Intel's Sandy Bridge Architecture Exposed
by Anand Lal Shimpi on September 14, 2010 4:10 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
The Front End
Sandy Bridge’s CPU architecture is evolutionary from a high level viewpoint but far more revolutionary in terms of the number of transistors that have been changed since Nehalem/Westmere.
In Core 2 Intel introduced a block of logic called the Loop Stream Detector (LSD). The LSD would detect when the CPU was executing a software loop turn off the branch predictor and fetch/decode engines and feed the execution units through micro-ops cached by the LSD. This approach saves power by shutting off the front end while the loop executes and improves performance by feeding the execution units out of the LSD.
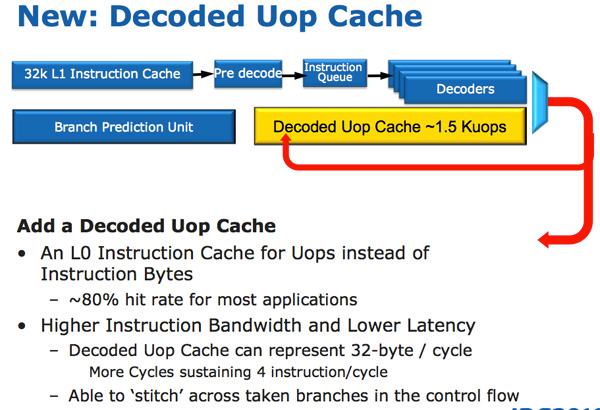
In Sandy Bridge, there’s now a micro-op cache that caches instructions as they’re decoded. There’s no sophisticated algorithm here, the cache simply grabs instructions as they’re decoded. When SB’s fetch hardware grabs a new instruction it first checks to see if the instruction is in the micro-op cache, if it is then the cache services the rest of the pipeline and the front end is powered down. The decode hardware is a very complex part of the x86 pipeline, turning it off saves a significant amount of power. While Sandy Bridge is a high end architecture, I feel that the micro-op cache would probably benefit Intel’s Atom lineup down the road as the burden of x86 decoding is definitely felt in these very low power architectures.
The cache is direct mapped and can store approximately 1.5K micro-ops, which is effectively the equivalent of a 6KB instruction cache. The micro-op cache is fully included in the L1 i-cache and enjoys approximately an 80% hit rate for most applications. You get slightly higher and more consistent bandwidth from the micro-op cache vs. the instruction cache. The actual L1 instruction and data caches haven’t changed, they’re still 32KB each (for total of 64KB L1).
All instructions that are fed out of the decoder can be cached by this engine and as I mentioned before, it’s a blind cache - all instructions are cached. Least recently used data is evicted as it runs out of space.
This may sound a lot like Pentium 4’s trace cache but with one major difference: it doesn’t cache traces. It really looks like an instruction cache that stores micro-ops instead of macro-ops (x86 instructions).
Along with the new micro-op cache, Intel also introduced a completely redesigned branch prediction unit. The new BPU is roughly the same footprint as its predecessor, but is much more accurate. The increase in accuracy is the result of three major innovations.
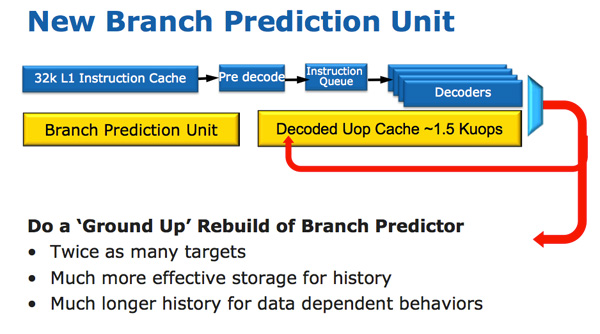
The standard branch predictor is a 2-bit predictor. Each branch is marked in a table as taken/not taken with an associated confidence (strong/weak). Intel found that nearly all of the branches predicted by this bimodal predictor have a strong confidence. In Sandy Bridge, the bimodal branch predictor uses a single confidence bit for multiple branches rather than using one confidence bit per branch. As a result, you have the same number of bits in your branch history table representing many more branches, which can lead to more accurate predictions in the future.
Branch targets also got an efficiency makeover. In previous architectures there was a single size for branch targets, however it turns out that most targets are relatively close. Rather than storing all branch targets in large structures capable of addressing far away targets, SNB now includes support for multiple branch target sizes. With smaller target sizes there’s less wasted space and now the CPU can keep track of more targets, improving prediction speed.
Finally we have the conventional method of increasing the accuracy of a branch predictor: using more history bits. Unfortunately this only works well for certain types of branches that require looking at long patterns of instructions, and not well for shorter more common branches (e.g. loops, if/else). Sandy Bridge’s BPU partitions branches into those that need a short vs. long history for accurate prediction.








62 Comments
View All Comments
iwodo - Tuesday, September 14, 2010 - link
Many questions still not answered, may be Anand could found out for us.1. Were the GPU performance we saw from 6 EU or 12 EU?
2. Where is FMA ( Fused Multiply Add ) ? Will we see it in Ivy Bridge?
3. Can All software developers access the Decoding Engine? We could see many codec being optimized for playback on Intel Hardware Decoder, whether it is fully supported codec or partially supported codec.
4. Hardware Encoder? It is Full Hardware encoder? Free to use for Software Dev?
5. OpenCL not possible?
6. How many % die size is given to Graphics?
7. Gfx Drivers, will Intel commit more resources on drivers update? Or Will they open sources it?
Apart from Sandy Bridge, Looking forward for reports on USB 3.0 situations, LightPeak, Gen 3 SSD.
trivik12 - Tuesday, September 14, 2010 - link
1) I believe it was 12EU part.2) FMA will be introduced with Haswell(next tock). So we have to wait until early 2013 for that.
Foo999 - Tuesday, September 14, 2010 - link
> 2. Where is FMA ( Fused Multiply Add ) ? Will we see it in Ivy Bridge?You can check out the full current (and Ivy Bridge) AVX instructions in the AVX reference manual available from software.intel.com/en-us/avx/
spart - Tuesday, September 14, 2010 - link
1 , 6UE The 12 is only for laptops and high rangesgvaley - Tuesday, September 14, 2010 - link
So, was it playable, I mean Starcraft II?therealnickdanger - Tuesday, September 14, 2010 - link
Yeah, the caption said "310M vs Sandy Bridge" so I assume you could see the settings and frames per second. Details, man, details!!:)
Anand Lal Shimpi - Tuesday, September 14, 2010 - link
Yes, it was playable at medium quality settings. They only had the single player campaign running however.Take care,
Anand
Carleh - Tuesday, September 14, 2010 - link
With BCLK locked, where does that leave the motherboard manufacturers?I mean, what are they left to offer to enthusiasts, if the BCLK is locked? How are they going to differentiate an enthusiast-class motherboard from a mainstream one?
ssj4Gogeta - Tuesday, September 14, 2010 - link
Will they be locking the socket 2011 parts as well?Zoomer - Sunday, September 19, 2010 - link
Sell more bullbozer boards. I was all set to be ready to get a nice Sandy Bridge and overclock it to hell, but now I think I'll get a bulldozer instead.Sure there's the K, but it costs more. That kinda defeats the point, unless the aim is to get a high clk for epeen.