The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
That Darn Compute:Texture Ratio
With its GT200 GPU, NVIDIA increased compute resources by nearly 90% but only increased texture processing by 25%, highlighting a continued trend in making GPUs even more powerful computationally. Here's another glance at the GT200's texture address and filter units:
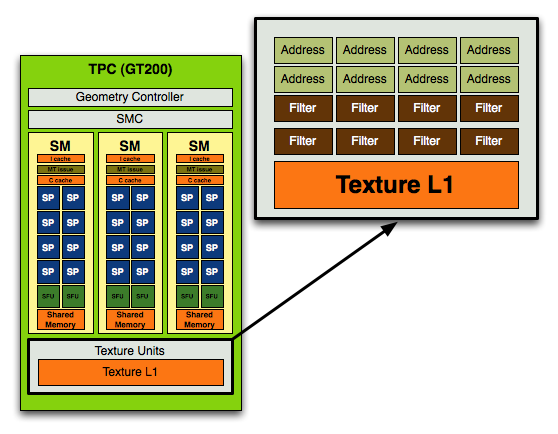
Each TPC, of which there are 10, has eight address and eight filter units. Now let's look at RV770:
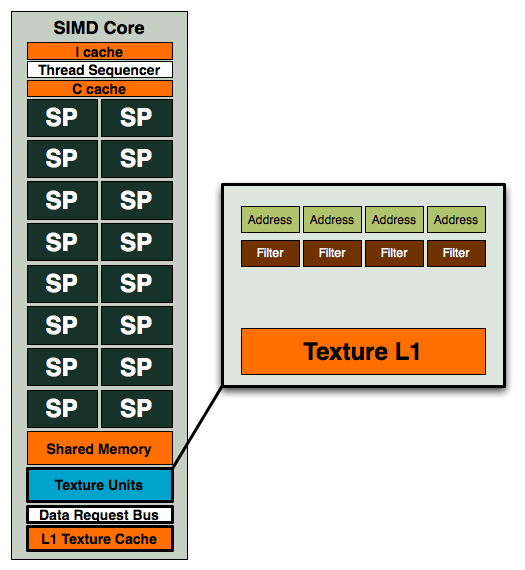
Four address and four filter units, while AMD maintains the same 1:1 address-to-filter ratio that NVIDIA does, the ratio of compute-to-texture in RV770 is significantly higher.
| AMD RV770 | AMD RV670 | NVIDIA GT200 | NVIDIA G92 | |
| # of SPs | 160 | 64 | 240 | 128 |
| Texture Address/Filter Units | 40 / 40 | 16 / 16 | 80 / 80 | 64 / 64 |
| Compute to Texture Ratio | 4:1 | 4:1 | 3:1 | 2:1 |
The table above illustrates NVIDIA's trend of increasing the compute to texture ratio from 2:1 in G92 to 3:1 in GT200. AMD arguably overshot with RV670 and its 4:1 ratio and thus didn't need to adjust it with RV770. Even while staying still at 4:1 with RV770, AMD's ratio is still more aggressively geared towards compute than NVIDIA's is. That does mean that more texture bound games will do better on NVIDIA hardware (at least proportionally), while more compute intensive games may do better on RV770.
AMD did also make some enhancements to their texture units as well. By doing some "stuff" that they won't tell us about, they improved the performance per mm^2 by 70%. Texture cache bandwidth has also been doubled to 480 GB/s while bandwidth between each L1 cache and L2 memory is 384 GB/s. L2 caches are aligned with memory channels of which there are four interleaved channels (resulting in 8 L2 caches).
Now that texture units are linked to both specific SIMD cores and individual L1 texture caches, we have an increase in total texturing ability due to the increase in SIMD cores with RV770. This gives us a 2.5x increase in the number of 8-bit per component textures we can fetch and bilinearly filter per clock, but only a 1.25x increase in the number of fp16 textures (as fp16 runs at half rate and fp32 runs at one quarter rate). It was our understanding that fp16 textures could run at full speed on R600, so the 1.25x increase in performance for half rate texturing of fp16 data makes sense.
Even though fp32 runs at quarter rate, with the types of texture fetches we would need to do, AMD says that we could end up being external memory bandwidth bound before we are texture filtering hardware bound. If this is the case, then the design decision to decrease rates for higher bit-depth textures makes sense.
| AMD RV770 | AMD RV670 | |
| L1 Texture Cache | 10 x 16KB (160KB total) | 32KB |
| L2 Texture Cache | I can has cache size? | 256KB |
| Vertex Cache | ? | 32KB |
| Local Data Share | 16KB | None |
| Global Data Share | 16KB | ? |
Even though AMD wouldn't tell us L1 cache sizes, we had enough info left over from the R600 time frame to combine with some hints and extract the data. We have determined that RV770 has 10 distinct 16k caches. This is as opposed to the single shared 32k L1 cache on R600 and gives us a total of 160k of L1 cache. We know R600's L2 cache was 256k, and AMD told us RV770 has a larger L2 cache, but they wouldn't give us any hints to help out.








215 Comments
View All Comments
Hannahfag - Friday, December 25, 2020 - link
https://thienred.vipost.info/em-s-ch-i-kh-m-u-v-i-...">[img]https://i.ytimg.com/vi/AlLeci80cMw/hqdefault.jpg[/img]Em Sбє» ChЖЎi KhГґ MГЎu Vб»›i Anh LuГґnBenelli RFS https://thienred.vipost.info/em-s-ch-i-kh-m-u-v-i-...">150i BбєЈn LД©nh
EdithAvoiz - Monday, February 15, 2021 - link
https://blacksheeptamil.mnwork.info/videos/rdqLhUM...">[img]https://i.ytimg.com/vi/rdqLhUMWjf8/hqdefault.jpg[/img]https://blacksheeptamil.mnwork.info/videos/rdqLhUM...">Kalluri SaalaiTeaserWebseriesBlacksheep OriginalsBs ValueBlacksheep
DianaAgedo - Tuesday, February 16, 2021 - link
https://cricketicc.vichats.info/show/lisa-sthaleka...">[img]https://i.ytimg.com/vi/eZldn-dMY7U/hqdefault.jpg[/img]Lisa Sthalekar inducted into the ICC Hall of https://cricketicc.vichats.info/show/lisa-sthaleka...">Fame in 2020
AlveraTax - Monday, March 8, 2021 - link
https://starplus.ltwork.info/videos/xydoy5D2u5A-aa...">[img]https://i.ytimg.com/vi/xydoy5D2u5A/hqdefault.jpg[/img]Aapki Nazron Ne https://starplus.ltwork.info/videos/xydoy5D2u5A-aa...">SamjhaStarts Today
heaneyforestrntpe68 - Thursday, October 21, 2021 - link
I'm trying to do the same benchmark for Crysis for my 4850 as I have a similar system and a fresh vista install. Just wondering what kind of driver settings you used. http://phoneplans.mex.tl/