AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
More GDDR5 Technologies: Memory Error Detection & Temperature Compensation
As we previously mentioned, for Cypress AMD’s memory controllers have implemented a greater part of the GDDR5 specification. Beyond gaining the ability to use GDDR5’s power saving abilities, AMD has also been working on implementing features to allow their cards to reach higher memory clock speeds. Chief among these is support for GDDR5’s error detection capabilities.
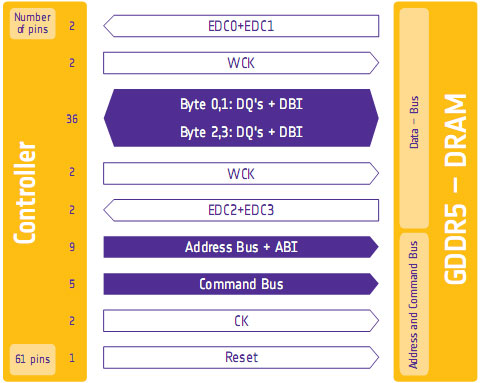
One of the biggest problems in using a high-speed memory device like GDDR5 is that it requires a bus that’s both fast and fairly wide - properties that generally run counter to each other in designing a device bus. A single GDDR5 memory chip on the 5870 needs to connect to a bus that’s 32 bits wide and runs at base speed of 1.2GHz, which requires a bus that can meeting exceedingly precise tolerances. Adding to the challenge is that for a card like the 5870 with a 256-bit total memory bus, eight of these buses will be required, leading to more noise from adjoining buses and less room to work in.
Because of the difficulty in building such a bus, the memory bus has become the weak point for video cards using GDDR5. The GPU’s memory controller can do more and the memory chips themselves can do more, but the bus can’t keep up.
To combat this, GDDR5 memory controllers can perform basic error detection on both reads and writes by implementing a CRC-8 hash function. With this feature enabled, for each 64-bit data burst an 8-bit cyclic redundancy check hash (CRC-8) is transmitted via a set of four dedicated EDC pins. This CRC is then used to check the contents of the data burst, to determine whether any errors were introduced into the data burst during transmission.
The specific CRC function used in GDDR5 can detect 1-bit and 2-bit errors with 100% accuracy, with that accuracy falling with additional erroneous bits. This is due to the fact that the CRC function used can generate collisions, which means that the CRC of an erroneous data burst could match the proper CRC in an unlikely situation. But as the odds decrease for additional errors, the vast majority of errors should be limited to 1-bit and 2-bit errors.
Should an error be found, the GDDR5 controller will request a retransmission of the faulty data burst, and it will keep doing this until the data burst finally goes through correctly. A retransmission request is also used to re-train the GDDR5 link (once again taking advantage of fast link re-training) to correct any potential link problems brought about by changing environmental conditions. Note that this does not involve changing the clock speed of the GDDR5 (i.e. it does not step down in speed); rather it’s merely reinitializing the link. If the errors are due the bus being outright unable to perfectly handle the requested clock speed, errors will continue to happen and be caught. Keep this in mind as it will be important when we get to overclocking.
Finally, we should also note that this error detection scheme is only for detecting bus errors. Errors in the GDDR5 memory modules or errors in the memory controller will not be detected, so it’s still possible to end up with bad data should either of those two devices malfunction. By the same token this is solely a detection scheme, so there are no error correction abilities. The only way to correct a transmission error is to keep trying until the bus gets it right.
Now in spite of the difficulties in building and operating such a high speed bus, error detection is not necessary for its operation. As AMD was quick to point out to us, cards still need to ship defect-free and not produce any errors. Or in other words, the error detection mechanism is a failsafe mechanism rather than a tool specifically to attain higher memory speeds. Memory supplier Qimonda’s own whitepaper on GDDR5 pitches error correction as a necessary precaution due to the increasing amount of code stored in graphics memory, where a failure can lead to a crash rather than just a bad pixel.
In any case, for normal use the ramifications of using GDDR5’s error detection capabilities should be non-existent. In practice, this is going to lead to more stable cards since memory bus errors have been eliminated, but we don’t know to what degree. The full use of the system to retransmit a data burst would itself be a catch-22 after all – it means an error has occurred when it shouldn’t have.
