AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
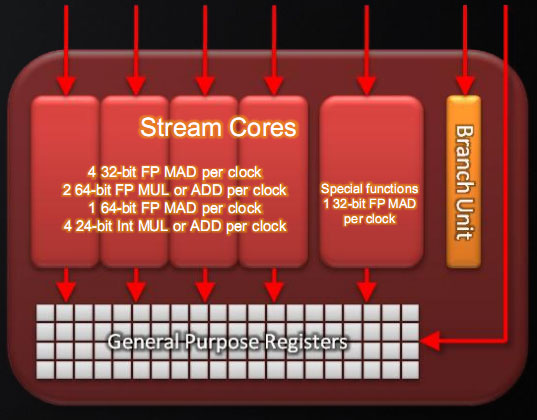
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
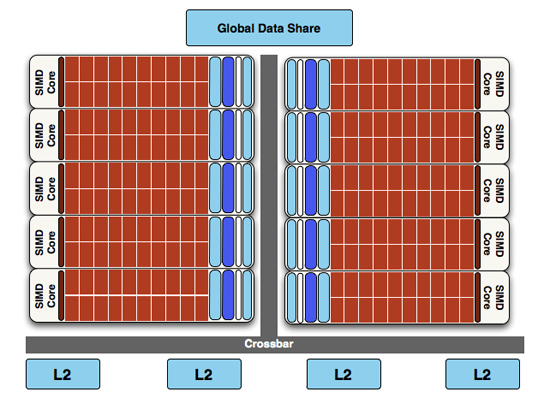
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
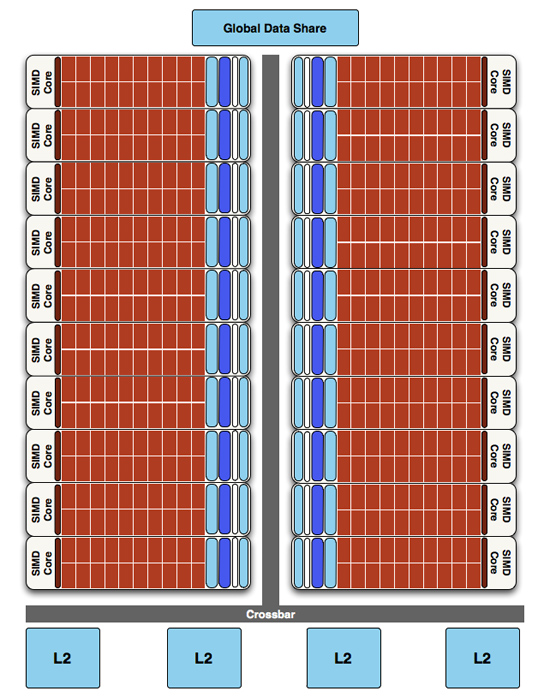
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
RV770 vs...
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
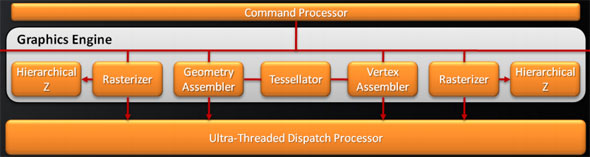
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.








327 Comments
View All Comments
SiliconDoc - Wednesday, September 30, 2009 - link
No, it's the fact you tell LIES, and always in ati's favor, and you got caught, over and over again.That is WHAT HAS HAPPENED.
Now you catch hold of your senses for a moment, and supposedly all the crap you spewed is "ok".
SiliconDoc - Friday, September 25, 2009 - link
Once again, all that matters to YOU, is YOUR games for PC, and ONLY top sellers, and only YOUR OPINION on PhysX.However, after you claimed only 2 games, you went on to bloviate about Havok.
Now you've avoided entirely that issue. Am I to assume, as you have apparently WISHED and thrown about, that HAVOK does not function on NVidia cards? NO QUITE THE CONTRARY !
--
What is REAL, is that NVidia runs Havok AND PhysX just fine, and not only that but ATI DOES NOT.
Now, instead of supporting BOTH, you have singled out your object of HATRED, and spewed your infantile rants, your put downs, your empty comparisons (mere statements), then DEMAND that I show PhysX is worthwhile, with "golden sellers". LOL
It has been 1.5 years or so since Aegia acquisition, and of course, game developers turning anything out in just 6 short months are considered miracle workers.
The real problem oif course for you is ATI does not support PhysX, and when a rouge coder made it happen, NVidia supported him, while ATI came in and crushed the poor fella.
So much for "competition", once again.
Now, I'd demand you show where HAVOK is worthwhile, EXCEPT I'm not the type of person that slams and reams and screams against " a percieved enemy company" just because "my favorite" isn't capable, and in that sense, my favorite IS CAPABLE.
Now, PhysX is awesome, it's great, it's the best there is, and that may or may not change, but as for now, NO OTHER demonstrations (you tube and otherwise) can match it.
That's just a sad fact for you, and with so many maintaining your biased and arrogant demand for anything else, we may have another case of VHS instead of BETA, which of course, you would heartily celebrate, no matter how long it takes to get there.
