NVIDIA’s GeForce GTX 480 and GTX 470: 6 Months Late, Was It Worth the Wait?
by Ryan Smith on March 26, 2010 7:00 PM EST- Posted in
- GPUs
The GF100 Recap
NVIDIA first unveiled its GF100 (then called Fermi) architecture last September. If you've read our Fermi and GF100 architecture articles, you can skip this part. Otherwise, here's a quick refresher on how this clock ticks.
First, let’s refresh the basics. NVIDIA’s GeForce GTX 480 and 470 are based on the GF100 chip, the gaming version of what was originally introduced last September as Fermi. GF100 goes into GeForces and Fermi goes into Tesla cards. But fundamentally the two chips are the same.
At a high level, GF100 just looks like a bigger GT200, however a lot has changed. It starts at the front end. Prior to GF100 NVIDIA had a large unified front end that handled all thread scheduling for the chip, setup, rasterization and z-culling. Here’s the diagram we made for GT200 showing that:
NVIDIA's GT200
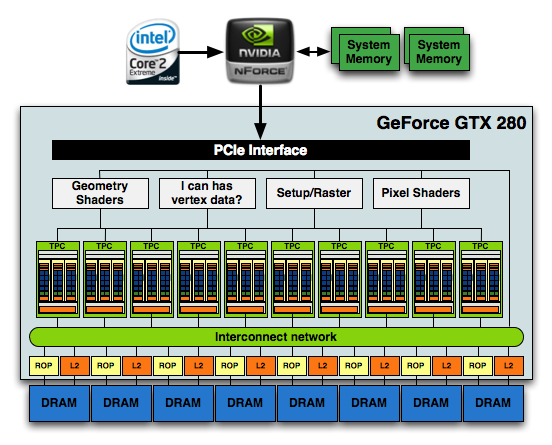
The grey boxes up top were shared by all of the compute clusters in the chip below. In GF100, the majority of that unified front end is chopped up and moved further down the pipeline. With the exception of the thread scheduling engine, everything else decreases in size, increases in quantity and moves down closer to the execution hardware. It makes sense. The larger these chips get, the harder it is to have big unified blocks feeding everything.
