The Intel Core Ultra 7 155H Review: Meteor Lake Marks A Fresh Start To Mobile CPUs
by Gavin Bonshor on April 11, 2024 8:30 AM ESTASUS Zenbook 14 OLED UX3405MA: AI Performance
As technology progresses at a breakneck pace, so do the demands of modern applications and workloads. As artificial intelligence (AI) and machine learning (ML) become increasingly intertwined with our daily computational tasks, it's paramount that our reviews evolve in tandem. To this end, we have AI and inferencing benchmarks in our CPU test suite for 2024.
Traditionally, CPU benchmarks have focused on various tasks, from arithmetic calculations to multimedia processing. However, with AI algorithms now driving features within some applications, from voice recognition to real-time data analysis, it's crucial to understand how modern processors handle these specific workloads. This is where our newly incorporated benchmarks come into play.
Given makers such as AMD with Ryzen AI and Intel with their Meteor Lake mobile platform feature AI-driven hardware, aptly named Intel AI Boost within the silicon, AI, and inferencing benchmarks will be a mainstay in our test suite as we go further into 2024 and beyond.
The Intel Core Ultra 7 155H includes the dedicated Neural Processing Unit (NPU) embedded within the SoC tile, which is capable of providing up to 11 TeraOPS (TOPS) of matrix math computational throughput. You can find more architectural information on Intel's NPU in our Meteor Lake architectural deep dive. While both AMD and Intel's implementation of AI engines within their Phoenix and Meteor Lake architectures is much simpler than true AI inferencing hardware, these NPUs are more designed to provide a high efficiency processor for handling light-to-modest AI workloads, rather than a boost to overall inferencing performance. For all of these mobile chips, the GPU is typically the next step up for truly heavy AI workloads that need maximum performance.