Like the changes to VRM monitoring, the significant ramifications of this will be felt with overclocking. Overclocking attempts that previously would push the bus too hard and lead to errors now will no longer do so, making higher overclocks possible. However this is a bit of an illusion as retransmissions reduce performance. The scenario laid out to us by AMD is that overclockers who have reached the limits of their card’s memory bus will now see the impact of this as a drop in performance due to retransmissions, rather than crashing or graphical corruption. This means assessing an overclock will require monitoring the performance of a card, along with continuing to look for traditional signs as those will still indicate problems in memory chips and the memory controller itself.
Ideally there would be a more absolute and expedient way to check for errors than looking at overall performance, but at this time AMD doesn’t have a way to deliver error notices. Maybe in the future they will?
Wrapping things up, we have previously discussed fast link re-training as a tool to allow AMD to clock down GDDR5 during idle periods, and as part of a failsafe method to be used with error detection. However it also serves as a tool to enable higher memory speeds through its use in temperature compensation.
Once again due to the high speeds of GDDR5, it’s more sensitive to memory chip temperatures than previous memory technologies were. Under normal circumstances this sensitivity would limit memory speeds, as temperature swings would change the performance of the memory chips enough to make it difficult to maintain a stable link with the memory controller. By monitoring the temperature of the chips and re-training the link when there are significant shifts in temperature, higher memory speeds are made possible by preventing link failures.
And while temperature compensation may not sound complex, that doesn’t mean it’s not important. As we have mentioned a few times now, the biggest bottleneck in memory performance is the bus. The memory chips can go faster; it’s the bus that can’t. So anything that can help maintain a link along these fragile buses becomes an important tool in achieving higher memory speeds.








327 Comments
View All Comments
SiliconDoc - Thursday, September 24, 2009 - link
Are you seriously going to claim that all ATI are not generally hotter than the nvidia cards ? I don't think you really want to do that, no matter how much you wail about fan speeds.The numbers have been here for a long time and they are all over the net.
When you have a smaller die cranking out the same framerate/video, there is simply no getting around it.
You talked about the 295, as it really is the only nvidia that compares to the ati card in this review in terms of load temp, PERIOD.
In any other sense, the GT8800 would be laughed off the pages comparing it to the 5870.
Furthermore, one merely needs to look at the WATTAGE of the cards, and that is more than a plenty accurate measuring stick for heat on load, divided by surface area of the core.
No, I'm not the one not thinking, I'm not the one TROLLING, the TROLLING is in the ARTICLE, and the YEAR plus of covering up LIES we've had concerning this very issue.
Nvidia cards run cooler, ati cards run hotter, PERIOD.
You people want it in every direction, with every lying whine for your red god, so pick one or the other:
1.The core sizes are equivalent, or 2. the giant expensive dies of nvidia run cooler compared to the "efficient" "new technology" "packing the data in" smaller, tiny, cheap, profit margin producing ATI cores.
------
NOW, it doesn't matter what lies or spin you place upon the facts, the truth is absolutely apparent, and you WON'T be changing the physical laws of the universe with your whining spin for ati, and neither will the trolling in the article. I'm going to stick my head in the sand and SCREAM LOUDLY because I CAN'T HANDLE anyone with a lick of intelligence NOT AGREEING WITH ME! I LOVE TO LIE AND TYPE IN CAPS BECAUSE THAT'S HOW WE ROLL IN ILLINOIS!
SiliconDoc - Friday, September 25, 2009 - link
Well that is amazing, now a mod or site master has edited my text.Wow.
erple2 - Friday, September 25, 2009 - link
This just gets better and better...Ultimately, the true measure of how much waste heat a card generates will have to look at the power draw of the card, tempered with the output work that it's doing (aka FPS in whatever benchmark you're looking at). Since I haven't seen that kind of comparison, it's impossible to say anything at all about the relative heat output of any card. So your conclusions are simply biased towards what you think is important (and that should be abundantly clear).
Given that one must look at the performance per watt. Since the only wattage figures we have are for OCCT or WoW playing, so that's all the conclusions one can make from this article. Since I didn't see the results from the OCCT test (in a nice, convenient FPS measure), we get the following:
5870: 73 fps at 295 watts = 247 FPS per milliwatt
275: 44.3 fps at 317 watts = 140 FPS per milliwatt
285: 45.7 fps at 323 watts = 137 FPS per milliwatt
295: 68.9 fps at 380 watts = 181 FPS per milliwatt
That means that the 5870 wins by at least 36% over the other 3 cards. That means that for this observation, the 5870 is, in fact, the most efficient of these cards. It therefore generates less heat than the other 3 cards. Looking at the temperatures of the cards, that strictly measures the efficiency of the cooler, not the efficiency of the actual card itself.