In the old days NVIDIA took a bunch of cores, gave them a cache, some shared memory and a couple of special function units and called the whole construct a Streaming Multiprocessor (SM). The GT200 took three of these SMs, added texture units and an L1 texture cache (as well as some scheduling hardware) and called it a Texture/Processor Cluster. The old GeForce GTX 280 had 10 of these TPCs and that’s what made up the execution engine of the GPU.
NVIDIA's GF100
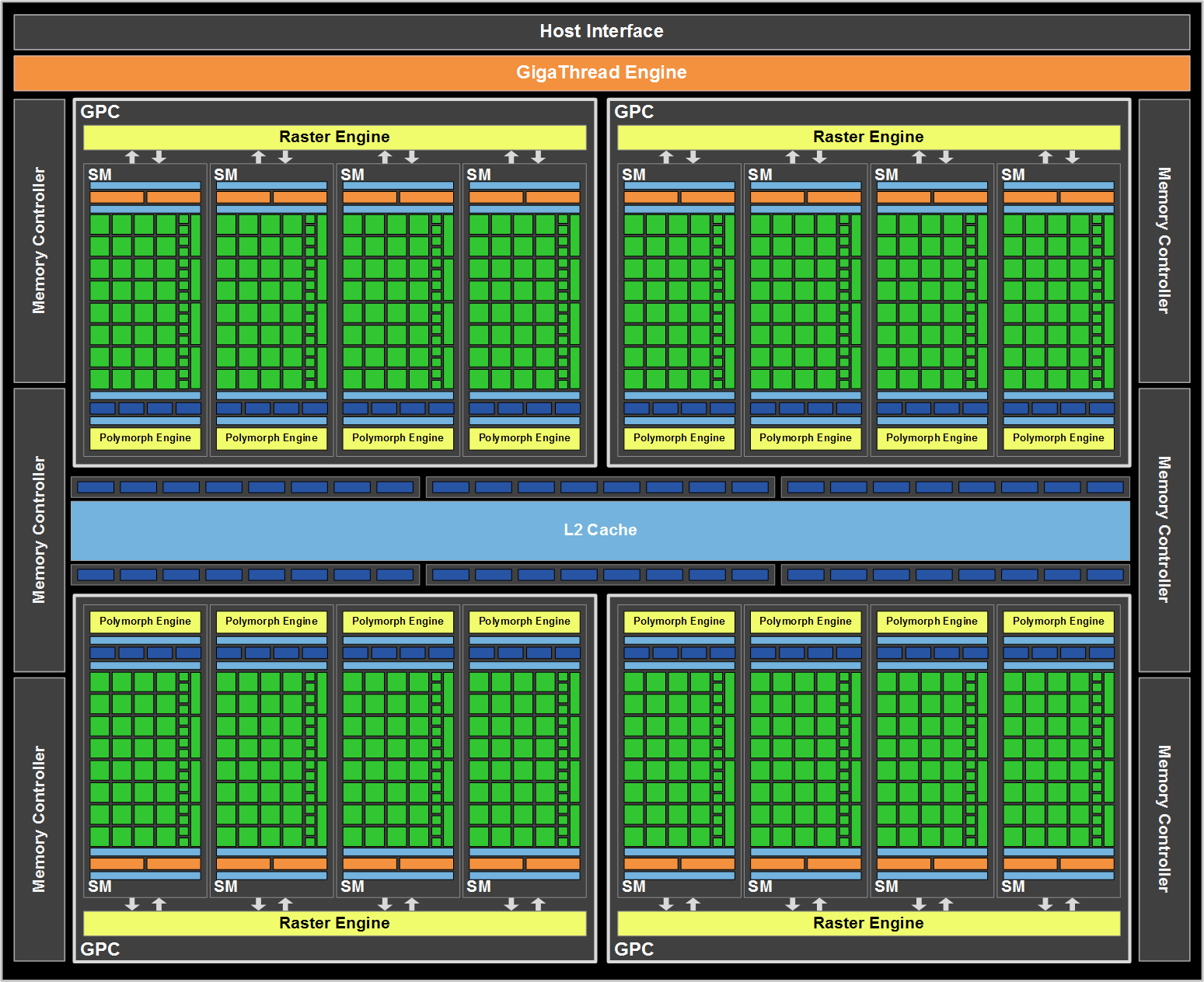
Click to Enlarge
With GF100, the TPC is gone. It’s now a Graphics Processing Cluster (GPC) and is made up of much larger SMs. Each SM now has 32 cores and there are four SMs per GPC. Each GPC gets its own raster engine, instead of the entire chip sharing a larger front end. There are four GPCs on a GF100 (however no GF100 shipping today has all SMs enabled in order to improve yield).

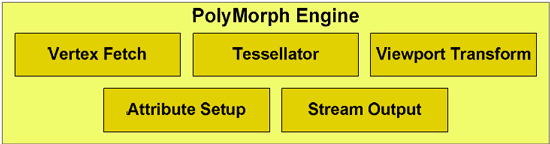
Each SM also has what NVIDIA is calling a PolyMorph engine. This engine is responsible for all geometry execution and hardware tessellation, something NVIDIA expects to be well used in DX11 and future games. NV30 (GeForce FX 5800) and GT200 (GeForce GTX 280), the geometry performance of NVIDIA’s hardware only increases roughly 3x in performance. Meanwhile the shader performance of their cards increased by over 150x. Compared just to GT200, GF100 has 8x the geometry performance of GT200, and NVIDIA tells us this is something they have measured in their labs. This is where NVIDIA hopes to have the advantage over AMD, assuming game developers do scale up geometry and tessellation use as much as NVIDIA is counting on.