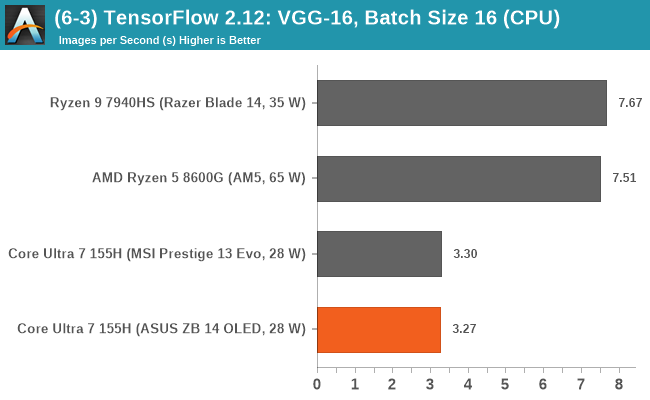
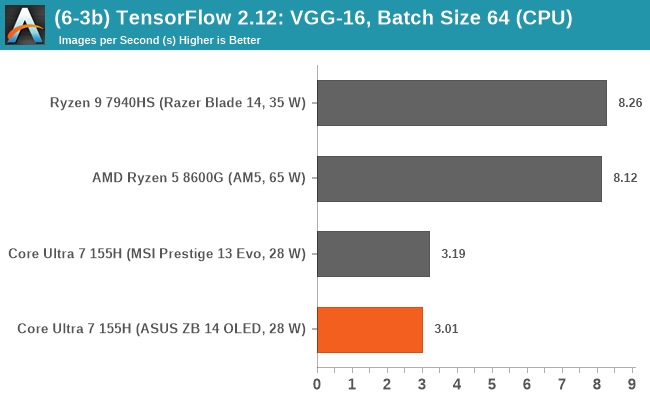
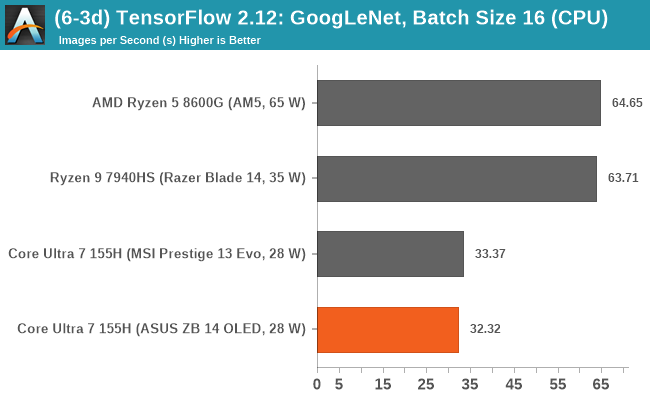
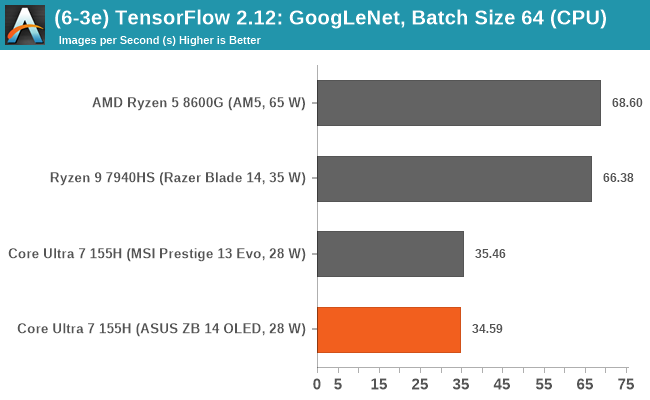
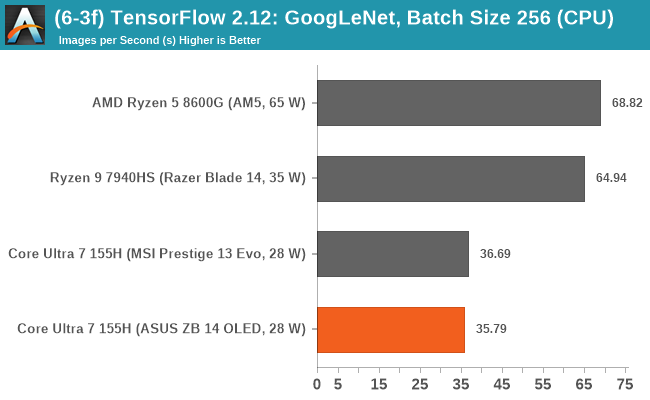
Looking at performance in our typical TensorFlow 2.12 inferencing benchmarks from our CPU suite, using both the VGG-16 and GoogLeNet models, we can see that the Intel Core Ultra 7 155H is no match for any of the AMD Phoenix-based chips.



Meanwhile, looking at inference performance on the hardware actually optimized for it – NPUs, and to a lesser extent, GPUs – UL's Procyon Computer Vision benchmark collection offers support for multiple execution backends, allowing it to be run on CPUs, GPUs, or NPUs. For Intel chips we're using the Intel OpenVINO backend, which enables access to Intel's NPU. Meanwhile AMD does not offer a custom execution backend for this test, so while Windows ML is available as a fallback option to access the CPU and the GPU, it does not have access to AMD's NPU.
With Meteor Lake's NPU active and running the INT8 version of the Procyon Computer Vision benchmarks, in Inception V4 and ResNet 50 we saw good gains in AI inferencing performance compared to using the CPU only. The Meteor Lake Arc Xe LPG graphics also did well, although the NPU is designed to be more power efficient with these workloads, and more often as not significantly outperforms the GPU at the same time.
This is just one test in a growing universe of NPU-accelerated appliations. But it helps to illustrate why hardware manufactuers are so interested in NPUs: they deliver a lot of performance for the power, at least as long as a workload is restricted enough that it can be run on an NPU.