You can say that you think that I'm biased, but ultimately, that's the data I have to go on, and therefore that's the conclusions that can be made. Unfortunately, there's nothing in your post (or more or less all of your posts) that can be verified by any of the information gleaned from the article, and therefore, your conclusions are simply biased speculation.
SiliconDoc - Saturday, September 26, 2009 - link
4780, 55nm, 256mm die, 150watts HOTG260, 55nm, 576mm die, 171watts COLD
3870, 55nm, 192mm die, 106watts HOT
That's all the further I should have to go.
3870 has THE LOWEST LOAD POWER USEAGE ON THE CHARTS
- but it is still 90C, at the very peak of heat,
because it has THE TINIEST CORE !
THE SMALLEST CORE IN THE WHOLE DANG BEJEEBER ARTICLE !
It also has the lowest framerate - so there goes that erple theory.
---
The anomlies you will notice if you look, are due to nm size, memory amount on board (less electricity used by the memory means the core used more), and one slot vs two slot coolers, as examples, but the basic laws of physics cannot be thrown out the window because you feel like doing it, nor can idiotic ideas like framerate come close to predicting core temp and it's heat density at load.
Older cpu's may have horrible framerates and horribly high temps, for instance. The 4850 frames do not equal the 4870's, but their core temp/heat density envelope is very close to indentical ( SAME CORE SIZE > the 4850 having some die shaders disabled and ddr3, the 4870 with ddr5 full core active more watts for mem and shaders, but the same PHYSICAL ISSUES - small core, high wattage for area, high heat)
erple2 - Tuesday, September 29, 2009 - link
I didn't say that the 3870 was the most efficient card. I was talking about the 5870. If you actually read what I had typed, I did mention that you have to look at how much work the card is doing while consuming that amount of power, not just temperatures and wattage.You sir, are a Nazi.
Actually, once you start talking about heat density at load, you MUST look at the efficiency of the card at converting electricity into whatever it's supposed to be doing (other than heating your office). Sadly, the only real way that we have to abstractly measure the work the card is doing is "FPS". I'm not saying that FPS predict core temperature.
SiliconDoc - Wednesday, September 30, 2009 - link
No, the efficiency of conversion you talk about has NOTHING to do with core temp AT ALL. The card could be massively efficient or inefficient at produced framerate, or just ERROR OUT with a sick loop in the core, and THAT HAS ABSOLUTELY NOTHING TO DO WITH THE CORE TEMP. IT RESTS ON WATTS CONSUMED EVEN IF FRAMERATE OUTPUT IS ZERO OR 300SECOND.(your mind seems to have imagined that if the red god is slinging massive frames "out the dvi port" a giant surge of electricity flows through it to the monitor, and therefore "does not heat the card")
I suggest you examine that lunatic red notion.
What YOU must look at is a red rooster rooter rimshot, in order that your self deception and massive mistake and face saving is in place, for you. At least JaredWalton had the sense to quietly skitter away.
Well, being wrong forever and never realizing a thing is perhaps the worst road to take.
PS - Being correct and making sure the truth is defended has nothing to do with some REDEYE cleche, and I certainly doubt the Gregalouge would embrace red rooster canada card bottom line crumbled for years ever more in a row, and diss big green corporate profits, as we both obviously know.
" at converting electricity into whatever it's supposed to be doing (other than heating your office). "
ONCE IT CONVERTS ELECTRICITY, AS IN "SHOWS IT USED MORE WATTS" it doesn't matter one ding dang smidgen what framerate is,
it could loop sand in the core and give you NO screeen output,
and it would still heat up while it "sat on it's lazy", tarding upon itself.
The card does not POWER the monitor and have the monitor carry more and more of the heat burden if the GPU sends out some sizzly framerates and the "non-used up watts" don't go sailing out the cards connector to the monitor so that "heat generation winds up somewhere else".
When the programmers optimize a DRIVER, and the same GPU core suddenly sends out 5 more fps everything else being the same, it may or may not increase or decrease POWER USEAGE. It can go ANY WAY. Up, down, or stay the same.
