AMD's Phenom Unveiled: A Somber Farewell to K8
by Anand Lal Shimpi on November 19, 2007 1:25 AM EST- Posted in
- CPUs
3D Rendering Performance
We'll start off our look at 3D rendering performance with the latest version of Cinebench, we ran the single and multi-threaded benchmarks and reported the scores below:


Single threaded performance goes to Intel, highlighting a theme you've probably already noticed thus far: Core 2 is far more efficient per clock than Phenom. AMD would need to be at around 2.8 - 2.9GHz to equal the performance of the Core 2 at 2.4GHz in this particular benchmark, even the Phenom 9900 can't cut it.
Looking at the multi-threaded results we see that AMD does gain some ground, but the standings remain unchanged: Intel can't be beat. We can actually answer one more question using the Cinebench results, and that is whether or not AMD's "true" quad-core (as in four cores on a single die) actually has a tangible performance advantage to Intel's quad-core (two dual-core die on a single package).
If we look at the improvement these chips get from running the multi-threaded benchmark, all of the Phenom cores go up in performance by around 3.79x, while all the Intel processors improve by around 3.53x. There's a definite scaling advantage (~7%), but it's not enough to overcome the inherent architectural advantages of the Core 2 processors.
3dsmax 9
As always we have our 3dsmax 9 test, using SPECapc's 3dsmax 8 benchmark files. The numbers we're reporting below are strictly the CPU rendering composite scores:

Here the Phenom 9900 is basically as fast as the Core 2 Q6600, unfortunately for AMD the 9900 doesn't launch until next year and it will launch at a price greater than the Q6600. AMD needs help cutting prices fast if it expects Phenom to remain competitive in the eyes of everyone who doesn't own a Socket-AM2 motherboard.
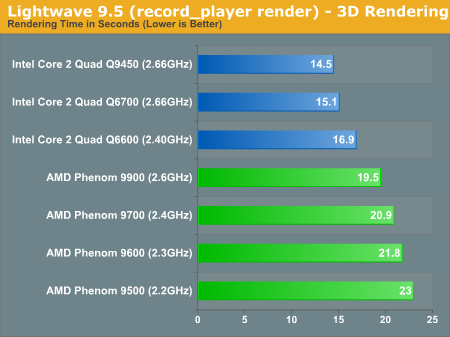
Lightwave 9.5
We see a similar story in our Lightwave benchmarks, the Phenom 9900 at best can equal the performance of the Q6600 but at worst it looks like AMD needs another 200 - 300MHz to catch up to Intel's cheapest quad-core:

POV-Ray
The POV-Ray benchmark is quite possibly the least kind to AMD out of the group:

Intel's Q6600 is 20% faster than AMD's fastest Phenom due out in Q1, it's 30% faster than Phenom at the same clock speed, and 35% faster at the most competitive price point.