NVIDIA also clocks the chip much differently than before. In the GT200 days we had a core clock, a shader clock and a memory clock. The core clock is almost completely out of the picture now. Only the ROPs and L2 cache operate on a separate clock domain. Everything else runs at a derivative of the shader clock. The execution hardware runs at the full shader clock speed, while the texture units, PolyMorph and Raster engines all run at 1/2 shader clock speed.
Cores and Memory
While we’re looking at GF100 today through gaming colored glasses, NVIDIA is also trying to build an army of GPU compute cards. In serving that master, the GF100’s architecture also differs tremendously from its predecessors.
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect. Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5).
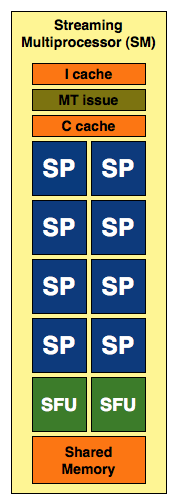
GT200 SM
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in GF100 it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled. The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.

GF100 SM
NVIDIA’s GT200 had a 16KB shared memory in each SM. This didn’t function as a cache, it was software managed memory. GF100 increases the size to 64KB but it can operate as a real L1 cache now. In order to maintain compatibility with CUDA applications written for G80/GT200 the 64KB can be configured as 16/48 or 48/16 shared memory/L1 cache. GT200 did have a 12KB L1 texture cache but that was mostly useless for CUDA applications. That cache still remains intact for graphics operations. All four GPCs share a large 768KB L2 cache.

Each SM has four texture units, each capable of 1 texture address and 4 texture sample ops. We have more texture sampling units but fewer texture addressing units in GF100 vs. GT200. All texture hardware runs at 1/2 shader clock and not core clock.
| NVIDIA Architecture Comparison | G80 | G92 | GT200 | GF100 | GF100 Full* |
| Streaming Processors per TPC/GPC | 16 | 16 | 24 | 128 | 128 |
| Texture Address Units per TPC/GPC | 4 | 8 | 8 | 16 | 16 |
| Texture Filtering Units per TPC/GPC | 8 | 8 | 8 | 64 | 64 |
| Total SPs | 128 | 128 | 240 | 480 | 512 |
| Total Texture Address Units | 32 | 64 | 80 | 60 | 64 |
| Total Texture Filtering Units | 64 | 64 | 80 | 240 | 256 |
Last but not least, this brings us to the ROPs. The ROPs have been reorganized, there are now 48 of them in 6 parttions of 8, and a 64bit memory channel serving each partition. The ROPs now share the L2 cache with the rest of GF100, while under GT200 they had their own L2 cache. Each ROP can do 1 regular 32bit pixel per clock, 1 FP16 pixel over 2 clocks, or 1 FP32 pixel over 4 clocks, giving the GF100 the ability to retire 48 regular pixels per clock. The ROPs are clocked together with the L2 cache.
Threads and Scheduling
While NVIDIA’s G80 didn’t start out as a compute chip, GF100/Fermi were clearly built with general purpose compute in mind from the start. Previous architectures required that all SMs in the chip worked on the same kernel (function/program/loop) at the same time. If the kernel wasn’t wide enough to occupy all execution hardware, that hardware went idle, and efficiency dropped as a result. Remember these chips are only powerful when they’re operating near 100% utilization.
In this generation the scheduler can execute threads from multiple kernels in parallel, which allowed NVIDIA to scale the number of cores in the chip without decreasing efficiency.
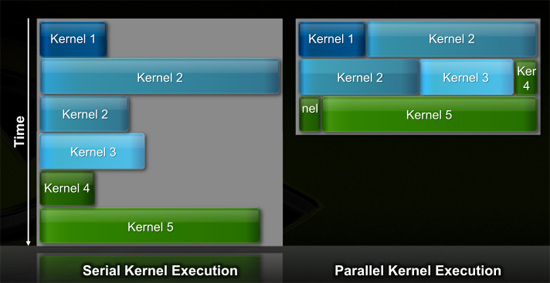
GT200 (left) vs. GF100 (right)
With a more compute leaning focus, GF100 also improves switch time between GPU and CUDA mode by a factor of 10x. It’s now fast enough to switch back and forth between modes multiple times within a single frame, which should allow for more elaborate GPU accelerated physics.