If they code in more proper "buffer fills" so the core is hammered solid, instead of flakey filling, the framerate goes up - and so does the temp!
If they optimize for instance, an algorythm that better predicts what does not need to be drawn as it rests behind another image on top of it, framerate goes up, while temp and wattage used GOES DOWN.
---
Even with all of that, THERE IS ONLY ONE PLACE FOR THE HEAT TO ARISE... AND IT AIN'T OUT THE DANG CABLE TO THE MONITOR!
SiliconDoc - Friday, September 25, 2009 - link
You can modify that, or be more accurate, by using core mass, (including thickness of the competing dies) - since the core mass is what consumes the electricity, and generates heat. A smaller mass (or die size, almost exclusively referred to in terms of surface area with the assumption that thickness is identical or near so) winds up getting hotter in terms of degrees of Celcius when consuming a similar amount of electricity.Doesn't matter if one frame, none, or a thousand reach your eyes on the monitor.
That's reality, not hokum. That's why ATI cores run hotter, they are smaller and consume a similar amount of electricty, that winds up as heat in a smaller mass, that means hotter.
Also, in actuality, the ATI heatsinks in a general sense, have to be able to dissipate more heat with less surface area as a transfer medium, to maintain the same core temps as the larger nvidia cores and HS areas, so indeed, should actually be "better stock" fans and HS.
I suspect they are slightly better as a general rule, but fail to excel enough to bring core load temps to nvidia general levels.
erple2 - Friday, September 25, 2009 - link
You understand that if there were no heatsink/cooling device on a GPU, it would heat up to crazy levels, far more than would be "healthy" for any silicon part, right? And you understand that measuring the efficiency of a part involves a pretty strong correlation between the input power draw of the card vs. the work that the card produces (which we can really only measure based on the output of the card, namely FPS), right?So I'm not sure that your argument means anything at all?
Curiously, the output wattage listed is for the entire system, not just for the card. Which means that the actual differences between the ATI cards vs. the nvidia cards is even larger (as a percentage, at least). I don't know what the "baseline" power consumption of the system (sans video card) is for the system acting as the test bed is.
Ultimately, the amount of electricity running through the GPU doesn't necessarily tell you how much heat the processors generate. It's dependent on how much of that power is "wasted" as heat energy (that's Thermodynamics for you). The only way to really measure the heat production of the GPU is to determine how much power is "wasted" as heat. Curiously, you can't measure that by measuring the temperature of the GPU. Well, you CAN, but you'd have to remove the Heatsink (and Fan). Which, for ANY GPU made in the last 15 years, would cook it. Since that's not a viable alternative, you simply can't make broad conclusions about which chip is "hotter" than another. And that is why your conclusions are inconclusive.
BTW, the 5870 consumes "less" power than the 275, 285 and 295 GPUs (at least, when playing WoW).
I understand that there may be higher wattage per square millimeter flowing through the 5870 than the GTX cards, but I don't see how that measurement alone is enough to state whether the 5870 actually gets hotter.
SiliconDoc - Saturday, September 26, 2009 - link
Take a look at SIZE my friend.http://www.hardforum.com/showthread.php?t=1325165">http://www.hardforum.com/showthread.php?t=1325165
There's just no getting around the fact that the more joules of heat in any time period (wattage used!= amount of joules over time!) that go into a smaller area, the hotter it gets, faster !
Nothing changes this, no red rooster imagination will ever change it.
SiliconDoc - Saturday, September 26, 2009 - link
NO, WRONG." Ultimately, the true measure of how much waste heat a card generates will have to look at the power draw of the card, tempered with the output work that it's doing (aka FPS in whatever benchmark you're looking at)."
NO, WRONG.
---
Look at any of the cards power draw in idle or load. They heat up no matter how much "work" you claim they do, by looking at any framerate, because they don't draw the power unless they USE THE POWER. That's the law that includes what useage of electricity MEANS for the law of thermodynamics, or for E=MC2.
DUHHHHH.
---
If you're so bent on making idiotic calculations and applying them to the wrong ideas and conclusions, why don't you take core die size and divide by watts (the watts the companies issue or take it from the load charts), like you should ?
I know why. We all know why.
---
The same thing is beyond absolutely apparent in CPU's, their TDP, their die size, and their heat envelope, including their nm design size.
DUHHH. It's like talking to a red fanboy who cannot face reality, once again.