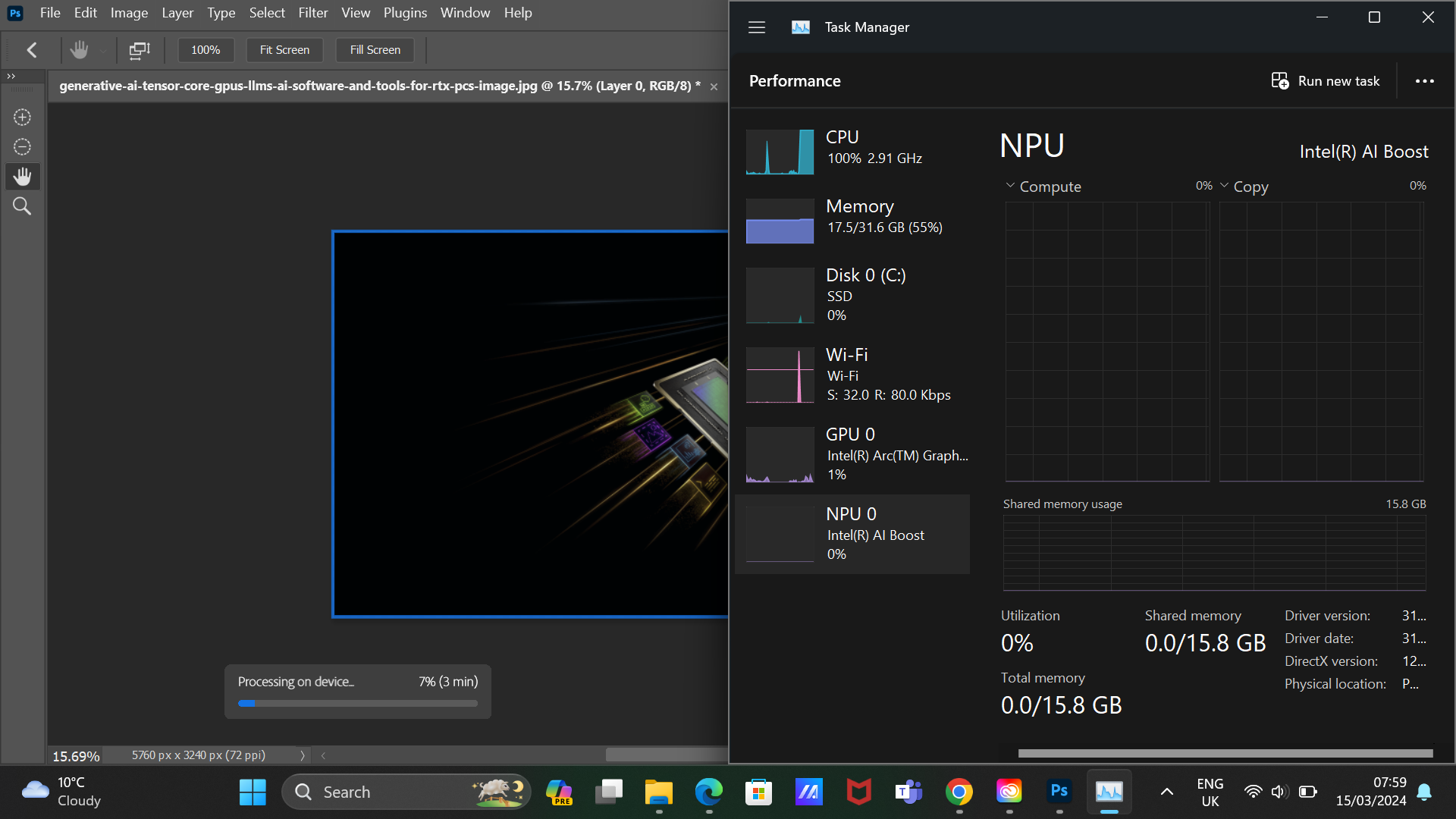
That all being said, even with the dedicated Intel AI Boost NPU within the SoC tile, the use case is very specific. Even trying generative AI within Adobe Photoshop using Neural fillers, Adobe was relying much more on the CPU than it was the GPU or the NPU, which shows that just because it's related to generative AI or inferencing, the NPU isn't always guaranteed to be used. This is still the very early days of NPUs, and even just benchmarking them for an active task remains an interesting challenge.








