Nehalem Part 3: The Cache Debate, LGA-1156 and the 32nm Future
by Anand Lal Shimpi on November 19, 2008 8:00 PM EST- Posted in
- CPUs
Another Part? Oh there will be more
In an unexpected turn of events I found myself deep in conversation with many Intel engineers as well as Pat Gelsinger himself about the design choices made in Nehalem. At the same time, Intel just released its 2009 roadmap which outlined some of the lesser known details of the mainstream LGA-1156 Nehalem derivatives.
I hadn’t planned on my next Nehalem update being about caches and mainstream parts, but here we go. For further reading I'd suggest our first two Nehalem articles and the original Nehalem architecture piece.
Nehalem’s Cache: More Controversial Than You’d Think
I spoke with Ronak Singhal, Chief Architect on Nehalem, at Intel’s Core i7 launch event last week in San Francisco and I said to him: “I think you got the cache sizes wrong on Nehalem”. I must be losing my shyness.

He thought I was talking about the L3 cache and asked if I meant it needed to be bigger, and I clarified that I was talking about the anemic 256KB L2 per core.
We haven’t seen a high end Intel processor with only 256KB L2 per core since Willamette, the first Pentium 4. Since then Intel has been on a steady ramp upwards as far as cache sizes go. I made a graph of L2 cache size per core of all of the major high end Intel cores for the past decade:
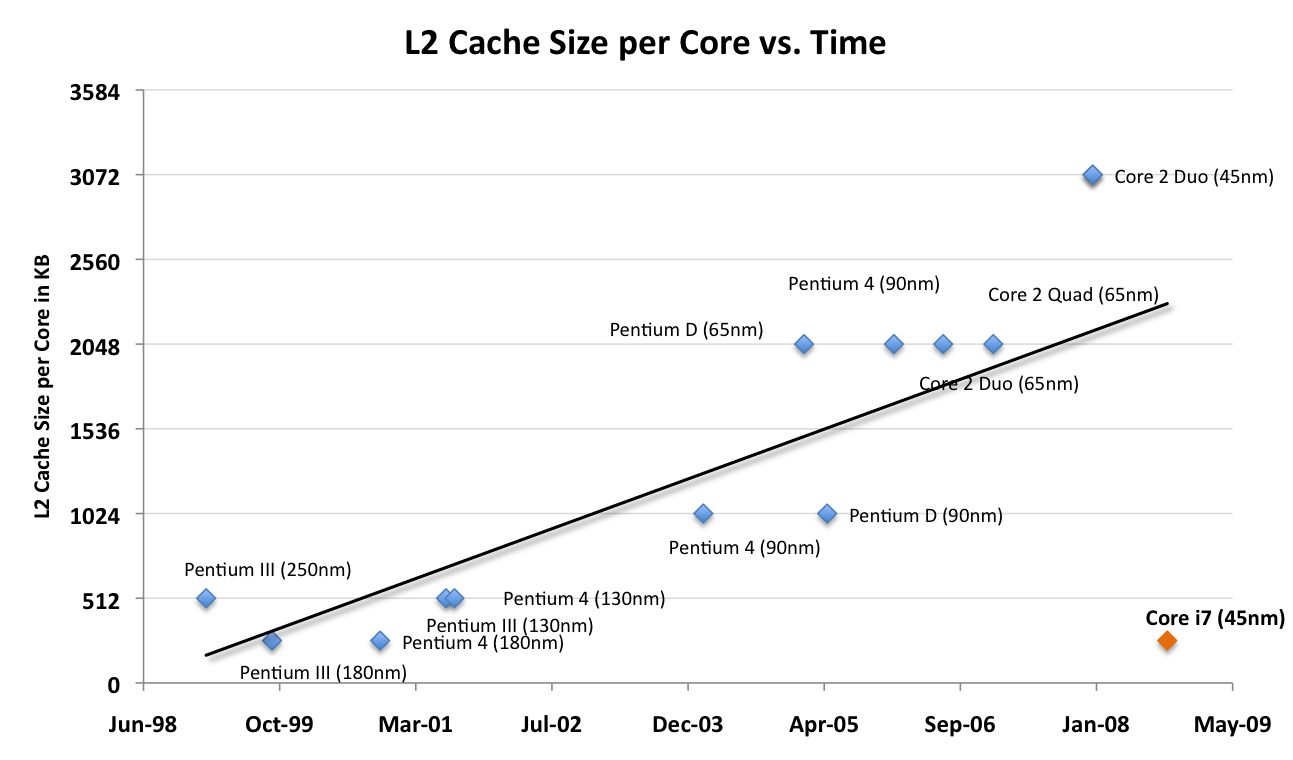
For the most part we’ve got a linear trend, there are a few outliers but you can see that earlier in 2008 you’d expect Intel CPUs to have around 2 - 3MB of L2 cache per core. Now look at the lower right of the chart, see the little orange outlier? Yeah, that’s the Core i7 with its 256KB L2 cache per core, it’s like 2002 - 2007 never happened.
