast--a user that is already just a small part of the market. Intel just decided what the enthusiast needs, but I don't think they get what those users actually want.I just don't buy that these limits are to prevent fraud. Mom and Pop stores are virtually all gone now, and I'd hate to think what Intel would do to a Dell or HP if they got caught overclocking desktops.
I guess this leaves another door open for AMD. Sad, cause SnB looks like a great design.
This Guy - Wednesday, September 15, 2010 - link
Hopefully Intel will allow the 'energy budget' to be increased when an extreme edition processer detects less thermal resistance (i.e. a bloody big heat sink). This would allow an EE CPU to either run with a higher multiplier or run at it's turbo frequency longer. (I'ld like this feature on all CPU's)This would make EE CPU's interesting if K CPU's catch up in terms of cores.
Shadowmaster625 - Tuesday, September 14, 2010 - link
What are the prospects for using Intel's transcoder to convert DVDs to 700MB avi files? Either DivX, Xvid, or H.264? Or anything else better than MPEG-2?Dfere - Tuesday, September 14, 2010 - link
Since this seems to be, overall, a refinement, and not so much an improvement with new capabilities, and Anand's comments about the scalability of GPU related enhancements, that Intel is taking a two step approach towards CPU releases, in addition to its fab strategies? E.G, we see a new CPU, then it gets shrunk, then it gets improved (like this), then it gets bells and whistles (like a GPU etc), then we start over again with a really new architecture.....