124 Comments
View All Comments
Proteusza - Monday, November 19, 2007 - link
Actually, there is every possibility that he is right.First off, how much do you know about instruction sets and compilers? I'm going to assume nothing. If you do know something, then consider this for the edification of other readers.
Compilers take code written in one language and produce an output in another. Specifically, compilers take code written in a language that can be easily understood by humans (ie C++) and output code that a machine can understand (machine code, or bytecode in the case of a JVM).
Now, the problem with enhanced instruction sets, like SSE4, and SSE4.1 and SSE4a, is that they require compiler support. Imagine an instruction set as a vocabulary. And compilers are the programs that produce books, using a specified vocabulary. Now, the simple truth is that Intel makes extra effort to get its vocabulary into use. Thus, Cinebench was most likely compiled with Intel's latest vocabulary, and not AMD's.
So, part of the K10 update was that it allowed SSE operations to be completed much faster, and I'm presuming this requires the use of its new instruction set. If so, that means that Cinebench was basically running in K8 mode.
Not so far fetched, just means AMD has to make sure people update their code. The instruction set issue is another reason why RISC CPU's are generally simpler and faster.
JumpingJack - Monday, November 19, 2007 - link
Look... it is code, that is all ... AMD and Intel are both designing to the same code base, run it on one... then run it on the other... which is faster?Architectural jargon of IMC and victim L3 cache, and x-bit look up ... if it doesn't work it doesn't work.
Kiijibari - Monday, November 19, 2007 - link
Lol .. just code ... imagine a guy talking in a south west Chinese dialect to you. You do not understand anything ? Well .. it is just a language ... ;-)No offense intended: Please do some read up on compliers and programming languages .. it is interesting :)
cheers
Kiiji
Brunnis - Monday, November 19, 2007 - link
Acutally, there shouldn't be any code modifications needed to make use of the new SSE functionality. The difference is internal to the CPU, meaning that it now processes SSE instructions without splitting them. The instructions used are the same as before.That said, there may be untapped potential in the CPU that can be uncovered by the use of a different compiler (due to other reasons). Though, as far as I know, Intel compilers often produce faster code even for AMD CPUs...
About the "architectural advantage" Anand mentioned: Of course the Core 2 has an architectural advantage. It's pretty obvious from the fact that it performs faster, clock-for-clock, in almost all cases while having much higher frequency potential. Not even AMD's integrated memory controller can raise the computational efficiency of their CPU enough to really challenge Intel. AMD may have a more elegant external design and interface to the rest of the system (native quad, HyperTransport, integrated memory controller), but Intel obviously has the more refined internal design. Sadly for AMD, a computational advantage seems to weigh heavier than a neat system/core interface in this case.
Kiijibari - Monday, November 19, 2007 - link
Yes I know what you mean, the SSE instructions are the same, they are just executed faster (in 1 clock compared to 2 clocks before). That is correct, however I wonder how much code is out there that is compiled with the old Intel compilers until 9.X.The problem with these compilers were, that they did not executed the SSE2 codepath on AMD chips, even if the CPU would have been capable of executing it. Instead a slower FPU code is used for AMD K8s.
The newest Intel 10 Compilers have now new compiler flags that can generate SSE2 code for non-intel CPUs, however I did not have seen benches of these so far.
Even the M$ Compiler had some nasty SSE disable "features":
http://einstein.phys.uwm.edu/forum_thread.php?id=6...">http://einstein.phys.uwm.edu/forum_thread.php?id=6...
All in all, I guess there are a lot of programs out there that disable SSE on AMD CPUs :( Therefore a plain compile test of several open-sorce prgorams with gcc / Sun / Pathscale compilers would be nice. Intel CPUs could be benched with Intel compiler, too, any CPU should gets it best code.
cheers
Kiiji
Kiijibari - Monday, November 19, 2007 - link
Yet another wise guy knowing nothing ...Lets imagine an English native speaker ... would he understand Spanish ? No, not much ... but maybe his fried, who learned Spanish in school is better in speaking Spanish, nevertheless, he wont be as good as a native Spanish speaker ...
Who would be the guy with the "superior, best language capabilities" now? The Spanish, the English speaking guy, or his friend ?
Think about it a little bit I am curious about your reply ^^
cheers
Kiiji
MrKaz - Monday, November 19, 2007 - link
“AMD couldn't simply get enough quantities of the Phenom at 2.4GHz to have a sizable launch this year (not to mention a late discovery of a TLB error in the chips),…”I’m very interested in the bug you talked Anand.
Could you say if you know how it affects the CPU:
-Performance?
-Clock speed?
-Slow northbridge clocks?
Or the bug no longer exists in these CPUs?
Complete disappointment.
At least AMD release the 790 motherboards so I can at least put my old CPU on that system with two Ati 3850 cards… ;)
Spoelie - Monday, November 19, 2007 - link
The bug freezes the system at high workloads. It shouldn't have any performance impact.I'm extremely disappointed with phenom, I was planning to get the entire spider platform for my yearly upgrade cycle, but that seems to be a bad idea.
fitten - Monday, November 19, 2007 - link
I would think that transitioning from a running, working system into a brick (not running and not working) would be a fairly significant performance impact ;)
Viditor - Monday, November 19, 2007 - link
I'm waiting for the review on Quad-Crossfire first...
I figure I can get 4 x 3850s for about the same price as an 8800 Ultra. The question is, is it worth it?
If XfireX is good, then I will pull the trigger on 4 x 3850s (or 3870s if I can get them before Xmas), a 790FX mobo, and probably a Phenom 9500...
Then I'll upgrade the Phenom in March when the B3s finally come out.