If we look at total on-chip cache size however (L2 + L3), the situation is very different:
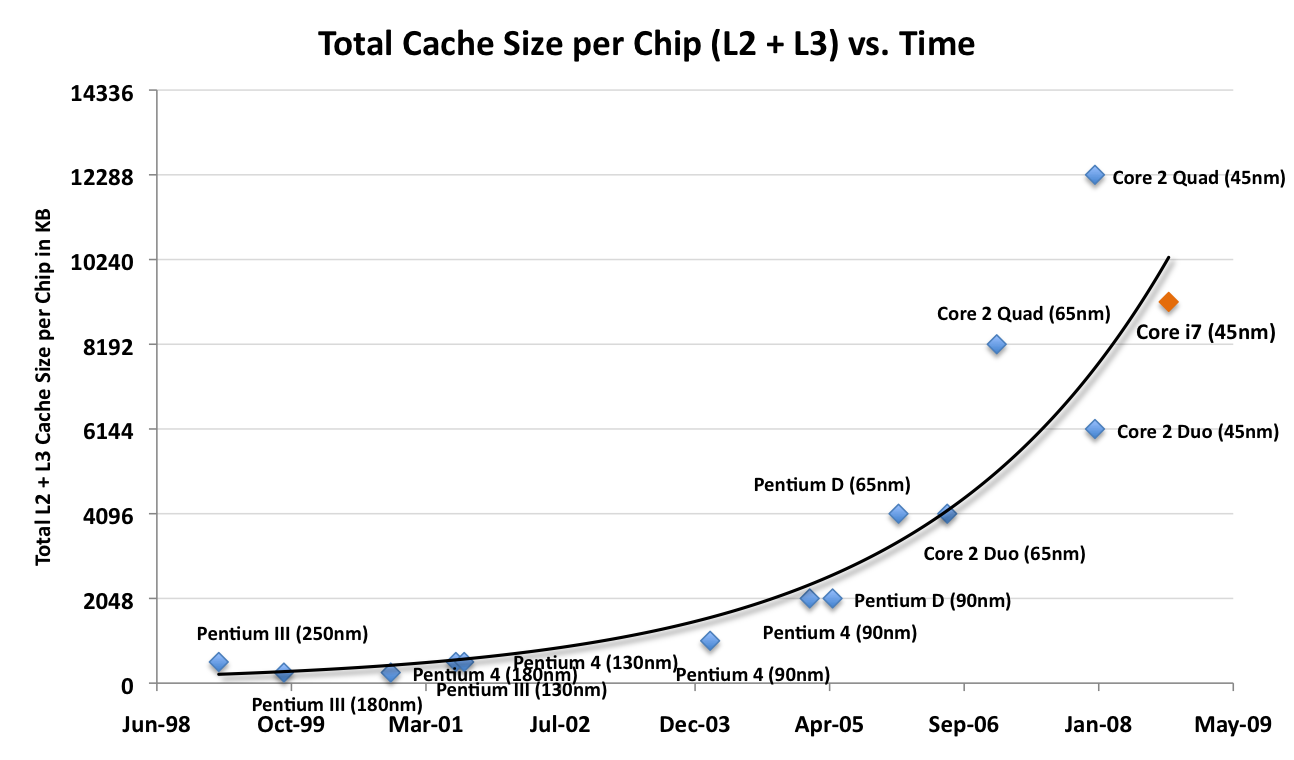
Now we’ve got an exponential growth of cache size, not linear, and all of the sudden the Core i7 conforms to societal norms. To understand why, we have to look at what happened around 2005 - 2006: Intel started shipping dual-core CPUs. As core count went up, so did the total amount of cache per chip. Dual core CPUs quickly started shipping with 2MB and 4MB of cache per chip and the outgoing 45nm quad-core Penryns had 12MB of L2 cache on a single package.