LOL
Yes, it is funny. It's just hilarious. A few months ago before Mirror's Edge and Anand falling in love with PhysX in it, admittedly, in the article he posted, we had the big screamers whining ZERO.
Well, now a few months later you are whining TWO.
Get ready to whine higher. Yes, you have read about the uptick in support ? LOL
You people are really something.
Oh, I know, CUDA is a big fat zero according to you, too.
(please pass along your thoughts to higher education universities here in the USA, and the federal government national lab research facilites. Thanks)
SiliconDoc - Thursday, September 24, 2009 - link
Yes, another excuse monger. So you basically admit the text is biased, and claim all readers should see the charts and go by those. LOLSo when the text is biased, as you admit, how is it that the rest, the very core of the review is not ? You won't explain that either.
Furthermore, the assumption that competition leads to something better in technology for videocards quicker, fails the basic test that in terms of technology, there is a limit to how fast it proceeds forward, since scientific breakthroughs must come, and often don't come, for instance, new energy technologies, still struggling after decades to make a breakthrough, with endless billions spent, and not much to show for it.
Same here with videocards, there is a LIMIT to the advancement speed, and competition won't be able to exceed that limit.
Furthermore, I NEVER said prices won't be driven down by competition, and you falsely asserted that notion to me.
I DID however say, ATI ALSO IS KNOWN FOR OVERPRICING. (or rather unknown by the red fans, huh, even said by omission to have NOT COMMITTED that "huge sin", that you all blame only Nvidia for doing.)
So you're just WRONG once again.
Begging the other guy to "not argue" then mischaracterizing a conclusion from just one of my statements, ignoring the points made that prove your buddy wrong period, and getting the body of your idea concerning COMPETITION incorrect due to technological and scientific constraints you fail to include, is no way to "argue" at all.
I sure wish there was someone who could take on my points, but so far none of you can. Every time you try, more errors in your thinking are easily exposed.
A MONOPOLY, in let's take for instance, the old OIL BARRONS, was not stagnant, and included major advances in search and extraction, as Standard Oil history clearly testifies to.
Once again, the "pat" cleche' is good for some things ( for instance competing drug stores, for example ), or other such things that don't involve inaccesible technology that has not been INVENTED yet.
The fact that your simpleton attitude failed to note such anomolies, is clearly evidence that once again, thinking "is not reuired" for people like you.
Once again, the rebuttal has failed.
kondor999 - Thursday, September 24, 2009 - link
This is just sad, and I'm no fanboy. I really wanted a 5870, but only with 100% more speed than a GTX285 - not a lousy 33%. Definitely not worth me upgrading, so I guess ATI saved me some money. I'm certain that my 3 GTX280's in Tri-SLI will destroy 2 5870's in CF - although with slightly less compatability (an important advantage for ATI, but not nearly enough).Moricon - Thursday, September 24, 2009 - link
I have been a regular at Tomshardware for a while now, nad keep coming back to Anandtech time and again to read reviews I have already read on other sites, and this one is by far the best I have read so far, (guru3d, toms, firing squad, and many others)The 5870 looks awesome, but from an upgrade point of view, I guess my system will not really benefit from moving on from E7200 @3.8ghz 4gb 1066, HD4870 @850mhz 4400mhz on 1680x1050.
Such a shame that i dont have a larger monitor at the moment or I would have jumped immediately.
Looks like the path is q9550 and 5870 and 1920x1200 monitor or larger to make sense, then might as well go i7, i5, where do you stop..
Well done ATI, well done! But if history follows the Nvidia 3xx chip will be mindblowing compared!
djc208 - Thursday, September 24, 2009 - link
I was most surprised at how far behind the now 2-generation old 3870 is now (at least on these high-end games). Guess my next upgrade (after a SSD) should be a 5850 once the frenzy dies away.JonnyDough - Thursday, September 24, 2009 - link
They could probably use a 1.5 GB card. :(mapesdhs - Wednesday, September 23, 2009 - link
Ryan, any chance you could run Viewperf or other pro-app benchmarks
please? Some professionals use consumer hardware as a cheap way of
obtaining reasonable performance in apps like Maya, 3DS Max, ProE,
etc., so it would most interesting to know how the 5870 behaves when
running such tests, how it compares to Quadro and FireGL cards.
Pro-series boards normally have better performance for ops such as
antialiases lines via different drivers and/or different internal
firmware optimisations. Someday I figure perhaps a consumer card will
be able to match a pro card purely by accident.
Ian.
AmdInside - Wednesday, September 23, 2009 - link
Sorry if this has already been asked but does the 5870 support audio over Display Port? I am holding out for a card that does such a thing. I know it does it for HDMI but also want it to do it for Display Port.VooDooAddict - Wednesday, September 23, 2009 - link
Been waiting for a single gaming class card that can power more then 2 displays for quite some time. (The more then 2 monitors not necessarily for gaming.)The fact that this performs a noticeable bit better then my existing 4870 512MB is a bonus.