NVIDIA’s GT200 was a thread monster. The chip supported over 30,000 threads in flight. With GF100, NVIDIA scaled that number down to roughly 24K as it found that the chips weren’t thread bound but rather memory bound. In order to accommodate the larger shared memory per SM, max thread count went down.
| GF100 | GT200 | G80 | |
| Max Threads in Flight | 24576 | 30720 | 12288 |
NVIDIA groups 32 threads into a unit called a warp (taken from the looming term warp, referring to a group of parallel threads). In GT200 and G80, half of a warp was issued to an SM every clock cycle. In other words, it takes two clocks to issue a full 32 threads to a single SM.
In previous architectures, the SM dispatch logic was closely coupled to the execution hardware. If you sent threads to the SFU, the entire SM couldn't issue new instructions until those instructions were done executing. If the only execution units in use were in your SFUs, the vast majority of your SM in GT200/G80 went unused. That's terrible for efficiency.
Fermi fixes this. There are two independent dispatch units at the front end of each SM in Fermi. These units are completely decoupled from the rest of the SM. Each dispatch unit can select and issue half of a warp every clock cycle. The threads can be from different warps in order to optimize the chance of finding independent operations.
There's a full crossbar between the dispatch units and the execution hardware in the SM. Each unit can dispatch threads to any group of units within the SM (with some limitations).
The inflexibility of NVIDIA's threading architecture is that every thread in the warp must be executing the same instruction at the same time. If they are, then you get full utilization of your resources. If they aren't, then some units go idle.
A single SM can execute:
| GF100 | FP32 | FP64 | INT | SFU | LD/ST |
| Ops per clock | 32 | 16 | 32 | 4 | 16 |
If you're executing FP64 instructions the entire SM can only run at 16 ops per clock. You can't dual issue FP64 and SFU operations.
The good news is that the SFU doesn't tie up the entire SM anymore. One dispatch unit can send 16 threads to the array of cores, while another can send 16 threads to the SFU. After two clocks, the dispatchers are free to send another pair of half-warps out again. As I mentioned before, in GT200/G80 the entire SM was tied up for a full 8 cycles after an SFU issue.
The flexibility is nice, or rather, the inflexibility of GT200/G80 was horrible for efficiency and Fermi fixes that.








196 Comments
View All Comments
WiNandLeGeNd - Saturday, March 27, 2010 - link
I think this was a great review, as mentioned previously, very objective. I think though that I may get a 480, because when I buy a card I keep it for 3 to 4 years before I get a new one, aka every other gen. And seeing that tessellation is really the gift horse of DX11 and how much more tessellation power is in the 480's, I think it could very much pay off in the future. If not then I spent an extra $85 for a tad extra performance as I just pre-ordered one for 485 and the 5870's are at $400 still.My only concern is heat and power, but most of the cards have a life time warranty. Hopefully my OCZ GamerXtreme 850W can handle it at max loads. The two 12v rails for the two 6 pin PCI-X connectors are 20 A each, I saw 479w max consumption, however that was furmark, at 12v that's 39.5 amps, so it would be extremely close if there is ever a game to utilize that much power. Although If I recall ATI specifically stated a while back to not use that as it pushes loads that are not possible to see in an actual game, I think they had an issue with the 4000 series burning out power regulators, correct me if I'm wrong.