The move to multi-core chip designs meant that the focus was no longer on feeding the individual core, but making sure all of the cores on the chip were taken care of. It’s all so very socialist (oh no! ;) ).
Nehalem was designed to be a quad-core product, but also one that’s able to scale up to 8 cores and down to 2 cores. Intel believes in this multi-core future so designing for dual-core didn’t make sense as eventually dual-core will go away in desktops, a future that’s still a few years away but a course we’re on nonetheless.

AMD's shift to an all quad-core client roadmap
Intel is pushing the shift to quad-core, much like AMD is. By 2010 all of AMD’s mainstream and enthusiast CPUs will be quad-core with the ultra low end being dual-core, a trend that will continue into 2011. The shift to quad-core makes sense, unfortunately today very few consumer applications benefit from four cores. I hate to keep re-using this same table but it most definitely applies here:
Back when AMD introduced its triple-core Phenom parts I put together a little table illustrating the speedup you get from one, two and four cores in SYSMark 2007:
| SYSMark 2007 Overall | E-Learning | Video Creation | Productivity | 3D | |
| Intel Celeron 420 (1 core, 512KB, 1.6GHz) | 55 | 52 | 55 | 54 | 58 |
| Intel Celeron E1200 (2 cores, 512KB, 1.6GHz) | 76 | 68 | 91 | 70 | 78 |
| % Increase from 1 to 2 cores | 38% | 31% | 65% | 30% | 34% |
| Intel Core 2 Duo E6750 (2 cores, 4MB, 2.66GHz) | 138 | 147 | 141 | 120 | 145 |
| Intel Core 2 Quad Q6700 (4 cores, 8MB, 2.66GHz) | 150 | 145 | 177 | 121 | 163 |
| % Increase from 2 to 4 cores | 8.7% | 0% | 26% | 1% | 12% |
Not only are four cores unnecessary for most consumers today, but optimizing a design for four cores by opting for very small, low latency L2 caches and a large, higher latency L3 cache for the chip isn’t going to yield the best desktop performance.
A Nehalem optimized for two cores would have a large L2 cache similar to what we saw happening on the first graph, but one optimized for four or more cores would look like what the Core i7 ended up being. What’s impressive is that Intel, in optimizing for a quad-core design, was still able to ensure that performance either didn’t change at all or improved in applications that aren’t well threaded.
Apparently the L2 cache size was and still is a controversial issue within Intel, many engineers still feel like it is too small for current workloads. The problem with making it larger is not just one of die size, but also one of latency. Intel managed to get Nehalem’s L2 cache down to 10 cycles, the next bump in L2 size would add another 1 - 2 cycles to its latency. At 512KB per core, 20% longer to access the cache was simply unacceptable to the designers.
In fact, going forward there’s no guarantee that the L2 caches will see growth in size, but the focus instead may be on making the L3 cache faster. Right now the 8MB L3 cache takes around 41 cycles to access, but there’s clearly room for improvement - getting a 30 cycle L3 should be within the realm of possibility. I pushed Ronak for more details on how Intel would achieve a lower latency L3, but the best I got was “microarchitectural tweaks”.
As I mentioned before, Ronak wanted the L3 to be bigger on Nehalem; at 8MB that’s only 2MB per core and merely sufficient in his eyes. There are two 32nm products due out in the next 2 years, I suspect that at least one of them will have an even larger L3 to continue the exponential trend I showed in the second chart above.
Could the L2 be larger? Sure. But Ronak and his team ultimately felt that the tradeoff between size/latency was necessary for what Intel’s targets were with Nehalem. And given its 0 - 60% performance increase, clock for clock, over Penryn - I can’t really argue.








