Dynamic Power Management: A Quantitative Approach
by Johan De Gelas on January 18, 2010 2:00 AM EST- Posted in
- IT Computing
How Does Power Management Work?
The BIOS settings, the power manager of the Operating System, the hardware circuits on the CPU, monitoring hardware, sensor banks... when I first started reading about power management, it quickly became very chaotic. Let's make some sense out of it.
It all starts with ACPI, the Advanced Configuration and Power Interface. In 1996, the three most influential companies in the PC world (Intel, HP, and Microsoft) together with Toshiba and Phoenix standardized power management by presenting the ACPI Specification. ACPI defines which registers a piece of hardware should have available, and what information the BIOS/firmware should offer: these are the red pieces in the graph below.
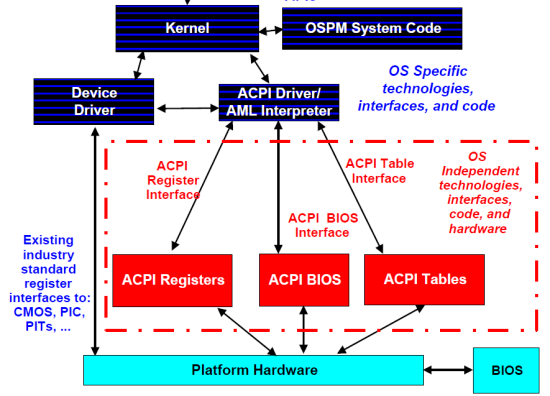
The most important information can be found in the ACPI tables, which describe the capabilities of the different devices of the platform. Once the kernel has read and interpreted them, the role of the BIOS is over. This is in sharp contrast with the power management (APM) systems that we used throughout the 80s and 90s, where for example CPU power management was completely controlled by the BIOS. The basic idea behind ACPI based power management is that unused/less used devices should be put into lower power states. You can even place the entire system in a low-power state (sleeping state) when possible. The ACPI system states are probably the best known ACPI states:
- S0 Working
- S1 processor idle and in low power state but still getting power, RAM powered
- S2 Processor in a deep sleep, RAM powered, most devices in lower power
- S3 CPU in a deep sleep, RAM still getting power, devices in the lowest power states, also known as "Standby"
- S4 RAM no longer powered, disk contains an image of the RAM contents, also known as "Hibernate"
- S5 is the soft power off
We translated the ACPI system states to their most popular implementations; the standards are actually a bit vague... or flexible if you like. You can find more details in the latest ACPI specification (revision 4.0, June 16, 2009). Windows 2008 R2, the operating system used in this article, uses the older ACPI 3.0 standard. ACPI 3.0 made it possible for different CPUs to enter a different power state.
The boss of the ACPI based power management is the power management component of the kernel. The kernel power manager handles the devices' power policy, calculates and commands the required processor power state transitions, and so on. Of course, a kernel component does not have to know every specific detail of each different device. Focusing on the CPUs, the power manager will send for example the right P-state towards a specific processor driver: in the case of Windows 2008 R2, this is either intelppm.sys or amdppm.sys. The processor driver will direct the hardware to enter the P-state requested by the kernel. This mostly happens by writing to machine specific registers, the famous MSRs. So it's clear that the CPU driver contains architecture specific code.
Processor states
There are two processor states: P-states and C-states. P-states are described as performance states; each P-state corresponds with a certain clock speed and voltage. P-states could also be called processing states: contrary to C-states, a core in a P-state is actively processing instructions.
With the exception of C0, C-states are sleep/idle states: there is no processing whatsoever. We will not go into the details as Hardware Secrets has written a very comprehensive article on C-states. We will give you a quick overview of the ACPI standard C-states, and then immediately look at the actual implementation of those C-states in modern CPUs. The ACPI standard only defines four CPU power states from C0 to C3:
- C0 is the state where the P-state transitions happen: the CPU is processing.
- C1 halts the CPU. There is no processing, but the CPU's own hardware management determines whether there will be any significant power savings. All ACPI compliant CPUs must have a C1 state.
- C2 is optional, also known as "stop clock". While most CPUs stop "a few" clock signals in C1, most clocks are stopped in C2.
- C3 is also known as "sleep", or completely stop all clocks in the CPU.
The actual result of each ACPI C-state is not defined. It depends on the power management hardware that is available on the platform and the CPU. For example, all Intel Xeons of the past years support an Enhanced C1E state, which is entered automatically if the CPU stays in C1 for a while. Modern CPUs will not only stop the clock in C3, but also move to "deeper C4/C5/C6" sleeps and drop the voltage of the CPU. The C1E, C4, C5, and C6 states are only known to the hardware; the operating system sees them as ACPI C2 or C3. We will discuss this in more detail further on in this article. Before we go into more detail on how the CPUs actually handle these C- and P-states, let's see what we assembled in our labs for testing purposes.