Alastayr - Saturday, March 27, 2010 - link
I'm with sunburn on this one. Your reasoning doesn't make much sense. You must've not followed the GPU market for the last few years becausefirst) "every other gen" would mean a 2 year cycle
second) Nothing's really gonna pay off in the future, as the future will bring faster cards for a fraction of the price. You'd only enjoy those questionable benefits until Q4, when AMD releases Northern Islands and nVidia pops out GF100b or whatever they'll call it.
third) Tessellation won't improve further that fast. If at all, developers will focus on the lowest common denominator, which would be Cypress. Fermi's extra horse power will most likely stay unused.
fourth) Just look at your power bill. The 25W difference with a "typical" Idle scheme (8h/day; 350d/y) comes to 70kWh which where I live translates to around $20 per year. That's Idle *only*. You're spending way more than just $85 extra on that card.
fifth) The noise will kill you. This isn't a card than just speeds up for no reason. You can't just magically turn down the fan from 60% to 25% and still enjoy Temps of <90°C like on some GTX 260 boards. Turn up your current fan to 100% for a single day. Try living through that. That's probably what you're buying.
In the end everyone has to decide this for himself. But for someone to propose keeping a GTX 480 in his PC for a whopping 3-4 years... I don't know man. I'd rather lose a finger or two. ;)
tl;dr I know, I know. But really people. Those cards aren't hugely competetive, priced too high and nV's drivers suck as much as ATi's (allegedly) do nowadays. Whis is to say neither do.
I could honestly bite me right now. I had a great deal for a 5850 in Nov. and I waited for nV to make their move. Now the same card will cost me $50 more, and I've only wasted time by waiting for the competetive GTX 470 that never was. Argh.
Sunburn74 - Saturday, March 27, 2010 - link
Thats kind of bad logic imo. I'm not fanboy on either side, but it's clear to me that Nvidia targeted the performance of their cards to fit in exactly between the 5970, the 5870, and 5850. Its much harder to release a card not knowing what the other guy truly has as opposed to releasing a card knowing exactly what sort of performance levels you have to hit.Two, realistically, think of the noise. I mean ifyou've ever heard a gtx 260 at 100 percent fan speed, thats the sort of fan noises you're going to be experiencing on a regular basis. Its not a mild difference.
And three, realistically for the premium you're paying for the extra performance (which is not useful right now as there are no games to take advantage of it) as well as for the noise, heat and power, you could simply buy the cheaper 5870, save that 85-150 dollars extra, and sell off the 5870 when the time is right.
I just don't see why anyone would buy this card unless they were specifically taking advantage of some of the compute functions. As a consumer card it is a failure. Power and heat be damned, the noise the noise! Take your current card up to 100 percent fan speed, and listen to it for a few mins, and thats what you should about expect from these gpus.
andyo - Saturday, March 27, 2010 - link
I too am getting the warning message with Firefox 3.6.2. Posting this on IE. Here's the message:http://photos.smugmug.com/photos/820690277_fuLv6-O...">http://photos.smugmug.com/photos/820690277_fuLv6-O...
JarredWalton - Saturday, March 27, 2010 - link
We're working on it. Of course, the "Internet Police" have now flagged our site as malicious because of one bad ad that one of the advertisers put up, and it will probably take a week or more to get them to rescind the "Malware Site" status. Ugh....jeffrey - Saturday, March 27, 2010 - link
Give the advertiser that put up the bad ad hell!LedHed - Saturday, March 27, 2010 - link
The people who are going to buy the GTX 480/470 are enthusiast who most likely bought the GTX 295 or had 200 Series SLI. So not including the 295 in every bench is kind of odd. We need to see how the top end of the last gen does against the new gen top end.Ryan Smith - Saturday, March 27, 2010 - link
What chart is the 295 not in? It should be in every game test.kc77 - Saturday, March 27, 2010 - link
Well the 295 beats the 470 in most benches so there's no need to really include it in all benches. Personally I think the 480 is the better deal. Although I am not buying those cards until a respin/refresh, those temps and power requirements are just ridiculous.bigboxes - Saturday, March 27, 2010 - link
I know you "upgraded" your test PSU to the Antec 1200W PSU, but did you go back and try any of these tests/setups with your previous 850W PSU to see if could handle the power requirements. It seemed that only your 480 SLI setup drew 851W in total system in the Furmark load test. Other than that scenario it looks like your old PSU should handle the power requirements just fine. Any comments?