{kind=link}
33 Comments
View All Comments
SiliconDoc - Saturday, December 27, 2008 - link
" The move to multi-core chip designs meant that the focus was no longer on feeding the individual core, but making sure all of the cores on the chip were taken care of. It’s all so very socialist (oh no! ;) ). "Umm... wouldn't socialist be more like feeding one or two of the four cores, and all you get back is cache misses, or a stalled pipeline anyway ? I mean, if you're feeding the core, it is expected to do some work. So this is clearly not socialist.
Maybe you meant it's socialist in the sense that all 4 cores can't be kept fed and therefore working, so most the time they're standing around with the shovel, because yeah they are "on the job", but they ain't doing much, but the clock keeps ticking and ticking... gosh when is the city street core gonna move that and+ sign, and why does it take 5cas to get it done...look at that the bueaucratic core keeps pushing through dirty bits paper and asking for another copy...
:-0)
Yes, making the 256k cache work properly to "feed" all the cores and keep them working is the exact opposite of socialism. The exact opposite.
JonnyDough - Friday, November 21, 2008 - link
I think it's pretty obvious what's happening here. Intel is pedaling slowly, waiting for AMD to catch up. It's obvious to everyone that more cache would feed the cores better, but with nothing from AMD to answer - there's no need to make huge gains. They'd prefer to milk the market with incremental advances and sell us the same architecture more times, increasing cache as they will.Bullfrog2099 - Friday, November 21, 2008 - link
Theres one more thing that Intel needs to be grilled about.Will Bloomsfield and Westmere run on the same motherboard since they both use the same socket? Or will you have to buy a new mb if you want to upgrade to 32nm?
USSSkipjack - Thursday, November 20, 2008 - link
I am also very concerned about the cache sizes in the Nehalem architecture. We are doing interactive realtime software volume rendering and that has naturally a very high demand on the CPU. A current Q9450 is actually doing quite well due to its large cache (12 MB) it is also quite inexpensive for its power. Actually we need pure FP power and the ability to feed large amounts of data to the CPU in a short time. Just imagine gigabytes of data that need to be processed in realtime.Of course faster is always better and due to the nature of our renderer it also scales very nicely with additional cores. So we were hoping for the release of an affordable 8 core (single package or die) product before the first quarter of next year. Instead we get Nehalem which seems to be inferior for our cause due to its smaller (and slower) cache. Hyperthreading wont help us much, due to the FP nature of almost everything we do.
Still I am somewhat encouraged by the rather good benchmarks we have seen so far. So my question is, in a direct comparison how does a very cache dependent application do in a Nehalem CPU versus a Q9750 or simillar current quad core?
Anyone got any benchmarks that shed light on that?
bollux78 - Thursday, November 20, 2008 - link
MAY BE with current knowledge (or lack of) about general physics and stuff that overcome any industrial attempt, there is nothing very exciting to do about processors. We REALLY should stop thinking stuff will go faster and faster and start to look back at real programmers that made miracles on insignificant hardware, like the amiga, lots of jap PCs etc. Video games should not be even commented, because their hardware is un-upgradeable, and yet, the guys make things run on them no matter what. see PS2 as an outrageous example. they made all NFS series on n and more, and nobody put more than 32mb of ram. I´m sorry guys (ans gals where applicable) but this is all bull, people wanting to tease all of us with new unncessary hardware, lots of useless modifications that make no sense for the end user etc. There should be more programmers and soft engineers and less wall street bastards.mutarasector - Monday, November 24, 2008 - link
"We REALLY should stop thinking stuff will go faster and faster and start to look back at real programmers that made miracles on insignificant hardware, like the amiga, lots of jap PCs etc."As a former Amiga software developer, I tend to agree with this statement. While I wouldn't go quite so far as to say we shouldn't expect to see hardware speed improvements, I would modify that expectation in that future hardware R&D shouldn't be oriented towards 'brute force' speed enhancements, but should be more granular refinements. To be sure, I think we are indeed seeing this from both AMD and Intel, particularly with cache structuring and power optimizations.