35 Comments
View All Comments
JohanAnandtech - Tuesday, January 19, 2010 - link
Well, Oracle has a few downsides when it comes to this kind of testing. It is not very popular in the smaller and medium business AFAIK (our main target), and we still haven't worked out why it performs much worse on Linux than on Windows. So chosing Oracle is a sure way to make the projecttime explode...IMHO.ChristopherRice - Thursday, January 21, 2010 - link
Works worse on Linux then windows? You have a setup issue likely with the kernel parameters or within oracle itself. I actually don't know of any enterprise location that uses oracle on windows anymore. "Generally all Rhel4/Rhel5/Sun".TeXWiller - Monday, January 18, 2010 - link
The 34xx series supports four quad rank modules, giving today a maximum supported amount of 32GB per CPU (and board). The 24GB limit is that of the three channel controller with unbuffered memory modules.pablo906 - Monday, January 18, 2010 - link
I love Johan's articles. I think this has some implications in how virtualization solutions may be the most cost effective. When you're running at 75% capacity on every server I think the AMD solution could have possibly become more attractive. I think I'm going to have to do some independent testin in my datacenter with this.I'd like to mention that focusing on VMWare is a disservice to Vt technology as a whole. It would be like not having benchmarked the K6-3+ just because P2's and Celerons were the mainstream and SS7 boards weren't quite up to par. There are situations, primarily virtualizing Linux, where Citrix XenServer is a better solution. Also many people who are buying Server '08 licenses are getting Hyper-V licenses bundled in for "free."
I've known several IT Directors in very large Health Care organization who are deploying a mixed Hyper-V XenServer environment because of the "integration" between the two. Many of the people I've talked to at events around the country are using this model for at least part of the Virtualization deployments. I believe it would be important to publish to the industry what kind of performance you can expect from deployments.
You can do some really interesting HomeBrew SAN deployments with OpenFiler or OpeniSCSI that can compete with the performance of EMC, Clarion, NetApp, LeftHand, etc. NFS deployments I've found can bring you better performance and manageability. I would love to see some articles about the strengths and weaknesses of the storage subsystem used and how it affects each type of deployment. I would absolutely be willing to devote some datacenter time and experience with helping put something like this together.
I think this article really lends itself well into tieing with the Virtualization talks and I would love to see more comments on what you think this means to someone with a small, medium, and large datacenter.
maveric7911 - Tuesday, January 19, 2010 - link
I'd personally prefer to see kvm over xenserver. Even redhat is ditching xen for kvm. In the environments I work in, xen is actually being decommissioned for VMware.JohanAnandtech - Tuesday, January 19, 2010 - link
I can see the theoretical reasons why some people are excited about KVM, but I still don't see the practical ones. Who is using this in production? Getting Xen, VMware or Hyper-V do their job is pretty easy, KVM does not seem to be even close to being beta. It is hard to get working, and it nowhere near to Xen when it comes to reliabilty. Admitted, those are our first impressions, but we are no virtualization rookies.Why do you prefer KVM?
VJ - Wednesday, January 20, 2010 - link
"It is hard to get working, and it nowhere near to Xen when it comes to reliabilty. "I found Xen (separate kernel boot at the time) more difficult to work with than KVM (kernel module) so I'm thinking that the particular (host) platform you're using (windows?) may be geared towards one platform.
If you had to set it up yourself then that may explain reliability issues you've had?
On Fedora linux, it shouldn't be more difficult than Xen.
Toadster - Monday, January 18, 2010 - link
One of the new technologies released with Xeon 5500 (Nehalem) is Intel Intelligent Power Node Manager which controls P/T states within the server CPU. This is a good article on existing P/C states, but will you guys be doing a review of newer control technologies as well?http://communities.intel.com/community/openportit/...">http://communities.intel.com/community/...r-intel-...
JohanAnandtech - Tuesday, January 19, 2010 - link
I don't think it is "newer". Going to C6 for idle cores is less than a year old remember :-).It seems to be a sort of manager which monitors the electrical input (PDU based?) and then lowers the p-states to keep the power at certain level. Did I miss something? (quickly glanced)
I think personally that HP is more onto something by capping the power inside their server management software. But I still have to evaluate both. We will look into that.
n0nsense - Monday, January 18, 2010 - link
May be i missed something in the article, but from what I see at home C2Q (and C2D) can manage frequencies per core.i'm not sure it is possible under Windows, but in Linux it just works this way. You can actually see each core at its own frequency.
Moreover, you can select for each core which frequency it should run.