69 Comments
View All Comments
lmcd - Wednesday, April 17, 2024 - link
That GloFo combo for Zen 2 and 3 never made it to an efficient mobile platform (HX technically exists but whatever).Intel 4 is an incomplete node. Intel 3 had better fix a lot of the issues because at this point, Intel's best bet looks like an entirely-TSMC SoC. Reply
James5mith - Friday, April 12, 2024 - link
"Meanwhile AMD does not offer a custom execution backend for this test, so while Windows ML is available as a fallback option to access the CPU and the GPU, it does not have access to AMD's NPU."So why are there no graph entries for the AMD GPU using Windows ML? You only show CPU results in the graph. Seems a bit disingenuous. Reply
Tams80 - Friday, April 12, 2024 - link
This is really a rather pathetic comparison. YouTubers can get their hands on more devices for comparison than this.I get it. AnandTech is a dying publication that doesn't have the influence it used to, to get devices. And this also leads to particularly fluffy pieces to appease the few companies that do provide review units. Reply
The Von Matrices - Friday, April 12, 2024 - link
How can a PCIe 4.0 x2 disk have a read speed of 5GB/s? The bus only has a transfer rate of 4GB/s. Replyskavi - Saturday, April 13, 2024 - link
> Starting with the Redwood Cove (P) core cluster on the Core Ultra 7 155H, we can see that the core-to-core access latencies across the P-cores ranges from 4.5 to 4.9 ns, which is very similar to that of Raptor Lake via the Core i5-14600K, which sits between 4.6 and 4.9 ns; this indicates that both have the same P-core topology.By core to core, you mean intercore, right? or hyperthread to hyperthread?
> For the E-cores, the latencies shoot up to between 57.9 and 74.8 ns per each L1 access point, with the two first E-cores having a latency of just 5.0 ns.
Am I going crazy? It seems obvious to me those “two first E-cores” are a single P-core. Reply
jpvalverde85 - Tuesday, April 16, 2024 - link
AI compute capability is just there, then the big cores are just good enough against Zen4, the IGP just as strong on the best scenario (drivers can get the better out of it but still weak on some titles), now overall if we cut IA outside, Meteor Lake gets spanked badly by a gen old Ryzen. The good is that everything seems to work even coming in different tiles for being a tech demo, but i suspect that the BOM of the Ryzen 9 7940HS is lower being a monolithic 180mm2 design, Intel probably had to spent a lot of "glue" per mm2 of silicon. Replylmcd - Wednesday, April 17, 2024 - link
The glue might not be cheap but TSMC 6nm sure is, and 5nm isn't wildly expensive either.This Intel 4 tile though is clearly so far from finished. This is a horrifying showing for Intel Foundry's fab capabilities even if their packaging is clearly fantastic. And we are so overdue for the current larger cores to get dropped and the design roadmap for Atom forked into a large and small core. Reply
shady28 - Wednesday, April 17, 2024 - link
Like other mentioned, these aren't comparable products.That really shows up when you look at the battery life comparisons. The 155H has a 75W-H batter vs 69W-H on the 7940HS, 9% more capacity. Yet it lasts 95% longer in the rundown test.
That's going to show up in performance too.
HotHardware has a much better comparison, a 165H against comparable products like the 7736U and Z1 Extreme (30W TDP), as well as last gen RL 1365U (15W / 55 max).
The 165H had the longest battery life in their test of any machine tested, 1/3 more than the Z1 Extreme. Reply
kkilobyte - Wednesday, April 24, 2024 - link
Have the SPEC2017 tests been adapted? The text still says to this day that the results will be adapted when they are available. Reply