The *real* problem here is that hardware development is still largely driven by an agenda with an eye towards favoring Microsoft bloatware on monolithic architectures by AMD and Intel. This is ultimately a dead-end as it still fails to address the fundamental mindset changes required to push computing technologies forward in the long term. The first (and most important) change is to get OS and application development moving towards more tightly handcrafted/refined coding that assumes more responsibility for things currently implemented in silicon rather than contiuing down the path of "how can continue to take it up the whazoo endlessly refining our silicon to satisfy Microsoft bloatware requirements".
Microsoft and Google are racing towards iOS dominance (even though
at times I think M$ forgets this race is even on), but of the two, Google is clearly the leader here. What would be cool is if Google would get guys like Carl Sassenrath (Amiga Exec/OS developer) to glue it's Google apps together on Carl's REBOL platform.
Shmak - Friday, November 21, 2008 - link
While I follow your reasoning with newer, better, faster, and smaller being crammed down our throats, but speed issues cannot be resolved as easily through the software side of things. The software industry has come to rely on the current cycle of ever speedier hardware.And rightfully so, as nobody wants to have to translate millions of lines of C into Assembler for better efficiency than compliers do. Not to mention the fact that every piece of software with a decent budget uses 3rd party platforms like Direct X. Sure somebody could probably write something more efficient for the specific aims of their game or whatever, but it would probably take them far longer than just integrating the platform as is. Not to mention the fact that many of these things are like "black boxes" that have to be opened up and figured out in order to be improved upon, and people generally don't like messing with code that isn't their own. Yet these 3rd party bits are necessary in the end.
The final thing is that when you program anything decent sized for a PC, you are depending on other people's code. The drivers, the OS, Open CL, whatever, all these things make it possible for consumers to use a variety of hardware. Game consoles and the Amiga could be fine tuned because the developers knew the machine they were testing on was EXACTLY the same as the one that was sitting in your office/living room however many years ago.
USSSkipjack - Thursday, November 20, 2008 - link
Yes, but... physics also limit the amount of data that a current CPU can process either way you see it. One can of course fake things, but there are applications (like ours) where this is not an option. Faking and smoke and mirrors and optimizations are something that works very well for games and even for movie effects work, but we can not do that.It is already a miracle that we do the stuff we do with the current hardware (most others try to use GPUs or even expensive special purpose hardware for that, with all the issues that come with this).
The advantage of using the CPU is scalability. We do fine on a current Q9450, now imagine what we can do on two?
My issue is whether we should do that, or whether Nehalem will indeed bring benefits even for us, even it has a smaller cache. Maybe the new cache configuration and the architecture outdo the lack of cache. This is why I would like to see a direct comparison of Nehalem CPU with a Q9750 in apps that are particularily benefited by larger caches and/or that process a lot of data.
Also, does anyone know when the 8-core Nehalems will come to market?
chizow - Thursday, November 20, 2008 - link
Glad you grilled them about Nehalem's lack of L2 Anand. Lots of good info there, but you should've asked him point-blank if he knew Nehalem didn't show any improvement and in many cases, was slower than Penryn in games. It would've been interesting to hear Ronak's response to that. There's the Guru3D article that shows significant gains in Tri-SLI with an i7 but I haven't seen any other reviews that show nearly as much gain. Hopefully the L3 latency tweaks in Westmere improve gaming performance, but for now there doesn't seem to be much reason for gamers to upgrade from Core 2.ltcommanderdata - Thursday, November 20, 2008 - link
Does having a L3 cache inherently impose a latency constraint on the L2 cache? Afterall, the last time Intel had an independent L2 cache it was on Dothan which was 2MB with 10 cycle latency. Now Nehalem's independent L2 cache is only 256k at 10 cycles and they say going to 512k would have made it 12 cycle.So Westmere is really just going to be a die shrink? I was hoping it'll be something like Penryn, which even though it didn't change that much, I believe it still outperformed Conroe by 5-10% on average. I believe there are some more SSE instructions coming for Westmere for AES and other things.
Supposedly the OpenCL spec has been completed in record time thanks to pressure from Apple to get it out in time for Snow Leopard. It's only awaiting lawyer IP approval. Any chance of getting the details?